
Amazon Polly — это сервис, который превращает текст в реалистичную речь. Это позволяет разрабатывать целый класс приложений, которые могут преобразовывать текст в речь на нескольких языках.
Этот сервис может использоваться чат-ботами, аудиокнигами и другими приложениями для преобразования текста в речь в сочетании с другими сервисами AWS AI или машинного обучения (ML). Например, Amazon Lex и Amazon Polly можно объединить для создания чат-бота, который участвует в двустороннем разговоре с пользователем и выполняет определенные задачи на основе команд пользователя. Amazon Transcribe, Amazon Translate и Amazon Polly можно комбинировать для преобразования речи в текст на исходном языке, перевода на другой язык и произнесения на нем.
В этом посте мы представляем интересный подход к выделению текста при его произнесении с помощью Amazon Polly. Это решение можно использовать во многих приложениях для преобразования текста в речь, чтобы сделать следующее:
- Добавляйте визуальные возможности к аудио в книгах, на веб-сайтах и в блогах.
- Улучшайте понимание, когда клиенты пытаются быстро понять текст во время разговора.
Наше решение дает клиенту (в данном примере браузеру) возможность узнать, какой текст (слово или предложение) произносит Amazon Polly в любой момент. Это позволяет клиенту динамически выделять текст по мере его произнесения. Такая возможность полезна для предоставления визуальной помощи речи для случаев использования, упомянутых ранее.
Наше решение можно расширить для выполнения дополнительных задач помимо выделения текста. Например, браузер может отображать изображения, воспроизводить музыку или выполнять другие анимации во внешнем интерфейсе по мере произнесения текста. Эта возможность полезна для создания динамических аудиокниг, образовательного контента и приложений для преобразования текста в речь.
Обзор решения
По своей сути решение использует Amazon Polly для преобразования строки текста в речь. Текст можно ввести из браузера или с помощью вызова API к конечной точке, предоставляемой нашим решением. Речь, сгенерированная Amazon Polly, сохраняется в виде аудиофайла (в формате MP3) в корзине Amazon Simple Storage Service (Amazon S3).
Однако, используя только аудиофайл, браузер не может определить, какие части текста произносятся в любой момент, потому что у нас нет подробной информации о том, когда произносится каждое слово.
Amazon Polly предоставляет способ получить это с помощью речевых меток. Речевые метки хранятся в текстовом файле, который показывает время (измеряемое в миллисекундах с начала аудио), когда произносится каждое слово или предложение.
Amazon Polly возвращает объекты речевых меток в потоке JSON с разделителями строк. Объект речевой метки содержит следующие поля:
- Время – Отметка времени в миллисекундах с начала соответствующего аудиопотока
- Тип – Тип речевой метки (предложение, слово, визема или SSML)
- Начинать – Смещение в байтах (не символов) начала объекта во входном тексте (не включая метки виземы)
- Конец – Смещение в байтах (не символов) конца объекта во входном тексте (не включая метки виземы)
- Ценить – Это зависит от типа речевой метки:
- SSML – Тег SSML
- Визема – Название виземы
- Слово или предложение – Подстрока входного текста, разделенная начальным и конечным полями.
Например, предложение «У Мэри был ягненок» может дать вам следующий файл речевых меток, если вы используете SpeechMarkTypes = («слово», «предложение») в вызове API для получения речевых меток:
Слово «had» (в конце строки 3) начинается через 373 миллисекунды после начала аудиопотока, начинается с 5-го байта и заканчивается 8-м байтом входного текста.
Обзор архитектуры
Архитектура нашего решения представлена на следующей диаграмме.
