
TL;DR: Текстовая подсказка -> LLM -> Промежуточное представление (например, макет изображения) -> Стабильная диффузия -> Изображение.
Недавние достижения в преобразовании текста в изображение с помощью моделей распространения дали замечательные результаты, синтезируя очень реалистичные и разнообразные изображения. Однако, несмотря на впечатляющие возможности, диффузионные модели, такие как Стабильная диффузиячасто пытаются точно следовать подсказкам, когда требуется пространственное или здравое мышление.
На следующем рисунке перечислены четыре сценария, в которых Stable Diffusion не дает возможности генерировать изображения, которые точно соответствуют заданным подсказкам, а именно отрицание, умение считатьи назначение атрибута, пространственные отношения. В отличие от нашего метода, ллМ-заземлен Дразлив (ЛМД), обеспечивает гораздо лучшее быстрое понимание при преобразовании текста в изображение в этих сценариях.

Рис. 1. Диффузия на основе LLM повышает способность к быстрому пониманию моделей диффузии текста в изображение.
Одним из возможных решений этой проблемы, конечно же, является сбор обширного мультимодального набора данных, включающего сложные подписи, и обучение большой модели распространения с помощью большого языкового кодировщика. Этот подход связан со значительными затратами: обучение как больших языковых моделей (LLM), так и моделей распространения требует много времени и средств.
Наше решение
Чтобы эффективно решить эту проблему с минимальными затратами (т. е. без затрат на обучение), вместо этого мы оснастить модели диффузии расширенными пространственными рассуждениями и здравым смыслом, используя готовые замороженные LLM в новом двухэтапном процессе генерации.
Во-первых, мы адаптируем LLM как генератор макетов с текстовым управлением посредством контекстного обучения. При наличии подсказки изображения LLM выводит макет сцены в виде ограничивающих рамок вместе с соответствующими отдельными описаниями. Во-вторых, мы управляем моделью распространения с помощью нового контроллера для создания изображений, зависящих от макета. На обоих этапах используются замороженные предварительно обученные модели без какой-либо оптимизации параметров LLM или диффузионной модели. Приглашаем читателей на прочитать статью на arXiv для получения дополнительной информации.
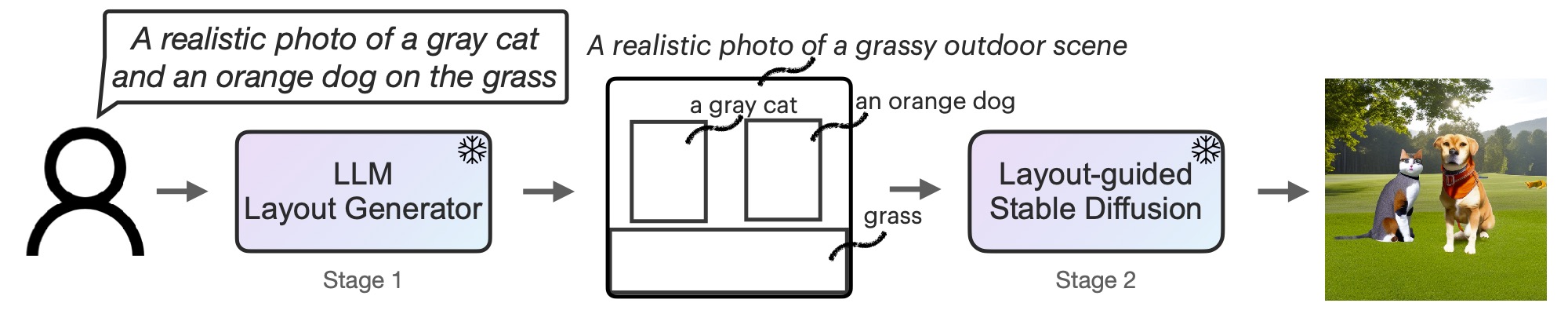
Рис. 2. LMD — это генерирующая модель преобразования текста в изображение с новым двухэтапным процессом генерации: генератор преобразования текста в макет с LLM + контекстное обучение и новая стабильная диффузия, управляемая макетом. Оба этапа не требуют обучения.
Дополнительные возможности LMD
Кроме того, LMD, естественно, позволяет Спецификация многораундовой сцены на основе диалога, позволяя дополнительные пояснения и последующие модификации для каждой подсказки. Кроме того, LMD может обрабатывать подсказки на языке, который плохо поддерживается базовой моделью распространения.

Рисунок 3. Включая LLM для быстрого понимания, наш метод может выполнять спецификацию сцены на основе диалога и генерировать запросы на языке (китайский в приведенном выше примере), который не поддерживает базовая модель распространения.
