
| DeepTech")
Я решил пройтись по некоторым прорывным статьям в области НЛП (обработка естественного языка) и подытожить свои знания. Документы датируются периодом с начала 2000-х по 2018 год.
 |
| Источник – KDNuggets |
Если вы совсем новичок в области НЛП – рекомендую начать с прочтения Эта статья который затрагивает различные основы НЛП.
1. Нейронно-вероятностная языковая модель
2. Эффективная оценка представлений слов в векторном пространстве
Word2Vec — модель скипграммы
3. Распределенные представления слов и фраз и их композиционно
4. GloVe: глобальные векторы для представления слов
5. Языковая модель на основе рекуррентной нейронной сети
6. Расширения языковой модели рекуррентной нейронной сети
Начнем с №1,
Модель нейронно-вероятностного языка
Бенжио и др. предложить распределенное представление слов для борьбы с проклятием размерности.
Проклятие размерности проистекает из использования векторного представления одного слова, равного размеру словаря, и изучения расстояния одного слова по отношению ко всем словам.
Например, чтобы смоделировать совместное распределение 10 последовательных слов с размером словаря 100 000, необходимо изучить 10 параметров.50-1.
Язык можно статистически смоделировать, чтобы представить условную вероятность следующего слова с учетом всех предыдущих слов из корпуса (в пределах окна):

Авторы отмечают, что большинство предшествующих методов языкового моделирования страдают тем, что они не учитывают «подобие» между словами и фокусируются на временном местоположении.

Это помогает узнать семантическое и грамматическое сходство между словами и помогает лучше обобщать.
Чтобы узнать совместную функцию вероятности последовательностей слов, авторы предлагают подход, основанный на нейронной сети:

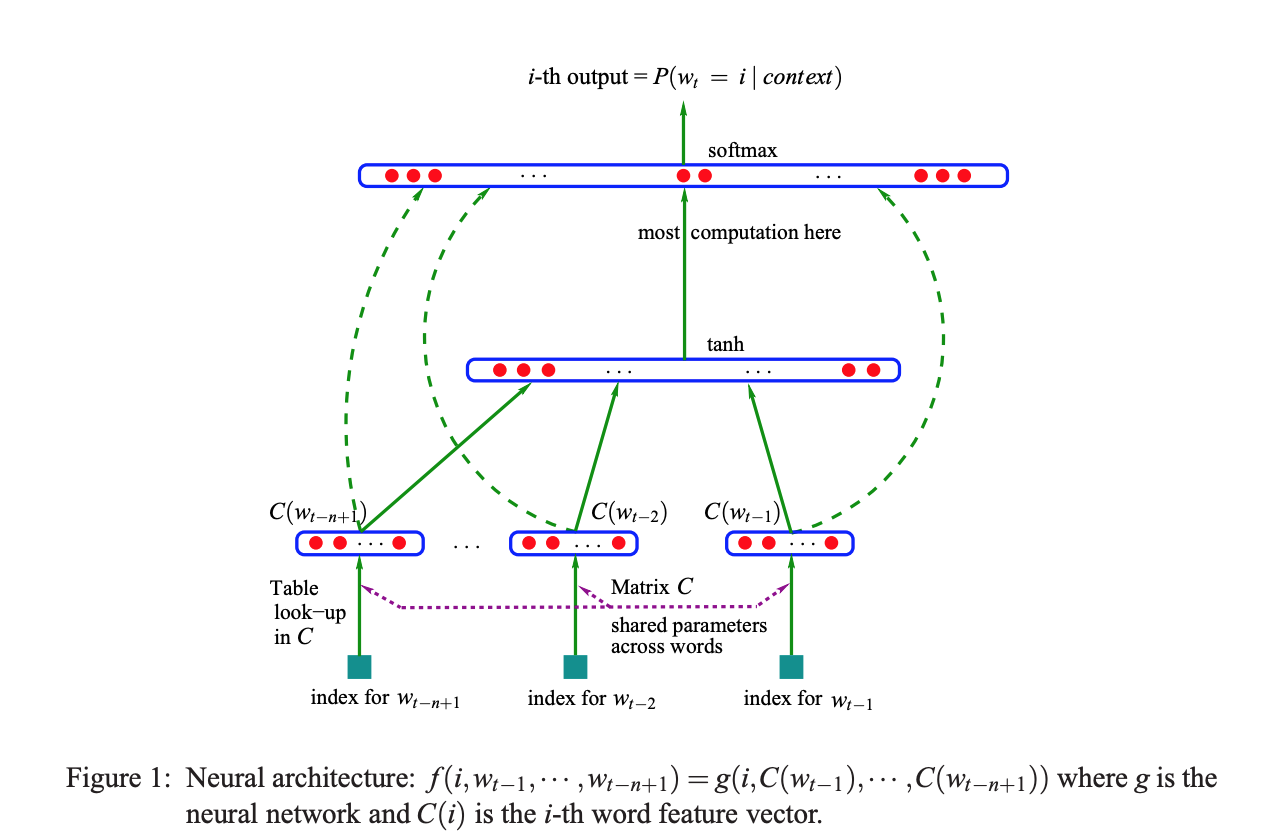
Основная цель обучения здесь состоит из двух частей, каждая из которых происходит в унисон и усиливает друг друга:
1. Выучите распределенное представление C для предыдущих (контекстных) слов, которое означает сходство. (линейная проекция)
2. Предсказать правильное следующее слово, учитывая окно предыдущих слов (размер окна равен n для моделей с n-граммами — нелинейный скрытый слой, используемый для изучения совместных вероятностей в данном контексте).