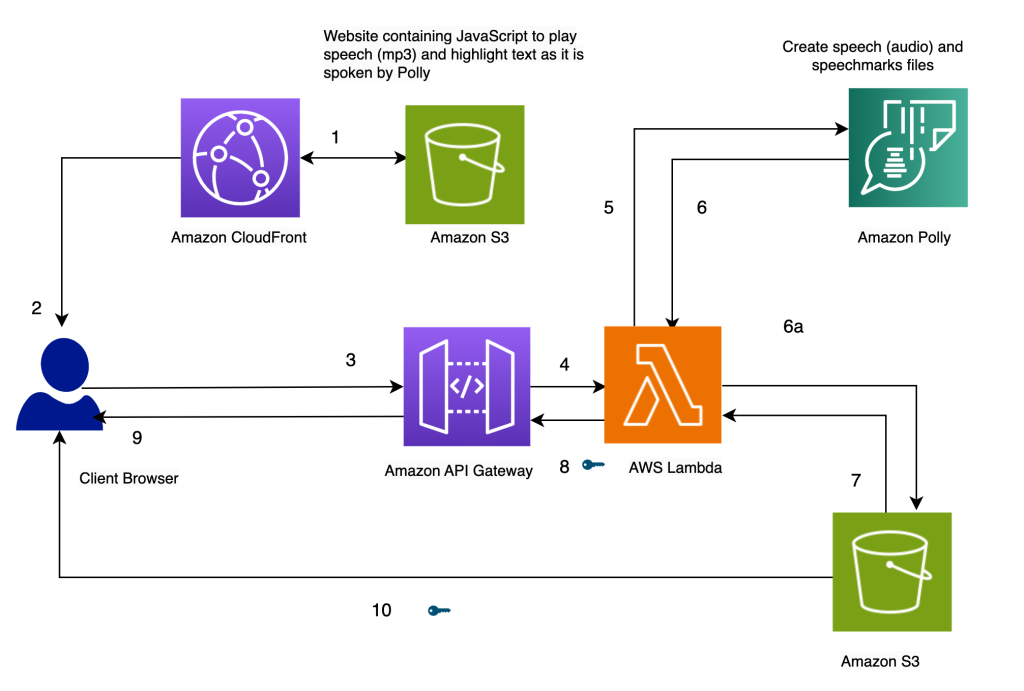
Выделяйте текст, когда он произносится, с помощью Amazon Polly
Наш веб-сайт для решения хранится на Amazon S3 в виде статических файлов (JavaScript, HTML), которые размещаются в Amazon CloudFront (1) и передаются в браузер конечного пользователя (2).
Когда пользователь вводит текст в браузере через простую HTML-форму, он обрабатывается JavaScript в браузере. Это вызывает API (3) через Amazon API Gateway, чтобы вызвать функцию AWS Lambda (4). Функция Lambda вызывает Amazon Polly (5) для создания файлов речи (аудио) и речевых меток (JSON). В Amazon Polly выполняются два вызова для получения файлов аудио и речевых меток. Вызовы выполняются с использованием асинхронных функций JavaScript. Результатом этих вызовов являются файлы звуковых и речевых меток, которые хранятся в Amazon S3 (6a). Чтобы несколько пользователей не перезаписывали файлы друг друга в корзине S3, файлы хранятся в папке с отметкой времени. Это сводит к минимуму вероятность того, что два пользователя перезапишут файлы друг друга в Amazon S3. Для рабочей версии мы можем использовать более надежные подходы для разделения файлов пользователей на основе идентификатора пользователя или временной метки и других уникальных характеристик.
Функция Lambda создает предварительно подписанные URL-адреса для файлов речи и речевых меток и возвращает их в браузер в виде массива (7, 8, 9).
Когда браузер отправляет текстовый файл в конечную точку API (3), он возвращает два предварительно подписанных URL-адреса для аудиофайла и файла речевых меток за один синхронный вызов (9). На это указывает символ ключа рядом со стрелкой.
Функция JavaScript в браузере извлекает файл речевых меток и аудио из их дескрипторов URL (10). Он настраивает аудиоплеер для воспроизведения звука. (Для этой цели используется HTML-тег audio).
Когда пользователь нажимает кнопку воспроизведения, он анализирует речевые метки, полученные на предыдущем шаге, чтобы создать серию синхронизированных событий с использованием тайм-аутов. События вызывают функцию обратного вызова, которая является еще одной функцией JavaScript, используемой для выделения произносимого текста в браузере. Одновременно функция JavaScript передает аудиофайл из своего дескриптора URL.
В результате события запускаются в нужное время, чтобы выделить текст по мере его произнесения во время воспроизведения звука. Использование тайм-аутов JavaScript обеспечивает синхронизацию звука с выделенным текстом.
Предпосылки
Для запуска этого решения вам потребуется учетная запись AWS с пользователем AWS Identity and Access Management (IAM), у которого есть разрешение на использование Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda и AWS Step Functions.
Используйте Lambda для генерации речи и речевых меток
Следующий код вызывает Amazon Polly synthesize_speech два раза, чтобы получить файл аудио и речевых меток. Они запускаются как асинхронные функции и координируются для одновременного возврата результата с помощью промисов.
