
Организации общественного здравоохранения располагают огромным объемом данных о различных типах заболеваний, тенденциях в области здравоохранения и факторах риска. Их сотрудники уже давно используют статистические модели и регрессионный анализ для принятия важных решений, таких как нацеливание терапевтических средств на группы населения с самыми высокими факторами риска заболевания или прогнозирование развития соответствующих вспышек.
Когда возникают угрозы общественному здравоохранению, скорость передачи данных увеличивается, входящие наборы данных могут увеличиваться, а управление данными становится более сложным. Это затрудняет целостный анализ данных и извлечение из них выводов. А когда время имеет решающее значение, скорость и гибкость анализа данных и извлечения из них информации являются ключевыми препятствиями для формирования быстрых и надежных ответных мер в области здравоохранения.
Типичные вопросы, с которыми организации общественного здравоохранения сталкиваются во время стресса, включают:
- Будет ли достаточно терапевтических средств в определенном месте?
- Какие факторы риска влияют на результаты в отношении здоровья?
- Какие группы населения имеют более высокий риск повторного заражения?
Поскольку для ответа на эти вопросы требуется понимание сложных взаимосвязей между множеством различных факторов, часто меняющихся и динамичных, в нашем распоряжении есть один мощный инструмент — машинное обучение (МО), которое можно использовать для анализа, прогнозирования и решения этих сложных количественных задач. Мы все чаще видим, как машинное обучение применяется для решения сложных проблем, связанных со здоровьем, таких как классификация опухолей головного мозга с помощью анализа изображений и прогнозирование необходимости психического здоровья для развертывания программ раннего вмешательства.
Но что произойдет, если организациям общественного здравоохранения не хватает навыков, необходимых для применения машинного обучения к этим вопросам? Применение машинного обучения к проблемам общественного здравоохранения затруднено, и организации общественного здравоохранения теряют способность применять мощные количественные инструменты для решения своих проблем.
Так как же нам убрать эти узкие места? Ответ заключается в том, чтобы демократизировать машинное обучение и позволить большему количеству специалистов в области здравоохранения с глубокими знаниями предметной области использовать его и применять к вопросам, которые они хотят решить.
Amazon SageMaker Canvas — это инструмент машинного обучения без написания кода, который позволяет специалистам в области общественного здравоохранения, таким как эпидемиологи, информатики и биостатистики, применять машинное обучение к своим вопросам, не требуя знаний в области обработки данных или опыта в области машинного обучения. Они могут тратить свое время на данные, применять свои знания в предметной области, быстро проверять гипотезы и количественно оценивать идеи. Canvas помогает сделать общественное здравоохранение более справедливым за счет демократизации ML, позволяя экспертам в области здравоохранения оценивать большие наборы данных и предоставляя им передовые аналитические данные с помощью ML.
В этом посте мы покажем, как эксперты в области общественного здравоохранения могут спрогнозировать спрос на определенное терапевтическое средство на следующие 30 дней с помощью Canvas. Canvas предоставляет вам визуальный интерфейс, который позволяет вам самостоятельно генерировать точные прогнозы ML, не требуя никакого опыта ML или написания одной строки кода.
Обзор решения
Допустим, мы работаем с данными, которые мы собрали в штатах США. Мы можем сформировать гипотезу о том, что в ближайшие недели в каком-то муниципалитете или месте не будет достаточно терапевтических средств. Как мы можем проверить это быстро и с высокой степенью точности?
Для этого поста мы используем общедоступный набор данных Министерства здравоохранения и социальных служб США, который содержит агрегированные данные временных рядов, связанные с COVID-19, включая использование больниц, доступность определенных терапевтических средств и многое другое. Набор данных (Сообщения о воздействии COVID-19 на пациентов и вместимость больниц по штатам (RAW)) можно загрузить с сайта healthdata.gov, и он содержит 135 столбцов и более 60 000 строк. Набор данных периодически обновляется.
В следующих разделах мы покажем, как выполнять исследовательский анализ и подготовку данных, строить модель прогнозирования машинного обучения и генерировать прогнозы с помощью Canvas.
