
Обучение с подкреплением обеспечивает концептуальную основу для автономных агентов, чтобы они могли учиться на собственном опыте, аналогично тому, как можно дрессировать домашнее животное с помощью лакомств. Но практическое применение обучения с подкреплением часто далеко от естественного: вместо того, чтобы использовать RL для обучения методом проб и ошибок, фактически пытаясь выполнить желаемую задачу, типичные приложения RL используют отдельную (обычно смоделированную) фазу обучения. Например, АльфаГо научился играть в го не соревнуясь с тысячами людей, а играя сам с собой в симуляции. В то время как этот вид симуляции обучения привлекателен для игр, в которых правила хорошо известны, его применение в областях реального мира, таких как робототехника, может потребовать ряда сложных подходов, таких как использование смоделированных данных, или инструментирование реальных сред различными способами, чтобы сделать обучение возможным в лабораторных условиях. Можем ли мы вместо этого разработать системы обучения с подкреплением для роботов, которые позволят им учиться непосредственно «на рабочем месте», выполняя задачу, которую они должны выполнять? В этом сообщении блога мы обсудим ReLMM, разработанную нами систему, которая учится убирать комнату непосредственно с настоящим роботом посредством непрерывного обучения.




Мы оцениваем наш метод на различных задачах различной сложности. В верхнем левом задании есть однородные белые пятна, которые можно подобрать без препятствий, в то время как в других комнатах есть объекты разных форм и цветов, препятствия, которые усложняют навигацию и скрывают объекты, и узорчатые коврики, которые мешают видеть объекты на фоне земли.
Чтобы обеспечить обучение «на рабочем месте» в реальном мире, сложность накопления большего количества опыта непомерно высока. Если мы сможем упростить обучение в реальном мире, сделав процесс сбора данных более автономным, не требуя наблюдения или вмешательства человека, мы сможем извлечь дополнительные выгоды из простоты агентов, которые учатся на собственном опыте. В этой работе мы разрабатываем систему обучения мобильного робота «на рабочем месте» для уборки, учась хватать предметы в разных комнатах.
Люди не рождаются сегодня, а завтра проходят собеседования. Есть много уровней задач, которые люди изучают, прежде чем подавать заявление о приеме на работу, поскольку мы начинаем с более простых и развиваем их. В ReLMM мы используем эту концепцию, позволяя роботам тренировать общие многократно используемые навыки, такие как хватание, сначала поощряя робота расставлять приоритеты в обучении этим навыкам, прежде чем изучать более поздние навыки, такие как навигация. Обучение таким образом имеет два преимущества для робототехники. Первое преимущество заключается в том, что когда агент фокусируется на изучении навыка, он более эффективно собирает данные о распределении локального состояния для этого навыка.
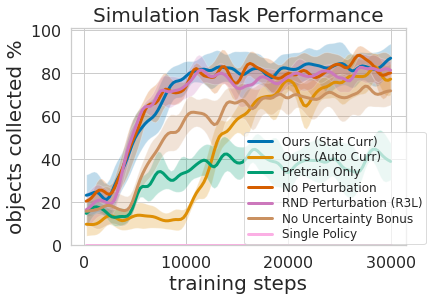
Это показано на рисунке выше, где мы оценили количество приоритетного опыта хватания, необходимого для эффективного обучения манипулированию мобильными устройствами. Второе преимущество многоуровневого подхода к обучению заключается в том, что мы можем проверять модели, обученные для различных задач, и задавать им вопросы, например, «можете ли вы понять что-нибудь прямо сейчас», что полезно для обучения навигации, которое мы опишем далее.
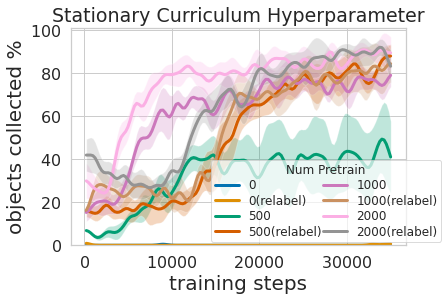
Обучение этой многоуровневой политике было не только более эффективным, чем одновременное обучение обоим навыкам, но и позволяло хватающему контроллеру информировать о политике навигации. Имея модель, которая оценивает неопределенность в ее достижении успеха (Наш выше) можно использовать для улучшения навигационного исследования, пропуская области без захватываемых объектов, в отличие от Бонус за отсутствие неопределенности который не использует эту информацию. Модель также можно использовать для перемаркировки данных во время обучения, чтобы в неудачном случае, когда модель захвата не пыталась схватить объект в пределах досягаемости, политика захвата все же могла дать некоторый сигнал, указывая, что объект был там, но захват политика еще не научилась его понимать. Более того, изучение модульных моделей имеет инженерные преимущества. Модульное обучение позволяет повторно использовать навыки, которые легче освоить, и позволяет создавать интеллектуальные системы по частям. Это выгодно по многим причинам, включая оценку и понимание безопасности.
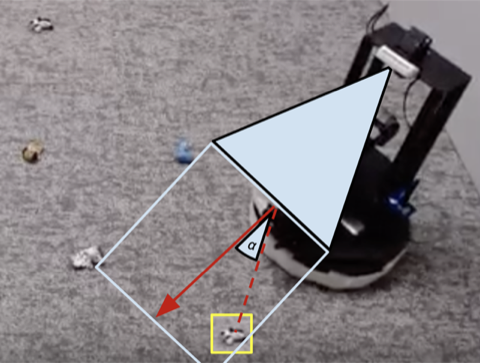
Многие задачи робототехники, которые мы видим сегодня, могут быть решены с разным уровнем успеха с использованием контроллеров, спроектированных вручную. Для нашей задачи по уборке помещения мы разработали ручной контроллер, который находит объекты с помощью кластеризации изображений и поворачивается к ближайшему обнаруженному объекту на каждом этапе. Этот профессионально разработанный контроллер очень хорошо работает на визуально заметных скрученных носках и обходит препятствия по разумным траекториям. но он не может найти оптимальный путь для быстрого сбора объектов и борется с визуально разнообразными комнатами.. Как показано в видео 3 ниже, заскриптованная политика отвлекается на ковер с белым узором, пытаясь найти больше белых объектов, которые можно схватить.