На стороне JavaScript выделение текста выполняется с помощью маркера (начало, конец, слово), а временные события устанавливаются с помощью setTimers():
Альтернативные подходы
Вместо предыдущего подхода вы можете рассмотреть несколько альтернатив:
- Создайте как речевые метки, так и аудиофайлы внутри конечного автомата Step Functions. Конечный автомат может вызвать условие параллельного перехода, чтобы вызвать две разные функции Lambda: одну для генерации речи, а другую для генерации речевых меток. Код для этого можно найти в использование пошаговых функций подпапка в репозитории Github.
- Вызовите Amazon Polly асинхронно для создания звуковых и речевых меток. Этот подход можно использовать, если текстовое содержимое большое или пользователю не нужен ответ в реальном времени. Дополнительные сведения о создании длинных аудиофайлов см. в разделе Создание длинных аудиофайлов.
- Попросите Amazon Polly создать предварительно подписанный URL-адрес напрямую, используя
generate_presigned_urlвызов клиента Amazon Polly в Boto3. Если вы выберете этот подход, Amazon Polly каждый раз будет создавать новые звуковые и речевые метки. В нашем текущем подходе мы храним эти файлы в Amazon S3. Хотя в нашей версии кода эти сохраненные файлы недоступны из браузера, вы можете изменить код для воспроизведения ранее созданных аудиофайлов, загрузив их из Amazon S3 (вместо повторного создания аудио для текста с помощью Amazon Polly). У нас есть другие примеры кода для доступа к Amazon Polly с помощью Python в библиотеке кода AWS.
Создать решение
Полное решение доступно у нас Репозиторий Github. Чтобы создать это решение в своей учетной записи, следуйте инструкциям в файле README.md. Решение включает шаблон AWS CloudFormation для предоставления ваших ресурсов.
Очистка
Чтобы очистить ресурсы, созданные в этой демонстрации, выполните следующие действия:
- Удалите сегменты S3, созданные для хранения шаблона CloudFormation (сегмент A), исходного кода (сегмент B) и веб-сайта (
pth-cf-text-highlighter-website-(Suffix)). - Удалить стек CloudFormation
pth-cf. - Удалите корзину S3, содержащую речевые файлы (
pth-speech-(Suffix)). Этот сегмент был создан шаблоном CloudFormation для хранения файлов звуковых и речевых меток, созданных Amazon Polly.
Краткое содержание
В этом посте мы показали пример решения, которое может выделять текст во время его произнесения с помощью Amazon Polly. Он был разработан с использованием функции речевых меток Amazon Polly, которая предоставляет нам маркеры для места начала каждого слова или предложения в аудиофайле.
Решение доступно в виде шаблона CloudFormation. Его можно развернуть как есть в любом веб-приложении, выполняющем преобразование текста в речь. Это было бы полезно для добавления визуальных возможностей к аудио в книгах, аватарах с возможностью синхронизации губ (с использованием речевых меток визем), веб-сайтов и блогов, а также для помощи людям с нарушениями слуха.
Его можно расширить для выполнения дополнительных задач помимо выделения текста. Например, браузер может отображать изображения, воспроизводить музыку и выполнять другие анимации во внешнем интерфейсе во время произнесения текста. Эта возможность может быть полезна для создания динамических аудиокниг, образовательного контента и более богатых приложений для преобразования текста в речь.
Мы приглашаем вас попробовать это решение и узнать больше о соответствующих сервисах AWS по следующим ссылкам. Вы можете расширить функциональность для ваших конкретных потребностей.
об авторе
 Варад Г Варадараджан является доверенным консультантом и полевым техническим директором для клиентов Digital Native Businesses (DNB) в AWS. Он помогает им разрабатывать и создавать инновационные масштабные решения с использованием продуктов и сервисов AWS. Сферы интересов Варада включают консультирование по ИТ-стратегии, архитектуру и управление продуктами. Вне работы Варад любит писать, смотреть фильмы с семьей и друзьями и путешествовать.
Варад Г Варадараджан является доверенным консультантом и полевым техническим директором для клиентов Digital Native Businesses (DNB) в AWS. Он помогает им разрабатывать и создавать инновационные масштабные решения с использованием продуктов и сервисов AWS. Сферы интересов Варада включают консультирование по ИТ-стратегии, архитектуру и управление продуктами. Вне работы Варад любит писать, смотреть фильмы с семьей и друзьями и путешествовать.