Выполнение исследовательского анализа и подготовки данных
При прогнозировании временных рядов в Canvas нам нужно уменьшить количество функций или столбцов в соответствии с квотами службы. Первоначально мы уменьшаем количество столбцов до 12, которые, вероятно, будут наиболее релевантными. Например, мы отказались от столбцов с указанием возраста, потому что хотим прогнозировать общий спрос. Мы также удалили столбцы, данные которых были аналогичны другим сохраненным нами столбцам. В будущих итерациях разумно поэкспериментировать с сохранением других столбцов и использованием объяснимости функций в Canvas, чтобы количественно оценить важность этих функций и то, что мы хотим сохранить. Мы также переименовываем state столбец к location.
Глядя на набор данных, мы также решили удалить все строки за 2020 год, потому что в то время было ограниченное количество доступных терапевтических средств. Это позволяет нам уменьшить шум и улучшить качество данных для обучения модели машинного обучения.
Уменьшить количество столбцов можно разными способами. Вы можете редактировать набор данных в электронной таблице или непосредственно в Canvas с помощью пользовательского интерфейса.
Вы можете импортировать данные в Canvas из различных источников, в том числе из локальных файлов с вашего компьютера, корзин Amazon Simple Storage Service (Amazon S3), Amazon Athena, Snowflake (см. Canvas) и более 40 дополнительных источников данных.
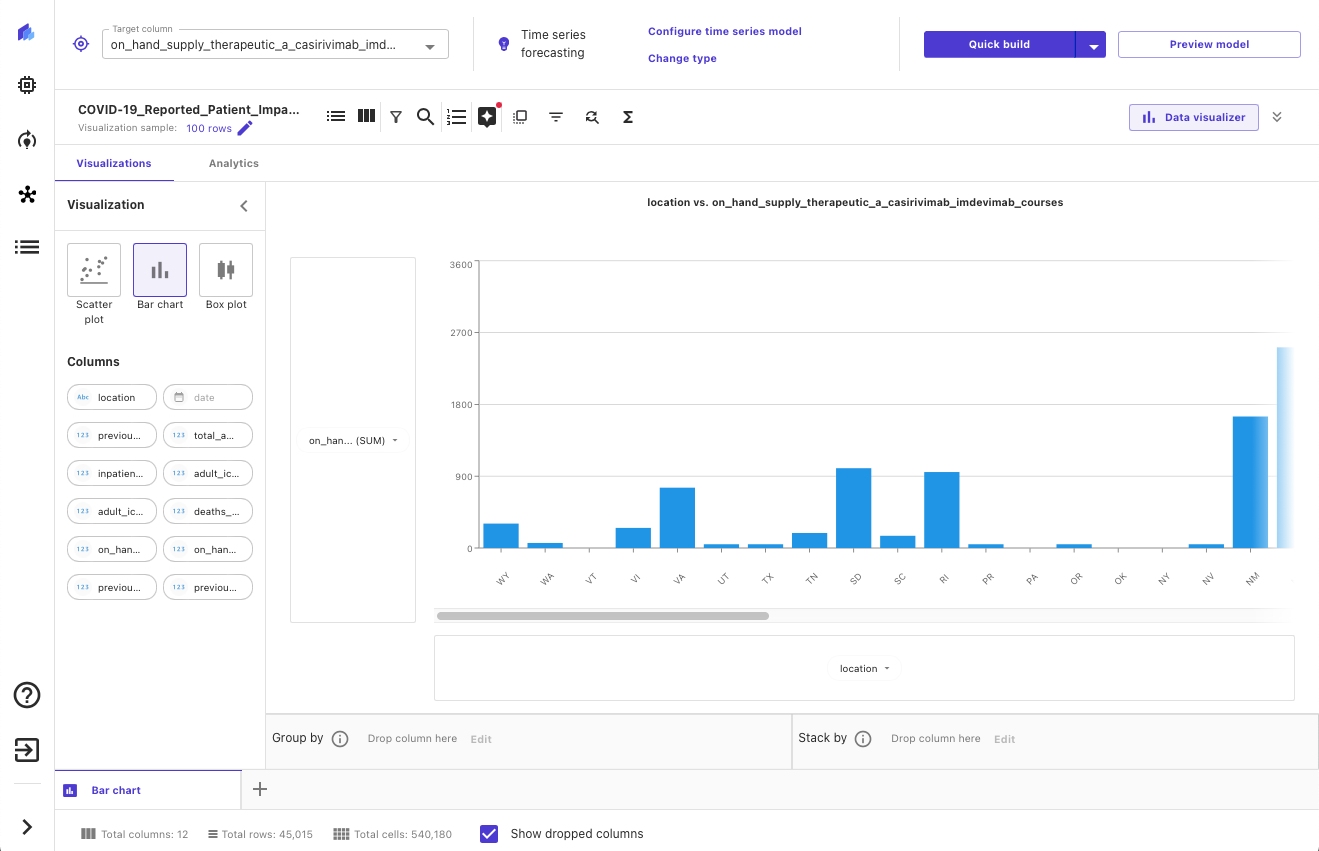
После того, как наши данные были импортированы, мы можем изучить и визуализировать наши данные, чтобы получить дополнительную информацию о них, например, с помощью диаграмм рассеяния или гистограмм. Мы также смотрим на корреляцию между различными функциями, чтобы убедиться, что мы выбрали то, что считаем лучшим. На следующем снимке экрана показан пример визуализации.
