
В 2016 году мы представили АльфаГо, первая программа искусственного интеллекта (ИИ), победившая людей в древней игре Го. Через два года его преемник – АльфаНоль – научился с нуля осваивать го, шахматы и сёги. Сейчас, в статье в журнале Nature, мы описываем MuZero, значительный шаг вперед в поиске алгоритмов общего назначения. MuZero осваивает игры в го, шахматы, сёги и Atari без необходимости рассказывать правила благодаря своей способности планировать выигрышные стратегии в незнакомых условиях.
В течение многих лет исследователи искали методы, которые могли бы изучить модель, объясняющую окружающую их среду, а затем использовать эту модель для планирования наилучшего курса действий. До сих пор большинство подходов не позволяло эффективно планировать в таких областях, как Atari, где правила или динамика обычно неизвестны и сложны.
MuZero, впервые представленный в предварительный документ в 2019 году, решает эту проблему, изучая модель, которая фокусируется только на наиболее важных аспектах среды планирования. Объединив эту модель с мощным поиском по дереву с опережением AlphaZero, MuZero установила новый современный результат в тесте Atari, одновременно сравнявшись с производительностью AlphaZero в классических задачах планирования го, шахмат и сёги. При этом MuZero демонстрирует значительный скачок в возможностях алгоритмов обучения с подкреплением.

Обобщение на неизвестные модели
Способность планировать — важная часть человеческого интеллекта, позволяющая нам решать проблемы и принимать решения о будущем. Например, если мы видим, как формируются темные облака, мы можем предсказать, что будет дождь, и решить взять с собой зонт, прежде чем выйти на улицу. Люди быстро учатся этой способности и могут обобщать новые сценарии — черта, которую мы также хотели бы иметь в наших алгоритмах.
Исследователи пытались решить эту серьезную проблему в области ИИ, используя два основных подхода: поиск с опережением или планирование на основе моделей.
Системы, использующие упреждающий поиск, такие как AlphaZero, добились значительных успехов в классических играх, таких как шашки, шахматы и покер, но полагаются на знание динамики окружающей среды, например, на правила игры или точный симулятор. Это затрудняет их применение к запутанным задачам реального мира, которые обычно сложны и их трудно свести к простым правилам.
Системы на основе моделей призваны решить эту проблему, изучив точную модель динамики среды и затем используя ее для планирования. Однако сложность моделирования каждого аспекта среды означает, что эти алгоритмы не могут конкурировать в визуально насыщенных областях, таких как Atari. До сих пор лучшие результаты на Atari были у систем без моделей, таких как DQN, R2D2 и Агент57. Как следует из названия, алгоритмы без моделей не используют изученную модель, а вместо этого оценивают, какое действие лучше всего предпринять дальше.
MuZero использует другой подход для преодоления ограничений предыдущих подходов. Вместо того, чтобы пытаться моделировать всю среду, MuZero просто моделирует аспекты, важные для процесса принятия решений агентом. В конце концов, знать, что зонт не даст вам промокнуть, полезнее, чем моделировать рисунок капель дождя в воздухе.
В частности, MuZero моделирует три элемента среды, которые имеют решающее значение для планирования:
- ценить: насколько хороша текущая позиция?
- политика: какие действия лучше предпринять?
- награда: насколько хорошо было последнее действие?
Все это изучается с помощью глубокой нейронной сети, и это все, что нужно MuZero, чтобы понять, что происходит, когда он выполняет определенное действие, и соответственно планировать.



У этого подхода есть еще одно важное преимущество: MuZero может многократно использовать изученную модель для улучшения планирования, а не собирать новые данные из окружающей среды. Например, в тестах пакета Atari этот вариант, известный как MuZero Reanalyze, использовал изученную модель в 90% случаев для перепланирования того, что должно было быть сделано в прошлых эпизодах.
Производительность MuZero
Мы выбрали четыре разных домена для тестирования возможностей MuZeros. Го, шахматы и сёги использовались для оценки его производительности при решении сложных задач планирования, в то время как мы использовали пакет Atari в качестве эталона для решения более сложных визуально задач. Во всех случаях MuZero установил новый уровень развития алгоритмов обучения с подкреплением, превзойдя все предыдущие алгоритмы в пакете Atari и сравнявшись со сверхчеловеческой производительностью AlphaZero в го, шахматах и сёги.

