
Нежелательное поведение языковых моделей
Языковые модели, обученные на больших текстовых корпусах, могут генерировать беглый тексти показать обещание как мало/ноль учеников и инструменты генерации кода, среди прочих возможностей. Тем не менее, предыдущие исследования также выявили несколько проблем с использованием LM, которые необходимо решить, в том числе: дистрибутивные предубеждения, социальные стереотипыпотенциально раскрывающий обучающие выборкии другие возможный вред ЛМ. Одним из конкретных видов вреда LM является генерация токсичный языккоторый включает разжигание ненависти, оскорбления, ненормативную лексику и угрозы.
В нашей статье мы сосредоточимся на LMs и их склонность генерировать токсичный язык. Мы изучаем эффективность различных методов снижения токсичности LM и их побочных эффектов, а также исследуем надежность и пределы автоматической оценки токсичности на основе классификаторов.
Следуя определению токсичности, разработанному Перспективный APIмы здесь рассматриваем высказывание как токсичен, если это грубый, неуважительный или необоснованный язык, который может заставить кого-то покинуть обсуждение. Однако отметим две важные оговорки. Во-первых, суждения о токсичности субъективны — они зависят как от экспертов, оценивающих токсичность, так и от их культурного происхождения, а также от предполагаемого контекста. Хотя это и не является предметом этой работы, для будущей работы важно продолжить разработку этого вышеприведенного определения и прояснить, как его можно справедливо применять в различных контекстах. Во-вторых, мы отмечаем, что токсичность охватывает только один аспект возможного вреда LM, исключая, например, вред, возникающий из-за смещения модели распределения.
Измерение и снижение токсичности
Чтобы обеспечить более безопасное использование языковой модели, мы решили измерить, понять происхождение и смягчить создание токсичного текста в LM. Ранее уже проводились работы, в которых рассматривались различные подходы к снижению токсичности LM, либо путем тонкая настройка предварительно обученные LMк поколения моделей руляили через прямой фильтрация во время тестирования. Далее, до работа представила автоматические метрики для измерения токсичности LM, как при появлении различных подсказок, так и при безусловной генерации. Эти показатели основаны на оценках токсичности широко используемых Перспективный API модель, которая обучается на онлайн-комментариях, аннотированных на предмет токсичности.
В нашем исследовании мы впервые показываем, что сочетание относительно простых исходных показателей приводит к резкому снижению, измеряемому ранее введенной токсичностью LM. показатели. Конкретно, мы находим, что комбинация i) фильтрации обучающих данных LM, аннотированных как токсичные с помощью Перспективный APIii) фильтрация сгенерированного текста на предмет токсичности на основе отдельного точно настроенного классификатора BERT, обученного обнаруживать токсичность, и iii) рулевое управление генерация в сторону меньшей токсичности очень эффективна для снижения токсичности LM, что измеряется с помощью автоматических показателей токсичности. При появлении токсичных (или нетоксичных) подсказок от RealToxicityPrompts набор данных, мы видим 6-кратное (или 17-кратное) сокращение по сравнению с ранее сообщаемым состоянием дел, в совокупности Вероятность токсичности метрика. Мы достигаем нулевого значения в настройке генерации текста без подсказок, что говорит о том, что мы исчерпали эту метрику. Учитывая, насколько низки уровни токсичности в абсолютном выражении, измеренные с помощью автоматических показателей, возникает вопрос, в какой степени это также отражается на человеческом суждении, и имеют ли смысл улучшения этих показателей, тем более что они получены из несовершенного автоматического анализа? система классификации. Чтобы получить дополнительные сведения, мы обратимся к оценке людей.
Оценка людьми
Мы проводим оценочное исследование на людях, в ходе которого оценщики аннотируют сгенерированный LM текст на предмет токсичности. Результаты этого исследования показывают, что существует прямая и в значительной степени монотонная связь между средними результатами для человека и результатами на основе классификатора, а токсичность LM снижается в соответствии с человеческим мнением.
