
Около года назад мы включили новый тип функции в одну из наших моделей, используемую для рекомендации элементов контента нашим пользователям. Я говорю о миниатюре элемента контента:

До этого момента мы использовали функции заголовка и метаданных элемента. С заголовком легче работать, чем с миниатюрой — с точки зрения машинного обучения.
Наша модель повзрослела, и пришло время добавить миниатюру на вечеринку. Это решение было первым шагом к ужасной предвзятости, внесенной в нашу процедуру разделения поезд-тест. Позвольте мне раскрыть историю…
Настройка сцены
Исходя из нашего опыта, трудно включить несколько типов функций в единую модель. Поэтому мы решили пойти маленькими шажками и добавить миниатюру к модели, которая использует только одну функцию — название.
Есть одна вещь, которую вы должны учитывать при работе с этими двумя функциями, и это утечка данных. При работе только с заголовком вы можете наивно разбивать набор данных на обучающие тесты случайным образом — предварительно удалив элементы с одинаковым заголовком. Однако вы не можете применить случайное разделение, когда работаете и с заголовком, и с миниатюрой. Это связано с тем, что многие элементы имеют одинаковые миниатюры или названия. Стоковые фотографии — хороший пример общих миниатюр для разных предметов. Таким образом, модель, которая запоминает заголовки/миниатюры, с которыми она столкнулась в тренировочном наборе, может хорошо работать на тестовом наборе, но плохо справляется с обобщением.
Решение? Мы должны разделить набор данных так, чтобы каждая миниатюра появлялась либо в обучении, либо в тесте, но не в обоих одновременно. То же самое касается названия.
Первая попытка
Что ж, это звучит просто. Начнем с самой простой реализации. Мы пометим все строки в наборе данных как «поезд». Затем мы будем итеративно преобразовывать строки в «тест», пока не получим желаемое разделение, скажем, 80%-20%. Как осуществляется конвертация? На каждом шаге цикла мы будем выбирать случайную строку «поезда» и помечать ее для преобразования. Перед преобразованием мы проверим все строки с одинаковым заголовком/миниатюрой и также пометим их. Мы будем продолжать делать это до тех пор, пока не останется строк, которые мы можем пометить. Наконец, мы преобразуем отмеченную группу в «тест».
А потом дело обострилось
На первый взгляд кажется, что в наивном решении нет ничего плохого. Каждая миниатюра/заголовок появляется либо в режиме обучения, либо в режиме тестирования. Так в чем же проблема?
Сначала я покажу вам симптомы проблемы. Чтобы можно было сравнить модель только для заголовков с моделью, которая также использует миниатюру, мы также использовали новое разделение для модели только для заголовков. Это не должно влиять на его производительность, верно? Но тогда мы получили следующие результаты:
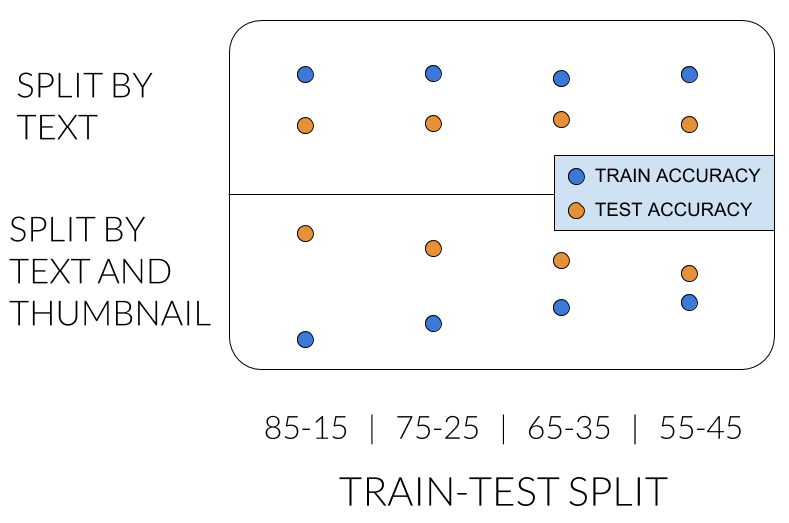
В верхнем ряду мы видим то, что мы уже знаем: модель только для заголовка имеет более высокую точность в наборе поездов, и на точность не оказывает существенного влияния соотношение разделения.
Проблема всплывает в нижней строке, где мы применяем новый метод разделения. Мы ожидали увидеть похожие результаты, но модель только для заголовков оказалась лучше в тестах. Что?… Так не должно быть. Кроме того, на производительность сильно влияет соотношение. Что-то подозрительно…

Так где же скрывается проблема?
Вы можете думать о нашем наборе данных как о двудольном графике, где одна сторона — это миниатюры, а другая — заголовки. Между миниатюрой и заголовком есть граница, если есть элемент с этой миниатюрой и заголовком.

Что мы действительно сделали в нашем новом разделении, так это убедились, что каждый подключенный компонент полностью находится либо в поезде, либо в тестовом наборе.
Получается, что раскол необъективен. Он имеет тенденцию выбирать большие компоненты для тестового набора. Скажем, тестовый набор должен содержать 15% строк. Вы ожидали, что он будет содержать 15% компонентов, но мы получили 4%.

