
Фон
Грубая детализация уменьшает размерность проблемы, позволяя использовать условную авторегрессионную генерацию, а не генерировать все координаты независимо, как это делалось в предыдущей работе. Путем прямого обусловливания трехмерных координат ранее сгенерированных подграфов наша модель лучше обобщает химически и пространственно схожие подграфы. Это имитирует основной процесс молекулярного синтеза, когда небольшие функциональные единицы соединяются вместе, образуя большие молекулы, подобные лекарствам. В отличие от предыдущих методов, CoarsenConf генерирует низкоэнергетические конформеры с возможностью прямого моделирования атомных координат, расстояний и торсионных углов.
Архитектуру CoarsenConf можно разбить на следующие компоненты:
(Я) Кодировщик $q_\phi(z| X, \mathcal{R})$ принимает мелкозернистый (FG) конформер истинности основания $X$, приближенный конформер RDKit $\mathcal{R}$ и крупнозернистый (CG ) конформер $\mathcal{C}$ в качестве входных данных (полученный из $X$ и предопределенной стратегии CG) и выводит эквивариантное представление CG переменной длины посредством эквивариантной передачи сообщений и точечных сверток.
(II) Эквивариантные MLP применяются для изучения среднего значения и логарифмической дисперсии как апостериорного, так и априорного распределения.
(III) Апостериорная (обучение) или предшествующая (вывод) выборка и подача в модуль выбора канала, где уровень внимания используется для изучения оптимального пути от структуры CG к структуре FG.
(IV) Учитывая скрытый вектор FG и приближение RDKit, декодер $p_\theta(X |\mathcal{R}, z)$ учится восстанавливать низкоэнергетическую структуру FG посредством авторегрессионной эквивариантной передачи сообщений. Всю модель можно обучить от начала до конца, оптимизируя KL-расхождение скрытых распределений и ошибку реконструкции сгенерированных конформеров.
Формализм задач MCG
Мы формализуем задачу генерации молекулярного конформера (MCG) как моделирование условного распределения $p(X|\mathcal{R})$, где $\mathcal{R}$ — приближенный конформер, сгенерированный RDKit, а $X$ — оптимальный низкоэнергетический конформер(ы). RDKit, широко используемая библиотека хеминформатики, использует дешевый алгоритм, основанный на геометрии расстояния, за которым следует недорогая оптимизация, основанная на физике, для достижения разумных приближений конформеров.
Крупнозернистый
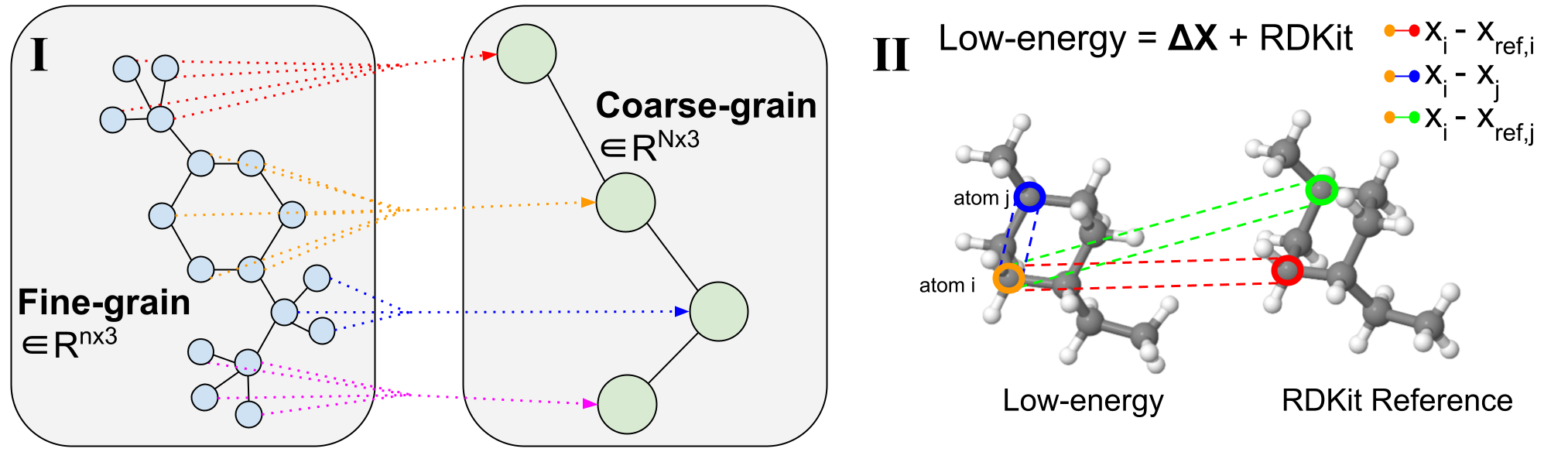
Рисунок 2: Процедура грубого зернистости.
(Я) Пример крупнозернистости переменной длины. Мелкозернистые молекулы расщеплены по вращающимся связям, которые определяют торсионные углы. Затем они подвергаются грубой детализации, чтобы уменьшить размерность и изучить скрытое распределение на уровне подграфа. (II) Визуализация 3D конформера. Определенные пары атомов выделены для операций передачи сообщений декодера.
Молекулярная крупнозернистость упрощает представление молекулы за счет группировки мелкозернистых (МЗ) атомов в исходной структуре в отдельные крупнозернистые (КЗ) шарики $\mathcal{B}$ с сопоставлением на основе правил, как показано на рис. 2. (Я). Грубая детализация широко используется в белковом и молекулярном дизайне, и, аналогично, генерация на уровне фрагментов или подграфов оказалась очень ценной в различных задачах двумерного дизайна молекул. Разбиение генеративных задач на более мелкие части — это подход, который может быть применен к нескольким задачам трехмерных молекул и обеспечивает естественное уменьшение размерности для работы с большими сложными системами.
Мы отмечаем, что по сравнению с предыдущими работами, которые сосредоточены на стратегиях CG с фиксированной длиной, где каждая молекула представлена с фиксированным разрешением $N$ зерен CG, наш метод использует CG переменной длины из-за его гибкости и способности поддерживать любой выбор грубых зерен. техника зернения. Это означает, что одну модель CoarsenConf можно обобщить до любого крупнозернистого разрешения, поскольку входные молекулы могут сопоставляться с любым количеством шариков компьютерной графики. В нашем случае атомы, состоящие из каждого связанного компонента, образовавшегося в результате разрыва всех вращающихся связей, укрупняются в единый шарик. Этот выбор в процедуре компьютерной графики неявно заставляет модель изучать углы кручения, а также координаты атомов и межатомные расстояния. В наших экспериментах мы используем GEOM-QM9 и GEOM-DRUGS, которые в среднем имеют 11 атомов и 3 гранулы CG и 44 атома и 9 бусинок CG соответственно.
SE(3)-эквивариантность
Ключевым аспектом при работе с трехмерными структурами является поддержание соответствующей эквивариантности. Трехмерные молекулы эквивариантны относительно вращений и трансляций или SE(3)-эквивариантности. Мы применяем SE(3)-эквивариантность в кодере, декодере и скрытом пространстве нашей вероятностной модели CoarsenConf. В результате $p(X | \mathcal{R})$ остается неизменным при любой рототрансляции приближенного конформера $\mathcal{R}$. Кроме того, если $\mathcal{R}$ повернут по часовой стрелке на 90°, мы ожидаем, что оптимальный угол $X$ повернется так же. Подробное определение и обсуждение методов поддержания эквивариантности см. в полной статье.
Совокупное внимание
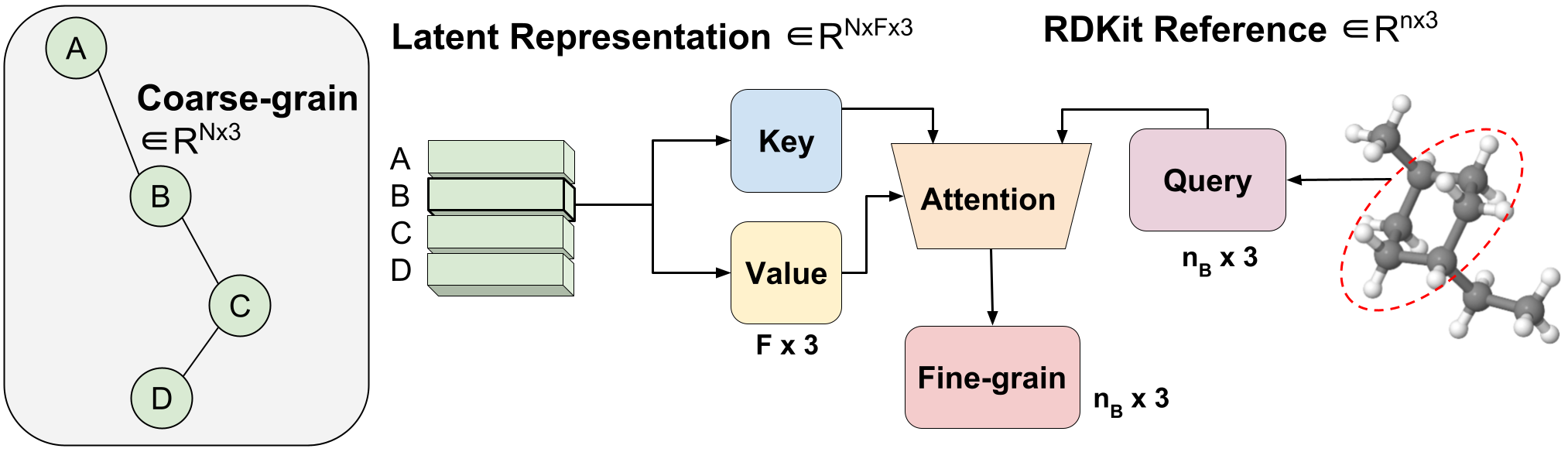
Рис. 3. Обратное сопоставление переменной длины от грубого к точному с помощью агрегированного внимания.
Мы вводим метод, который мы называем агрегированным вниманием, для изучения оптимального отображения переменной длины из скрытого представления CG в координаты FG. Это операция с переменной длиной, так как одна молекула с $n$ атомами может отображаться на любое количество $N$ шариков CG (каждый шарик представлен одним скрытым вектором). Скрытый вектор одной бусины CG $Z_{B}$ $\in R^{F \times 3}$ используется в качестве ключа и значения одной операции внимания головы с размером вложения, равным трем, для соответствия x, у, z координаты. Вектор запроса представляет собой подмножество конформера RDKit, соответствующего шарику $B$ $\in R^{ n_{B} \times 3}$, где $n_B$ имеет переменную длину, поскольку мы априори знаем, сколько атомов FG соответствует к определенной бусине CG. Используя внимание, мы эффективно изучаем оптимальное сочетание скрытых признаков для реконструкции ФГ. Мы называем это агрегированным вниманием, потому что оно объединяет 3D-сегменты информации FG для формирования нашего скрытого запроса. Агрегированное внимание отвечает за эффективный перевод из скрытого представления CG в жизнеспособные координаты FG (рис. 1 (III)).
Модель
CoarsenConf — это иерархический VAE с SE(3)-эквивариантным кодировщиком и декодером. Кодировщик оперирует SE(3)-инвариантными атомными свойствами $h \in R^{ n \times D}$ и SE(3)-эквивариантными атомистическими координатами $x \in R^{n \times 3}$. Один слой кодировщика состоит из трех модулей: мелкозернистого, объединяющего и крупнозернистого. Полные уравнения для каждого модуля можно найти в полной статье. Кодер создает окончательный эквивариантный тензор компьютерной графики $Z \in R^{N \times F \times 3}$, где $N$ – количество бусинок, а F – заданный пользователем скрытый размер.
Роль декодера двояка. Во-первых, это преобразование скрытого огрубленного представления обратно в пространство FG с помощью процесса, который мы называем выбором канала и который использует агрегированное внимание. Во-вторых, авторегрессионное уточнение мелкозернистого представления для получения окончательных низкоэнергетических координат (рис. 1 (IV)).
Мы подчеркиваем, что за счет грубой детализации по связности угла кручения наша модель изучает оптимальные углы кручения без присмотра, поскольку условный ввод в декодер не выровнен. CoarsenConf гарантирует, что каждый следующий сгенерированный подграф правильно повернут для достижения низкой ошибки координат и расстояния.