Мы также более подробно проверили, насколько хорошо MuZero может планировать с помощью своей обученной модели. Мы начали с классической задачи точного планирования в го, где один ход может означать разницу между победой и поражением. Чтобы подтвердить интуицию о том, что большее планирование должно привести к лучшим результатам, мы измерили, насколько сильнее может стать полностью обученная версия MuZero, если ей будет предоставлено больше времени для планирования каждого движения (см. левый график ниже). Результаты показали, что сила игры увеличивается более чем на 1000 Эло (показатель относительного мастерства игрока), когда мы увеличиваем время на ход с одной десятой секунды до 50 секунд. Это похоже на разницу между сильным игроком-любителем и сильнейшим профессиональным игроком.
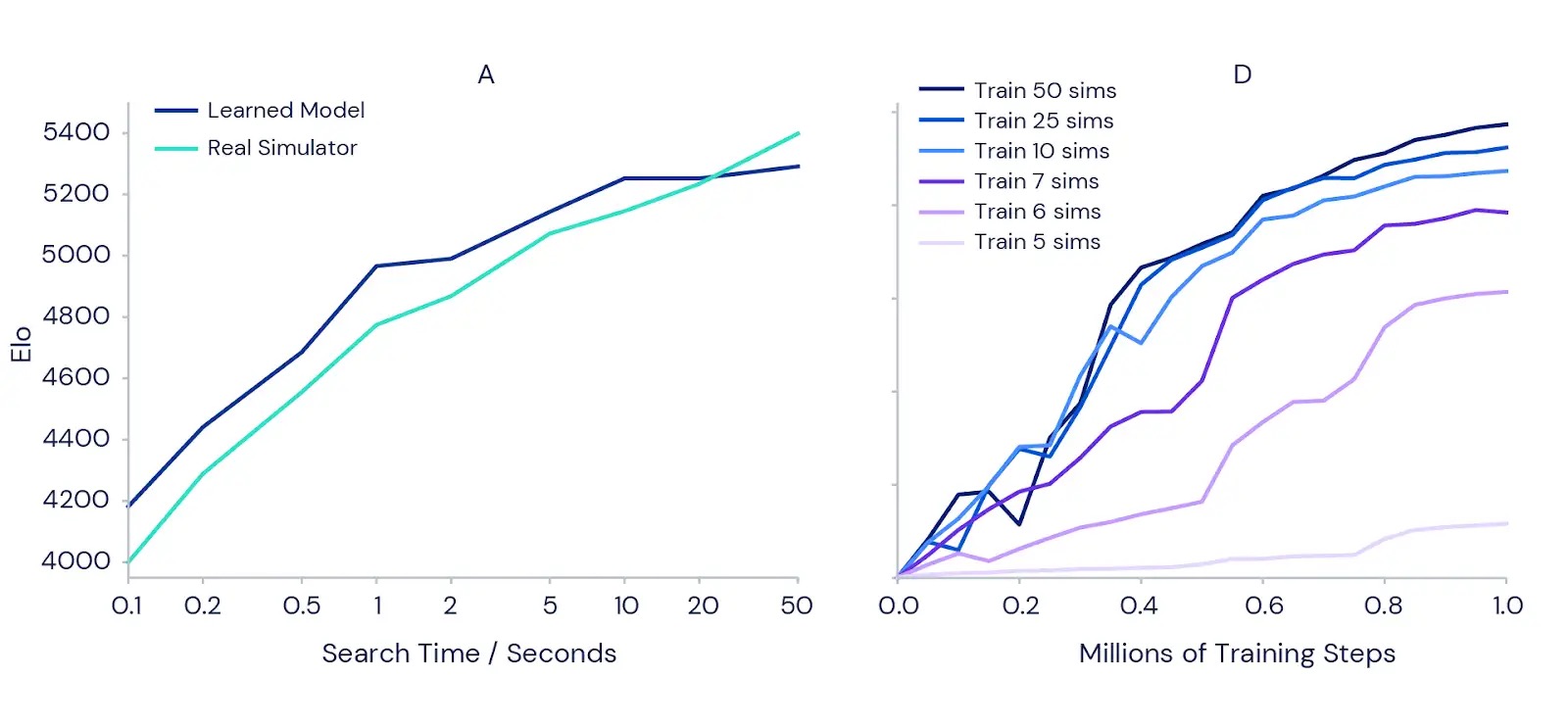
Чтобы проверить, приносит ли планирование преимущества во время обучения, мы провели ряд экспериментов с игрой Atari Ms Pac-Man (правый график выше) с использованием отдельных обученных экземпляров MuZero. Каждому из них было позволено рассмотреть различное количество симуляций планирования на ход, от пяти до 50. Результаты подтвердили, что увеличение объема планирования для каждого хода позволяет MuZero учиться быстрее и достигать более высоких конечных результатов.
Интересно, что когда MuZero разрешалось учитывать только шесть или семь симуляций на ход — число слишком мало, чтобы охватить все доступные действия в Ms Pac-Man, — он все равно показал хорошую производительность. Это говорит о том, что MuZero может обобщать действия и ситуации, и ему не нужно тщательно искать все возможности для эффективного обучения.
Новые горизонты
Способность MuZero как изучать модель своей среды, так и использовать ее для успешного планирования демонстрирует значительный прогресс в обучении с подкреплением и поиске алгоритмов общего назначения. Его предшественник, AlphaZero, уже применялся для решения ряда сложных задач в химия, квантовая физика и не только. Идеи, лежащие в основе мощных алгоритмов обучения и планирования MuZero, могут проложить путь к решению новых задач в робототехнике, промышленных системах и других грязных реальных средах, где «правила игры» неизвестны.
Ссылки по теме: