
Ни для кого не секрет, что высокопроизводительные модели ML должны снабжаться большими объемами качественных обучающих данных. Не имея данных, организация вряд ли сможет использовать искусственный интеллект и самоанализ, чтобы стать более эффективной и принимать более обоснованные решения. Известно, что процесс становления компании, основанной на данных (и особенно на искусственном интеллекте), непрост.
28% компаний, внедряющих ИИ называют отсутствие доступа к данным причиной неудачного развертывания. – КДНаггетс
Кроме того, существуют проблемы с ошибками и предвзятостью в существующих данных. Их несколько легче смягчить с помощью различных методов обработки, но это все равно влияет на доступность достоверных обучающих данных. Это серьезная проблема, но отсутствие данных для обучения — гораздо более серьезная проблема, и ее решение может потребовать множества инициатив в зависимости от уровня зрелости.
Помимо доступности данных и предвзятости, есть еще один аспект, о котором очень важно упомянуть: конфиденциальность данных. И компании, и частные лица последовательно предпочитают не допускать использования принадлежащих им данных третьим лицам для обучения моделей. Отсутствие прозрачности и законодательства по этой теме хорошо известно и уже стал катализатор законотворчества во всем мире.
Однако среди широкого спектра технологий, ориентированных на данные, есть одна, которая призвана решить вышеупомянутые проблемы с несколько неожиданной точки зрения. Эта технология представляет собой синтетические данные. Синтетические данные создаются путем моделирования с использованием различных моделей и сценариев или методов выборки существующих источников данных для создания новых данных, которые не получены из реального мира.
Синтетические данные могут заменить или дополнить существующие данные и использоваться для обучения моделей ОД, уменьшения предвзятости и защиты конфиденциальных или регулируемых данных. Он дешев и может производиться по требованию в больших количествах согласно указанной статистике.
Синтетические наборы данных сохраняют статистические свойства исходных данных, используемых в качестве источника: методы, генерирующие данные, получают совместное распределение, которое также можно настроить при необходимости. В результате синтетические наборы данных аналогичны своим реальным источникам, но не содержат никакой конфиденциальной информации. Это особенно полезно в жестко регулируемых отраслях, таких как банковское дело и здравоохранение, где сотруднику могут потребоваться месяцы, чтобы получить доступ к конфиденциальным данным из-за строгих внутренних процедур. Использование синтетических данных в этой среде для тестирования, обучения моделей ИИ, обнаружения мошенничества и других целей упрощает рабочий процесс и сокращает время, необходимое для разработки.
Все это также применимо к обучению больших языковых моделей, поскольку они обучаются в основном на общедоступных данных (например, OpenAI ChatGPT обучался на Википедии, частях веб-индекса и других общедоступных наборах данных), но мы считаем, что именно синтетические данные являются реальным отличием Кроме того, существует предел доступных общедоступных данных для моделей обучения (как физических, так и юридических), а данные, созданные человеком, стоят дорого, особенно если для этого требуются эксперты.
Производство синтетических данных
Существуют различные методы получения синтетических данных. Их можно разделить примерно на 3 основные категории, каждая из которых имеет свои преимущества и недостатки:
- Стохастическое моделирование процессов. Стохастические модели относительно просты в построении и не требуют большого количества вычислительных ресурсов, но поскольку моделирование ориентировано на статистическое распределение, данные на уровне строк не несут конфиденциальной информации. Простейшим примером моделирования стохастического процесса может быть создание столбца чисел на основе некоторых статистических параметров, таких как минимальное, максимальное и среднее значения, и при условии, что выходные данные подчиняются некоторому известному распределению (например, случайному или гауссову).
- Генерация данных на основе правил. Системы, основанные на правилах, улучшают статистическое моделирование, включая данные, генерируемые в соответствии с правилами, установленными людьми. Правила могут быть различной сложности, но для получения высококачественных данных требуются сложные правила и настройка специалистами-людьми, что ограничивает масштабируемость метода.
- Генеративные модели глубокого обучения. Применяя генеративные модели глубокого обучения, можно обучать модель на реальных данных и использовать эту модель для генерации синтетических данных. Модели глубокого обучения способны фиксировать более сложные взаимосвязи и совместное распределение наборов данных, но с более высокой сложностью и вычислительными затратами.
Также стоит отметить, что существующие LLM также можно использовать для генерации синтетических данных. Он не требует обширной настройки и может быть очень полезен в меньшем масштабе (или когда он выполняется только по запросу пользователя), поскольку может предоставлять как структурированные, так и неструктурированные данные, но в большем масштабе он может быть дороже, чем специализированные методы. Давайте не будем забывать, что современные модели склонны к галлюцинациям, поэтому статистические свойства синтетических данных, поступающих из LLM, следует проверять перед их использованием в сценариях, где распределение имеет значение.
Интересный пример, который может служить иллюстрацией того, как использование синтетических данных требует изменения подхода к обучению модели ML, — это подход к валидации модели.
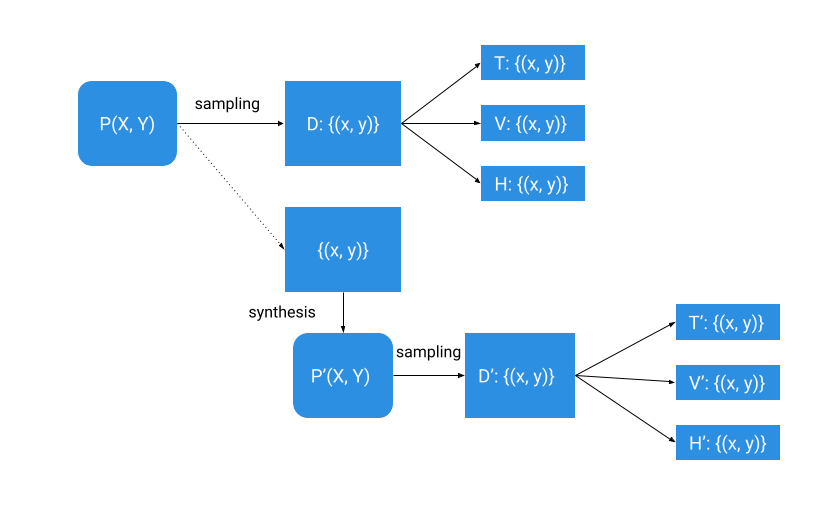
При традиционном моделировании данных у нас есть набор данных (D), который представляет собой набор наблюдений, полученных из какого-то неизвестного реального процесса (P), который мы хотим смоделировать. Мы делим этот набор данных на обучающее подмножество (T), проверочное подмножество (V) и контрольное (H) и используем его для обучения модели и оценки ее точности.
Чтобы выполнить моделирование синтетических данных, мы синтезируем распределение P’ из нашего исходного набора данных и отбираем его, чтобы получить синтетический набор данных (D’). Мы разделяем синтетический набор данных на обучающее подмножество (T’), подмножество проверки (V’) и контрольное подмножество (H’), как мы подразделяли реальный набор данных. Мы хотим, чтобы распределение P’ было максимально близко к P, поскольку мы хотим, чтобы точность модели, обученной на синтетических данных, была как можно ближе к точности модели, обученной на реальных данных (конечно, все гарантии синтетических данных должны быть соблюдены). держал).
Когда это возможно, при моделировании синтетических данных также следует использовать данные проверки (V) и данные проверки (H) из исходных исходных данных (D) для оценки модели, чтобы гарантировать, что модель, обученная на синтетических данных (T’), хорошо работает в реальных условиях. данные.
Таким образом, хорошее решение на основе синтетических данных должно позволять нам моделировать P(X, Y) максимально точно, сохраняя при этом все гарантии конфиденциальности.
Хотя более широкое использование синтетических данных для обучения моделей требует изменения и улучшения существующих подходов, по нашему мнению, это многообещающая технология для решения текущих проблем с владением данными и конфиденциальностью. Его правильное использование приведет к созданию более точных моделей, которые улучшат и автоматизируют процесс принятия решений, значительно снизив риски, связанные с использованием частных данных.
Об авторе
Ник Волынец — старший инженер по данным, работающий в офисе технического директора, где ему нравится быть в центре инноваций DataRobot. Он интересуется крупномасштабным машинным обучением и увлечен искусственным интеллектом и его влиянием.
Знакомьтесь: Ник Волынец