Примечание. Убыток называется «штрафным» из-за наличия условия регуляризации. Кроме того, функция активации, используемая в этой архитектуре, представляет собой коричневую гиперболическую нелинейность.
Позже мы узнаем, что даже нелинейные модели, используемые для языковых моделей, имеют тенденцию изучать линейные (или близкие к линейным представления) неявно.
В заключение авторы говорят, что языковые модели на основе нейронных сетей значительно превосходят своего предшественника — модель N-грамм.
Эффективная оценка представлений слов в векторном пространстве
Проблема с моделью на основе нейронной сети (NLM) заключается в ее масштабируемости на огромных наборах данных, содержащих миллиарды слов. Авторы – Миколов и др. др. попробуйте решить его с помощью альтернативной схемы.
Где NLM пытался обучить модель сходству контекста/слова. Авторы этой статьи отмечают, что слова могут иметь несколько степеней сходства, и для выражения этого можно использовать векторы слов.
Например —
вектор(“Король”) – вектор(“Мужчина”) + вектор(“Женщина”) приближает вас к вектору(“Королева”).
Языковые модели могут изучать неявные значения, такие как пол и семантические отношения между ними.
Ограничением NLM является фиксированный размер окна контекста, это ограничение можно устранить с помощью рекуррентной нейронной сети для языкового моделирования (RNNLM). Они также демонстрируют форму кратковременной памяти, которую можно использовать для выборочного запоминания/забывания последовательностей, которые могут быть важны для последующего предсказания.
Наблюдения, представленные авторами, заключаются в том, что большая часть сложности в этих моделях вызвана нелинейными активациями скрытого слоя. Авторы предлагают 2 архитектуры:

1. CBOW (непрерывная модель мешка слов)
- Это очень похоже на NLM. Однако нелинейный скрытый слой удаляется, а слой проекции используется всеми словами.
- По сравнению с NLM мы находим функцию C (Projection Matrix), которая проецирует каждое из контекстных слов, и мы усредняем их вместе, чтобы найти целевое слово (Shared используется в том смысле, что векторы усредняются).
- При таком подходе порядок слов не важен. Сходство и масштабируемость имеют большее значение.
2. Непрерывная модель Skip-gram
Архитектура обратна CBoW — по целевому слову мы предсказываем контекстные слова. Увеличение диапазона (t+/-n) улучшает качество векторов слов, но увеличивает вычислительную сложность.
Авторы эмпирически показывают, что обе эти модели лучше, чем NLM, справляются с синтаксическими и семантическими задачами.
Распределенные представления слов и фраз и их композиционно
Это продолжение работы Миколова и др. др. в котором предлагаются методы улучшения CBoW и модели Skip-Gram, представленные в последней статье.
Идея обеих предыдущих моделей состоит в том, чтобы изучить качественные представления слов, выполнив другую задачу (или подзадачу) в целом. В случае Skip-gram это предсказать близлежащие слова.