При наличии LLM, который поддерживает многоэтапный диалог (например, GPT-3.5 или GPT-4), LMD позволяет пользователю предоставлять LLM дополнительную информацию или пояснения, запрашивая LLM после первого создания макета в диалоговом окне и генерируя изображения с обновленный макет в последующем ответе от LLM. Например, пользователь может запросить добавление объекта на сцену или изменить существующие объекты в расположении или описании (левая половина рис. 3).
Кроме того, предоставляя пример неанглоязычной подсказки с макетом и фоновым описанием на английском языке во время обучения в контексте, LMD принимает входные данные неанглоязычных подсказок и создает макеты с описаниями полей и фоном на английском языке для последующего обучения. генерация макета в изображение. Как показано в правой половине рис. 3, это позволяет генерировать запросы на языке, который не поддерживают базовые модели распространения.
Визуализации
Мы подтверждаем превосходство нашей конструкции, сравнивая ее с базовой диффузионной моделью (SD 2.1), которую LMD использует под капотом. Мы приглашаем читателей к нашей работе для большего количества оценок и сравнений.
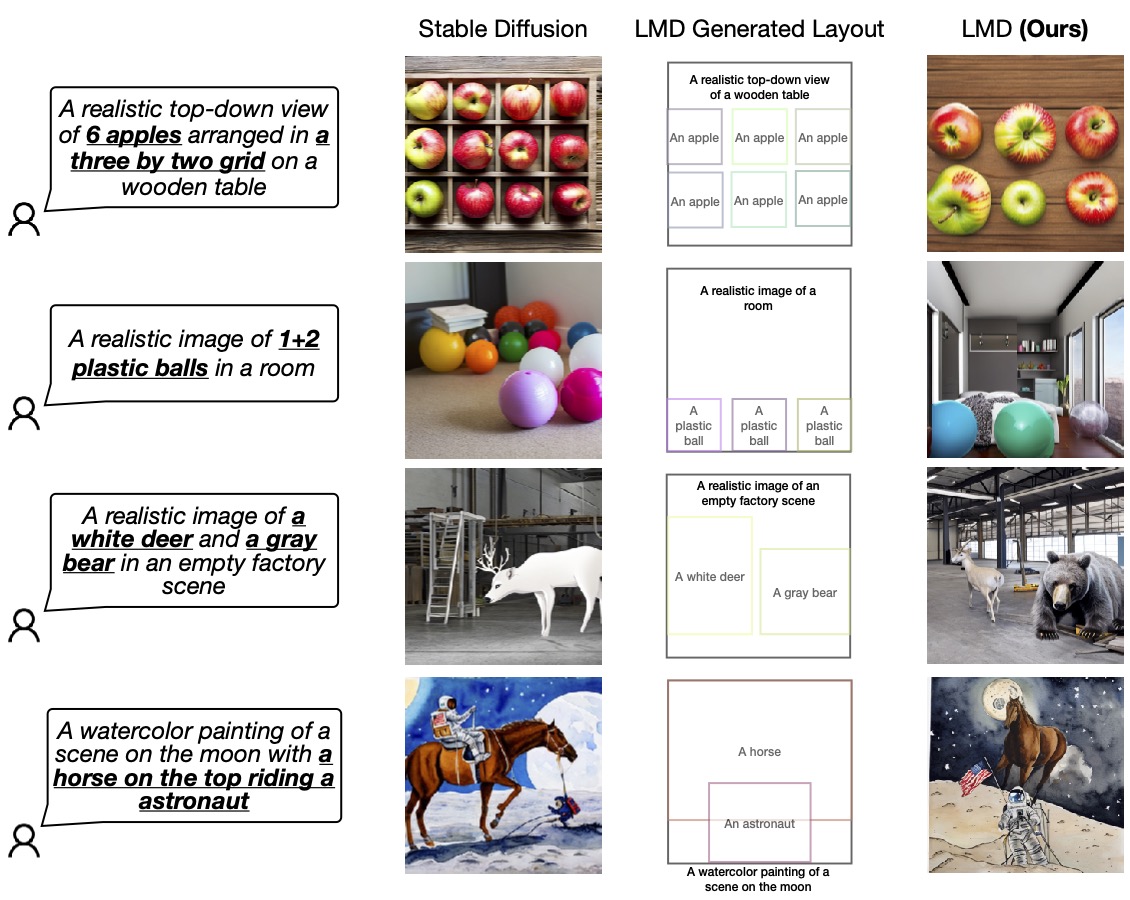
Рисунок 4: LMD превосходит базовую модель диффузии в точном создании изображений в соответствии с подсказками, которые требуют как языкового, так и пространственного мышления. LMD также позволяет генерировать контрфактическое преобразование текста в изображение, которое базовая модель диффузии не может генерировать (последняя строка).
Дополнительные сведения о диффузии с заземлением LLM (LMD) см. посетите наш сайт и прочитать статью на arXiv.
БибТекс
Если LLM-grounded Diffusion вдохновляет вашу работу, цитируйте его:
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
author={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
year={2023}
}