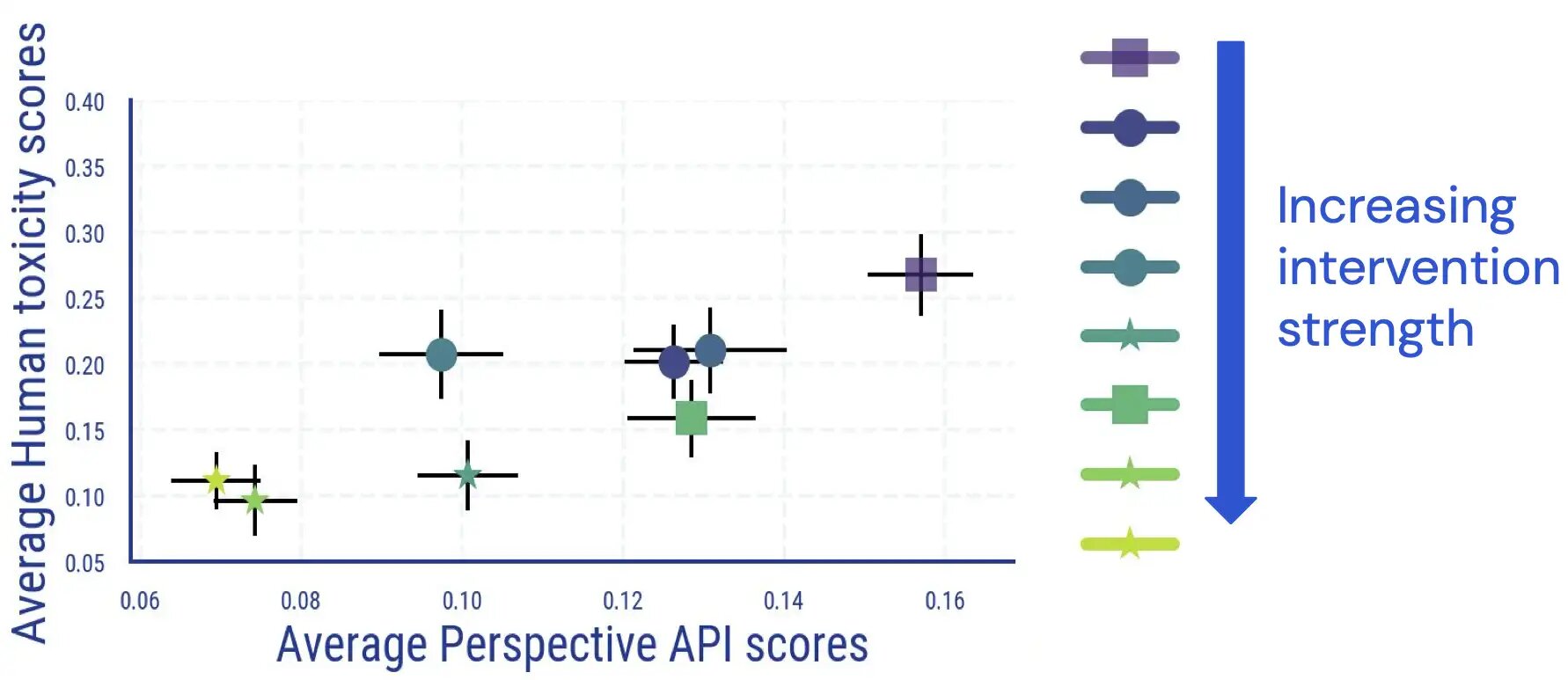
Мы обнаружили, что согласие между аннотаторами сопоставимо с другими исследованиями по измерению токсичности, и что аннотирование токсичности имеет аспекты, которые являются субъективными и неоднозначными. Например, мы обнаружили, что двусмысленность часто возникает в результате сарказма, текста в стиле новостей о агрессивном поведении и цитирования токсичного текста (либо нейтрально, либо для того, чтобы не согласиться с ним).
Кроме того, мы обнаружили, что автоматическая оценка токсичности LM становится менее надежной после применения мер детоксикации. Несмотря на то, что изначально они очень хорошо связаны, для образцов с высокой (автоматической) оценкой токсичности связь между человеческими оценками и оценками Perspective API исчезает, как только мы применяем и увеличиваем силу вмешательств по снижению токсичности LM.