Результаты эксперимента
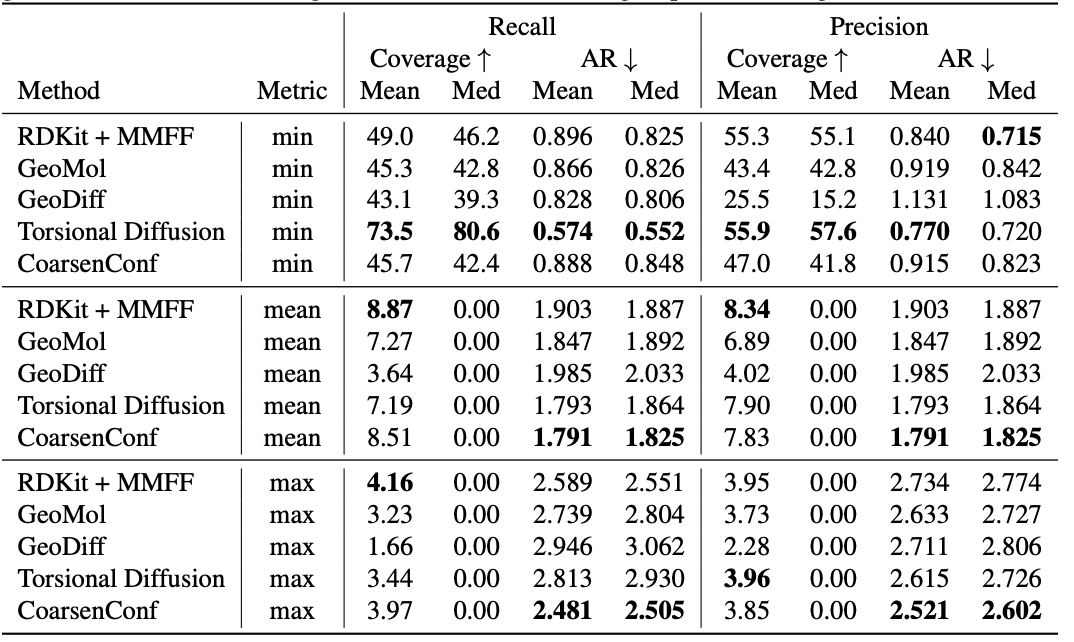
Таблица 1: Качество сгенерированных ансамблей конформеров для тестового набора GEOM-DRUGS ($\delta=0,75Å$) с точки зрения охвата (%) и среднего среднеквадратичного стандартного отклонения ($Å$). CoarsenConf (5 эпох) было ограничено использованием 7,3% данных, используемых Torsional Diffusion (250 эпох), чтобы проиллюстрировать режим с низким уровнем вычислений и ограниченными данными.
Средняя ошибка (AR) является ключевой метрикой, которая измеряет среднее среднеквадратичное отклонение для сгенерированных молекул соответствующего набора тестов. Покрытие измеряет процент молекул, которые могут быть сгенерированы в пределах определенного порога ошибки ($\delta$). Мы вводим средние и максимальные метрики, чтобы лучше оценить надежную генерацию и избежать систематической ошибки выборки минимальной метрики. Мы подчеркиваем, что минимальная метрика дает неосязаемые результаты, поскольку, если оптимальный конформер не известен априори, невозможно узнать, какой из сгенерированных 2L конформеров для отдельной молекулы является лучшим. Таблица 1 показывает, что CoarsenConf генерирует самую низкую среднюю и наихудшую ошибку по всему тестовому набору молекул DRUGS. Далее мы показываем, что RDKit с недорогой оптимизацией на основе физики (MMFF) обеспечивает лучшее покрытие, чем большинство методов, основанных на глубоком обучении. Формальные определения метрик и дальнейшее обсуждение см. в полном документе, ссылка на который приведена ниже.
Для получения более подробной информации о CoarsenConf, прочитать статью на arXiv.
БибТекс
Если CoarsenConf вдохновляет вашу работу, рассмотрите возможность цитирования:
@article{reidenbach2023coarsenconf,
title={CoarsenConf: Equivariant Coarsening with Aggregated Attention for Molecular Conformer Generation},
author={Danny Reidenbach and Aditi S. Krishnapriyan},
journal={arXiv preprint arXiv:2306.14852},
year={2023},
}