Создайте модель прогнозирования машинного обучения
Теперь мы готовы создать нашу модель, что мы можем сделать всего за несколько кликов. Мы выбираем колонку, идентифицирующую имеющиеся в наличии терапевтические средства, в качестве нашей цели. Canvas автоматически идентифицирует нашу проблему как прогноз временного ряда на основе только что выбранного нами целевого столбца, и мы можем настроить необходимые параметры.
Мы настраиваем item_id, уникальный идентификатор, как местоположение, потому что наш набор данных предоставляется по местоположению (штаты США). Поскольку мы создаем прогноз временных рядов, нам нужно выбрать отметку времени, которая date в нашем наборе данных. Наконец, мы указываем, сколько дней в будущем мы хотим прогнозировать (в этом примере мы выбираем 30 дней). Canvas также предлагает возможность включения графика выходных для повышения точности. В этом случае мы используем праздничные дни в США, потому что это набор данных из США.
С Canvas вы можете получить представление о своих данных, прежде чем строить модель, выбрав Предварительная версия модели. Это экономит время и деньги, поскольку не нужно строить модель, если результаты вряд ли будут удовлетворительными. При предварительном просмотре нашей модели мы понимаем, что влияние некоторых столбцов невелико, а это означает, что ожидаемое значение столбца для модели низкое. Мы удаляем столбцы, отменяя их выбор в Canvas (красные стрелки на следующем снимке экрана), и видим улучшение оценочной метрики качества (зеленая стрелка).
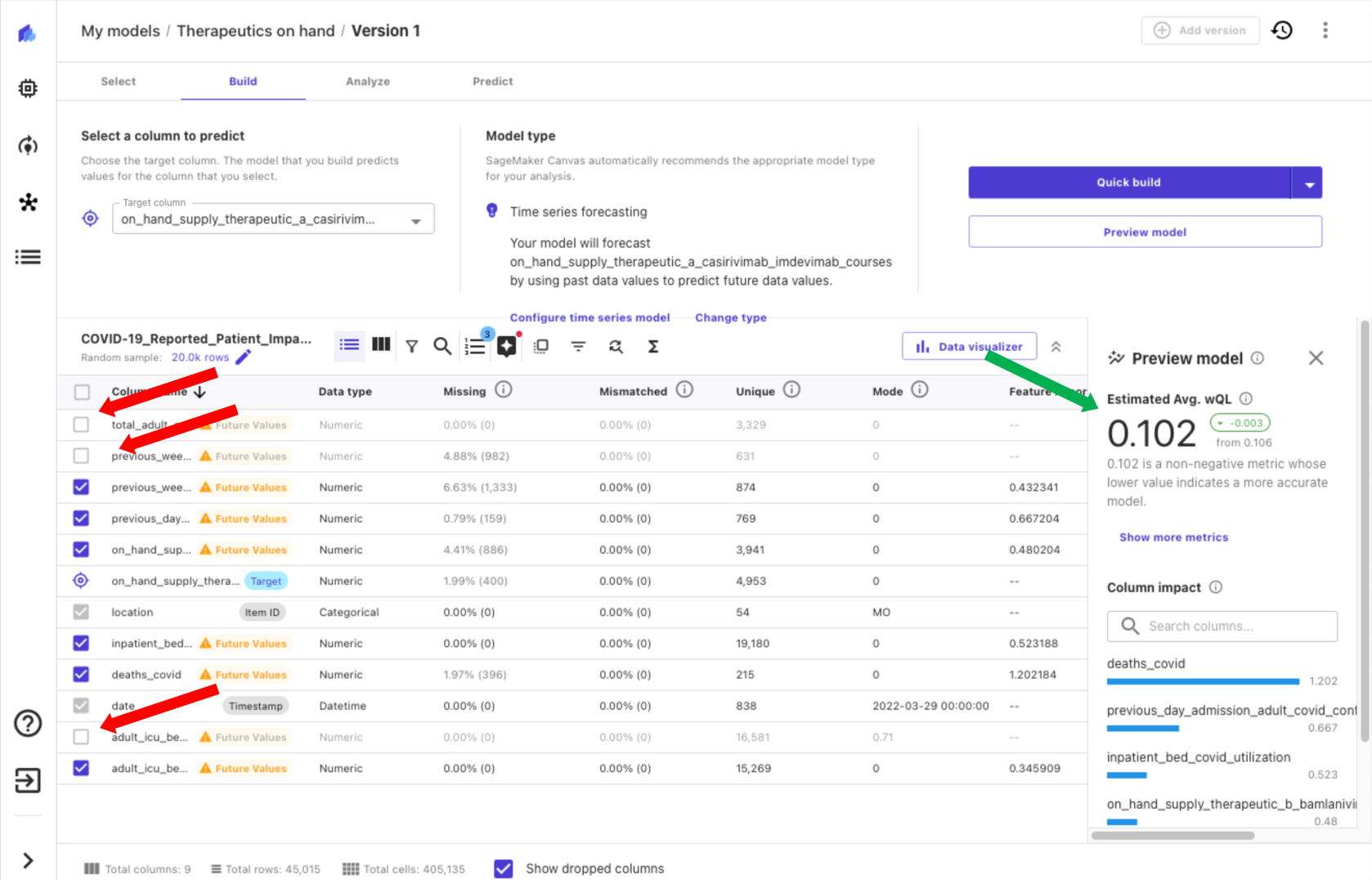