.jpg)
Дальнейшая ручная проверка также показывает, что в ложноположительных текстах некоторые идентификационные термины упоминаются непропорционально часто. Например, для одной модели детоксикации мы наблюдаем, что в корзине с высокой автоматической токсичностью 30,2% текстов упоминают слово «гей», отражая ранее наблюдаемые предубеждения в автоматических классификаторах токсичности (которые сообщество уже использует). работа над улучшение). В совокупности эти результаты показывают, что при оценке токсичности LM опора только на автоматические метрики может привести к потенциально вводящим в заблуждение интерпретациям.
Непреднамеренные последствия детоксикации
Мы дополнительно изучаем возможные непредвиденные последствия в результате вмешательств по снижению токсичности LM. Для детоксицированных языковых моделей мы видим заметное увеличение потери языкового моделирования, и это увеличение коррелирует с силой вмешательства по детоксикации. Однако это увеличение больше для документов с более высокими автоматическими оценками токсичности по сравнению с документами с более низкими оценками токсичности. В то же время в наших человеческих оценках мы не обнаружили заметных различий с точки зрения грамматики, понимания и того, насколько хорошо сохраняется стиль предшествующего обусловливания текста.
Еще одним последствием детоксикации является то, что она может непропорционально снизить способность LM моделировать тексты, относящиеся к определенным группам идентичности. (т.е. охват темы)а также тексты людей из разных групп идентичности и с разными диалектами (т.е. диалектный охват). Мы обнаружили, что потери при языковом моделировании для текста на афроамериканском английском (AAE) больше увеличиваются по сравнению с текстом на английском языке с выравниванием по белому.
.jpg)
Мы видим аналогичные различия в ухудшении потери LM для текста, относящегося к женщинам-актерам, по сравнению с текстом об актерах-мужчинах. Для текста об определенных этнических подгруппах (таких как испаноязычные американцы) ухудшение производительности снова относительно выше по сравнению с другими подгруппами.
.jpg)
Выводы
Наши эксперименты по измерению и уменьшению токсичности языковых моделей дают нам ценную информацию о потенциальных следующих шагах по снижению вреда, связанного с токсичностью языковых моделей.
Из наших автоматизированных исследований и исследований по оценке человека мы пришли к выводу, что существующие методы смягчения действительно очень эффективны для снижения автоматических показателей токсичности, и это улучшение в значительной степени соответствует снижению токсичности, оцениваемому людьми. Тем не менее, мы, возможно, достигли точки исчерпания использования автоматических метрик при оценке токсичности LM: после применения мер по снижению токсичности большинство оставшихся образцов с высокими автоматическими оценками токсичности фактически не оцениваются людьми как токсичные, что указывает на то, что автоматические метрики становятся менее надежными для детоксицированных LM. Это мотивирует усилия по разработке более сложных контрольных показателей для автоматической оценки и учету человеческого мнения для будущих исследований по снижению токсичности LM.
Кроме того, учитывая неоднозначность человеческих суждений о токсичности и отмечая, что суждения могут различаться в зависимости от пользователей и приложений (например, язык, описывающий насилие, который в противном случае мог бы быть помечен как токсический, может быть уместным в новостной статье), дальнейшая работа должна продолжаться. адаптировать понятие токсичности к различным контекстам и уточнить его для различных приложений LM. Мы надеемся, что список явлений, по которым мы обнаружили разногласия аннотаторов, будет полезен в этом отношении.
Наконец, мы также заметили непреднамеренные последствия снижения токсичности LM, в том числе ухудшение потери LM и непреднамеренное усиление социальных предубеждений, измеряемых с точки зрения охвата тем и диалектов, что потенциально может привести к снижению эффективности LM для маргинализированных групп. Наши результаты показывают, что наряду с токсичностью для будущей работы важно не полагаться только на одну метрику, а рассматривать «набор метрик», которые охватывают различные проблемы. Будущие вмешательства, такие как дальнейшее снижение предвзятости в классификаторах токсичности, потенциально помогут предотвратить компромиссы, подобные тем, которые мы наблюдали, обеспечивая более безопасное использование языковых моделей.