

Исследователи Массачусетского технологического института разработали технику искусственного интеллекта, которая позволяет роботу разрабатывать сложные планы манипулирования объектом, используя всю руку, а не только кончики пальцев. Эта модель может генерировать эффективные планы примерно за минуту, используя стандартный ноутбук. Здесь робот пытается повернуть ковш на 180 градусов. Изображение: предоставлено исследователями
Адам Зеве | Новости Массачусетского технологического института
Представьте, что вы хотите нести большую и тяжелую коробку вверх по лестнице. Вы можете растопырить пальцы и поднять коробку обеими руками, затем держать ее на предплечьях и сбалансировать на груди, используя все тело, чтобы манипулировать коробкой.
Люди, как правило, хорошо умеют манипулировать всем телом, но роботы с такими задачами справляются с трудом. Для робота каждое место, где коробка может коснуться любой точки на пальцах, руках и туловище носителя, представляет собой событие контакта, о котором он должен подумать. Учитывая миллиарды потенциальных контактов, планирование этой задачи быстро становится невыполнимым.
Сейчас Исследователи MIT нашли способ упростить этот процесс, известное как планирование манипуляций с большим количеством контактов. Они используют метод искусственного интеллекта, называемый сглаживанием, который суммирует множество событий контакта в меньшее количество решений, чтобы даже простой алгоритм мог быстро определить эффективный план манипуляции для робота.
Хотя этот метод еще находится на заре своего развития, он потенциально может позволить фабрикам использовать меньших мобильных роботов, которые могут манипулировать объектами всей рукой или телом, а не большими роботизированными руками, которые могут захватывать только кончиками пальцев. Это может помочь снизить потребление энергии и снизить затраты. Кроме того, эта технология может быть полезна в роботах, отправляемых в исследовательские миссии на Марс или другие тела Солнечной системы, поскольку они смогут быстро адаптироваться к окружающей среде, используя только бортовой компьютер.
«Вместо того, чтобы думать об этом как о системе «черного ящика», если мы сможем использовать структуру такого рода роботизированных систем с помощью моделей, есть возможность ускорить всю процедуру принятия этих решений и придумать богатые контактами решения. планы», — говорит HJ Терри Суаспирант электротехники и информатики (EECS) и соавтор книги бумага по этой технике.
В работе над статьей к Суху присоединяются соавтор Тао Панг, доктор философии ’23, робототехник из Бостонского института динамического искусственного интеллекта; Луцзе Ян, аспирант EECS; и старший автор Расс Тедрейк, профессор EECS, аэронавтики, космонавтики и машиностроения Toyota, а также член Лаборатории компьютерных наук и искусственного интеллекта (CSAIL). Исследование появится на этой неделе в Транзакции IEEE в робототехнике.
Обучение об обучении
Обучение с подкреплением — это метод машинного обучения, при котором агент, подобно роботу, учится выполнять задачу методом проб и ошибок с вознаграждением за приближение к цели. Исследователи говорят, что этот тип обучения использует подход «черного ящика», поскольку система должна изучать все о мире методом проб и ошибок.
Он эффективно использовался для планирования манипуляций с большим количеством контактов, когда робот пытается научиться лучше всего перемещать объект определенным образом.
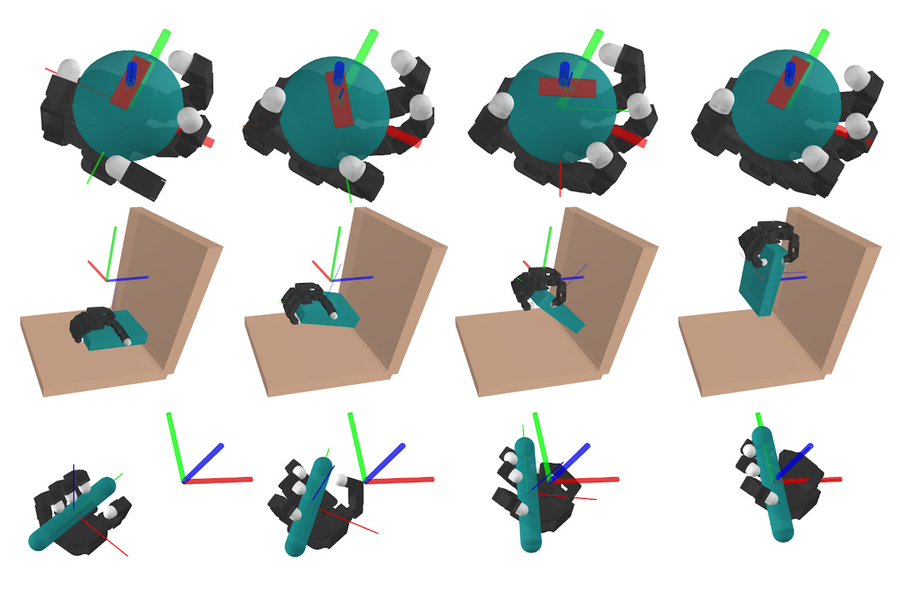
На этих рисунках смоделированный робот выполняет три задачи манипулирования, насыщенные контактами: манипулирование мячом в руке, взятие тарелки и приведение ручки в определенную ориентацию. Изображение: предоставлено исследователями
Но поскольку могут существовать миллиарды потенциальных точек контакта, о которых робот должен учитывать, определяя, как использовать свои пальцы, руки, руки и тело для взаимодействия с объектом, этот подход методом проб и ошибок требует большого количества вычислений.
«Обучению с подкреплением, возможно, потребуются миллионы лет моделирования, чтобы действительно можно было изучить политику», — добавляет Су.
С другой стороны, если исследователи специально разрабатывают модель, основанную на физике, используя свои знания о системе и задаче, которую они хотят выполнить от робота, эта модель включает в себя структуру этого мира, которая делает его более эффективным.
Однако подходы, основанные на физике, не так эффективны, как обучение с подкреплением, когда дело доходит до планирования манипуляций с большим количеством контактов — Су и Панг задавались вопросом, почему.
Они провели подробный анализ и обнаружили, что метод, известный как сглаживание, обеспечивает столь хорошую работу обучения с подкреплением.
Многие решения, которые робот может принять при определении того, как манипулировать объектом, не важны в общей схеме вещей. Например, каждое бесконечно малое движение одного пальца, независимо от того, приводит ли оно к контакту с объектом, не имеет большого значения. Сглаживание средних значений исключает многие из этих неважных, промежуточных решений, оставляя лишь несколько важных.
Обучение с подкреплением неявно выполняет сглаживание, пробуя множество точек контакта и затем вычисляя средневзвешенное значение результатов. Опираясь на это понимание, исследователи Массачусетского технологического института разработали простую модель, которая выполняет аналогичный тип сглаживания, что позволяет ей сосредоточиться на основных взаимодействиях робота и объекта и прогнозировать долгосрочное поведение. Они показали, что этот подход может быть столь же эффективным, как и обучение с подкреплением, при создании сложных планов.
«Если вы знаете немного больше о своей проблеме, вы сможете разработать более эффективные алгоритмы», — говорит Панг.
Выигрышная комбинация
Несмотря на то, что сглаживание значительно упрощает принятие решений, поиск оставшихся решений все равно может оказаться сложной проблемой. Итак, исследователи объединили свою модель с алгоритмом, который может быстро и эффективно перебирать все возможные решения, которые может принять робот.
Благодаря такой комбинации время вычислений на стандартном ноутбуке сократилось примерно до минуты.
Сначала они проверили свой подход на симуляциях, где роботизированным рукам давались такие задачи, как перемещение ручки в желаемую конфигурацию, открытие двери или поднятие тарелки. В каждом случае их подход, основанный на моделях, достиг той же производительности, что и обучение с подкреплением, но за долю времени. Они увидели аналогичные результаты, когда протестировали свою модель на реальных роботизированных руках.
«Те же идеи, которые позволяют манипулировать всем телом, также работают и для планирования с помощью ловких человеческих рук. Ранее большинство исследователей говорили, что обучение с подкреплением — единственный подход, который можно масштабировать при наличии ловких рук, но Терри и Тао показали, что, взяв эту ключевую идею (рандомизированного) сглаживания из обучения с подкреплением, они могут заставить более традиционные методы планирования работать очень хорошо. — говорит Тедрейк.
Однако разработанная ими модель основана на более простой аппроксимации реального мира, поэтому она не может обрабатывать очень динамичные движения, такие как падение объектов. Хотя этот подход эффективен для более медленных манипуляций, его подход не может создать план, который позволил бы роботу, например, выбросить мусорное ведро в мусорное ведро. В будущем исследователи планируют усовершенствовать свою технику, чтобы она могла справляться с этими высокодинамичными движениями.
«Если вы внимательно изучите свои модели и действительно поймете проблему, которую пытаетесь решить, вы определенно сможете добиться определенных успехов. Есть преимущества в том, чтобы делать вещи, выходящие за рамки черного ящика», — говорит Су.
Эту работу частично финансируют Amazon, Лаборатория Линкольна Массачусетского технологического института, Национальный научный фонд и группа Ocado.

Новости Массачусетского технологического института