Целью модели Skip Gram является:
1. Максимизируйте условную вероятность предсказания следующего слова, учитывая все предыдущие слова.
2. Максимизируйте скалярное произведение (косинусное расстояние) между двумя векторами – целевым вектором w
ограничение модели Skip-Gram следует из уравнения № 2, где мы делаем этот огромный softmax для всего словаря. Это дает нам временную сложность O(|V|), где V — размер словаря.
- Авторы предлагают использовать Иерархический Софтмакс что снижает временную сложность до log(|V|), поскольку представляет softmax в подходе, основанном на двоичном дереве.
- Далее авторы обсуждают другую технику, называемую Отрицательная выборка который вдохновлен шумовой контрастной оценкой (NCE). Это способ явного увеличения расстояния между некоррелированными словами.
Еще одна интересная техника, представленная в статье, Подвыборка часто используемых слов. Идея состоит в том, чтобы выборочно обучить сеть тому, какие слова встречаются реже. Например, обучение сети с помощью таких пар слов, как «the» и любое существительное, на самом деле не помогает сети чему-либо научиться. Идея состоит в том, чтобы сформировать пары уникальных и менее часто встречающихся слов, которые помогут изучить встроенные сходства, такие как «Пары» и «Франция» (цель и контекст или взаимозаменяемо).
Подвыборка значительно повышает точность и скорость обучения.
Все эти методы сохраняют линейный аддитивный характер векторов, изученных Skip-Gram, и в то же время улучшают масштабируемость и точность.
GloVe: глобальные векторы для представления слов
Все предыдущие рассмотренные модели учитывают непосредственный контекст (соседние слова) для предсказания цели или контекста.
В этой статье Pennington et. др. предложить технику, которая берет лучшее из обоих миров –
1. Global Matrix Factorization (Глобальная статистика корпуса текстов)
2. Методы локального контекстного окна (Skip-gram, CBoW, Neural LM)
Такие методы, как skip-gram, не используют глобальное количество совпадений слов. Авторы отмечают, что простые модели, такие как Skip-Gram, которые используют простую одноуровневую архитектуру, основанную на скалярном произведении между двумя векторами слов, как правило, работают лучше, чем архитектуры нейронных сетей. Однако эти методы локального контекстного окна не используют преимуществ огромного количества корреляций между словами, если рассматривать их как целый корпус.

Чтобы лучше объяснить эту таблицу, давайте посмотрим на представленные обозначения:

Глядя на Таблицу 1: Для слов, относящихся ко льду, но не к пару, отношение будет большим (как видно для твердого тела). Однако для слов, связанных с паром, но не со льдом, соотношение будет небольшим. Для слов, не связанных ни с тем, ни с другим, отношение будет близко к 1. Это говорит нам о том, что глобальная статистика огромных корпусов может влиять на «сходство».
Модель GloVE работает намного лучше, чем улучшенная модель Skip gram и CBoW, как показано в результатах этой статьи.
Я также хотел бы кратко обсудить пару статей о языковых моделях на основе RNN, это скорее расширение NNLM от Bengio et. все (1). Это могут быть не самые эффективные языковые модели, но они обеспечивают отличное понимание из-за их краткосрочной разговорной памяти.
Языковая модель на основе рекуррентной нейронной сети (RNNLM)
Возвращаясь к цели, с которой мы начали, языковые модели должны иметь возможность последовательно предсказывать следующие слова.

Основное преимущество использования RNNLM заключается в том, что они имеют собственное скрытое состояние/контекст, подобное кратковременной памяти. При использовании рекуррентных сетей информация может циклически перемещаться внутри сети в течение сколь угодно долгого времени (как известно сети) и не ограничивается окном.

1. Текущим входом в сеть является слово в текущий момент времени w
2. RNN использует 2 разные нелинейности, первая из которых представляет собой сигмовидную, чтобы охватить информацию для контекста/скрытого состояния.
2. Softmax для обеспечения вероятностного вывода следующего слова. Это V-образный софтмакс.
Авторы также обсуждают использование динамического обучения во время тестирования, которое помогает сети лучше изучить использование памяти для тестирования и предоставляет динамические результаты на лету.
Дополнением к этому является другая статья Миклова и др. др. называется:
Расширения рекуррентной сетевой модели нейронного языка
В этой статье авторы (Миклов и др.) предлагают дальнейшее улучшение точности предыдущей модели RNN с помощью концепции обратного распространения во времени (BTT). Они также видят несколько трюков, чтобы улучшить ускорение и уменьшить количество параметров.
Я призываю вас прочитать эти статьи и написать в комментариях, если у вас есть вопросы 🙂
Пожалуйста, дайте мне знать, если я пропустил какие-либо другие важные документы здесь.