1) 
2) 
3) 
4) 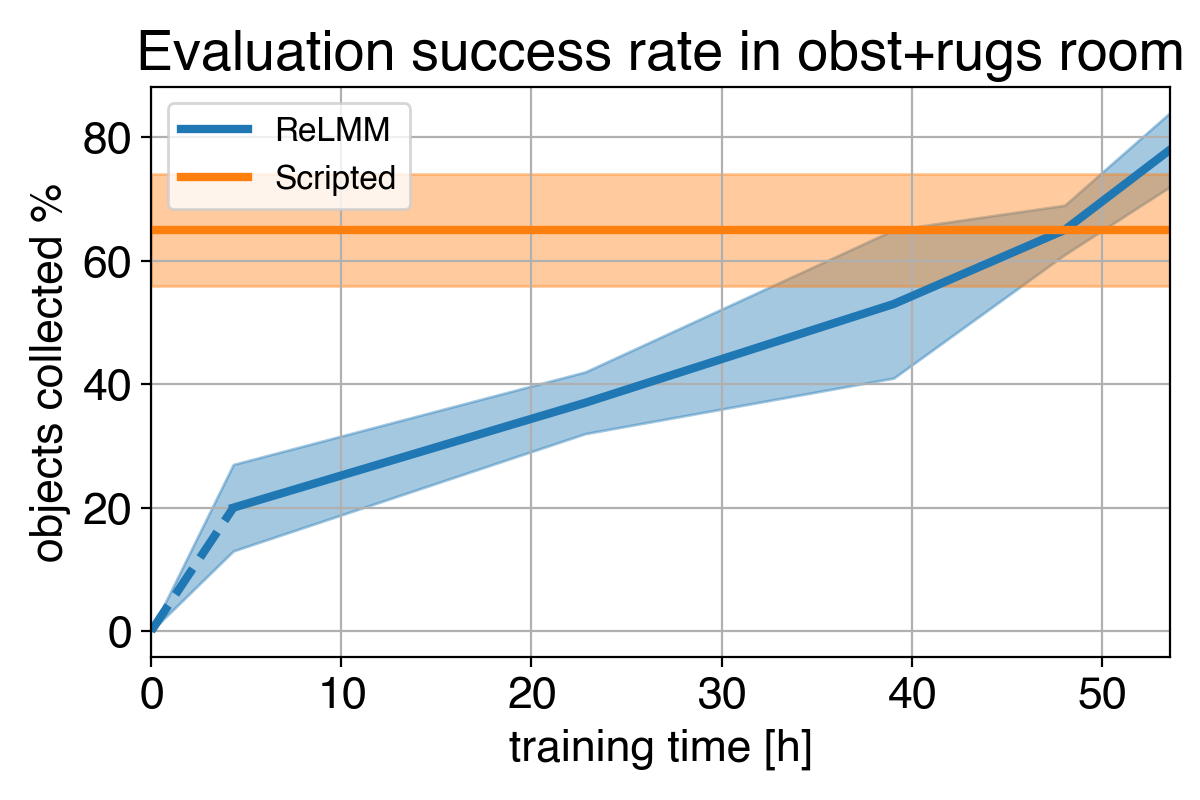
Мы показываем сравнение между (1) нашей политикой в начале обучения (2) нашей политикой в конце обучения (3) политикой по сценарию. В (4) мы видим, что производительность робота со временем улучшается и, в конечном итоге, превышает запрограммированную политику при быстром сборе объектов в комнате.
Учитывая, что мы можем использовать экспертов для кодирования этого контроллера ручной работы, какова цель обучения? Важным ограничением ручных контроллеров является то, что они настроены на конкретную задачу, например, на захват белых предметов. Когда вводятся разнообразные объекты, отличающиеся по цвету и форме, первоначальная настройка может уже не быть оптимальной. Наш метод, основанный на обучении, не требует дополнительной ручной работы, он может адаптироваться к различным задачам, собирая собственный опыт.
Однако самый важный урок заключается в том, что даже если контроллер, сконструированный вручную, способен, обучающийся агент в конечном итоге превосходит его по прошествии достаточного времени. Этот процесс обучения сам по себе является автономным и происходит, пока робот выполняет свою работу, что делает его сравнительно недорогим. Это показывает возможности агентов обучения, которые также можно рассматривать как разработку общего способа выполнения процесса «экспертной ручной настройки» для любого вида задач. У обучающихся систем есть возможность создать весь алгоритм управления роботом, а не ограничиваться настройкой нескольких параметров в скрипте. Ключевой шаг в этой работе позволяет этим реальным системам обучения автономно собирать данные, необходимые для обеспечения успеха методов обучения.
Этот пост основан на документе «Полностью автономное обучение с подкреплением в реальном мире с приложениями для мобильных манипуляций», представленном на CoRL 2021. Более подробную информацию вы можете найти в наша газетана нашей Веб-сайт и на видео. Мы предоставляем код воспроизвести наши эксперименты. Мы благодарим Сергея Левина за его ценный отзыв об этом сообщении в блоге.