Вторая попытка
В чем проблема с тем, что мы сделали? При случайной выборке строки вероятность получения строки из определенного компонента пропорциональна размеру компонента. Таким образом, тестовый набор оказался с небольшим количеством крупных компонентов. Это может показаться нелогичным, но вот фрагмент кода, который вы можете попробовать испытать на себе:
import numpy as np
import matplotlib.pyplot as plt
def train_test_split(component_sizes, test_size):
train = component_sizes
test = ()
while sum(test) < test_size:
convert = np.random.choice(range(len(train)),
p=train.astype('float') / sum(train))
test.append(train(convert))
train = np.delete(train, convert)
return train, test
component_sizes = np.array(range(1, 10000))
test_size = int(sum(component_sizes) * 0.5)
train, test = train_test_split(component_sizes, test_size)
plt.hist((train, test), label=('train', 'test'), bins=30)
plt.title('Distribution of sizes of components', fontsize=20)
plt.xlabel('component size', fontsize=16)
plt.legend(fontsize=14)
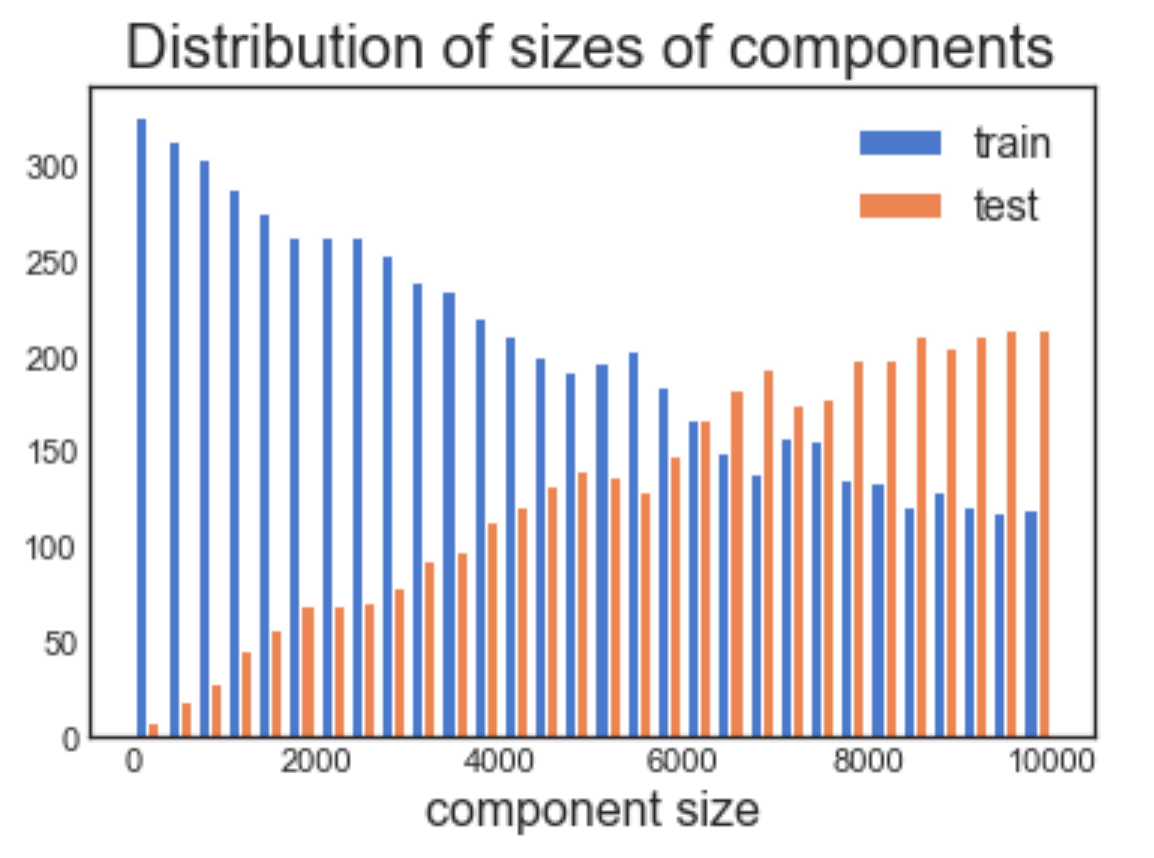
Распределение размеров компонентов отличается между поездом и тестовым набором.
Теперь, когда мы лучше формализовали то, что мы делали, с помощью двудольного графа, мы можем реализовать разделение путем случайной выборки связанных компонентов вместо случайной выборки строк. При этом каждый компонент получает одинаковую вероятность быть выбранным для тестового набора.
Ключ на вынос
То, как вы разделяете свой набор данных на обучающие тесты, имеет решающее значение для исследовательской фазы проекта. Во время исследования вы тратите значительную часть своего времени на просмотр производительности тестового набора. Не всегда просто построить тестовый набор так, чтобы он отражал то, что происходит во время вывода.
Возьмем, к примеру, задачу рекомендации элемента пользователю: вы можете либо порекомендовать совершенно новый элемент, либо элемент, который был показан другим пользователям в прошлом. Оба важны.
Чтобы понять, как модель ведет себя в автономном режиме на этапе исследования, вам необходимо создать тестовый набор, который содержит как совершенно новые элементы, так и элементы, которые появляются в наборе поездов. Что такое правильная пропорция? Трудно сказать… Думаю, это может стать темой для другого поста в другой день 🙂
Первоначально опубликовано мной на
Engineering.taboola.com.