Переходя к построению нашей модели, у нас есть два варианта: Быстрая сборка и Стандартная сборка. Быстрая сборка позволяет создать обученную модель менее чем за 20 минут, при этом скорость важнее точности. Это отлично подходит для экспериментов и является более тщательной моделью, чем модель предварительного просмотра. Стандартная сборка создает обученную модель менее чем за 4 часа, отдавая предпочтение точности, а не задержке, итерируя ряд конфигураций модели для автоматического выбора лучшей модели.
Во-первых, мы экспериментируем с быстрой сборкой, чтобы проверить нашу предварительную версию модели. Затем, поскольку мы довольны моделью, мы выбираем стандартную сборку, чтобы Canvas помог построить наилучшую возможную модель для нашего набора данных. Если бы модель быстрой сборки дала неудовлетворительные результаты, мы бы вернулись и скорректировали входные данные, чтобы получить более высокий уровень точности. Мы могли бы добиться этого, например, добавив или удалив столбцы или строки в нашем исходном наборе данных. Модель быстрой сборки поддерживает быстрые эксперименты без необходимости полагаться на скудные ресурсы науки о данных или ждать завершения полной модели.
Генерация прогнозов
Теперь, когда модель построена, мы можем предсказать доступность терапевтических средств. location. Давайте посмотрим, как выглядит наш расчетный запас в наличии на следующие 30 дней, в данном случае для Вашингтона, округ Колумбия.
Canvas выводит вероятностные прогнозы терапевтического спроса, позволяя нам понять как медианное значение, так и верхние и нижние границы. На следующем снимке экрана вы можете увидеть конец исторических данных (данные из исходного набора данных). Затем вы можете увидеть три новые линии: медианный (50-й квантиль) прогноз фиолетового цвета, нижняя граница (10-й квантиль) светло-синего цвета и верхняя граница (90-й квантиль) темно-синего цвета.
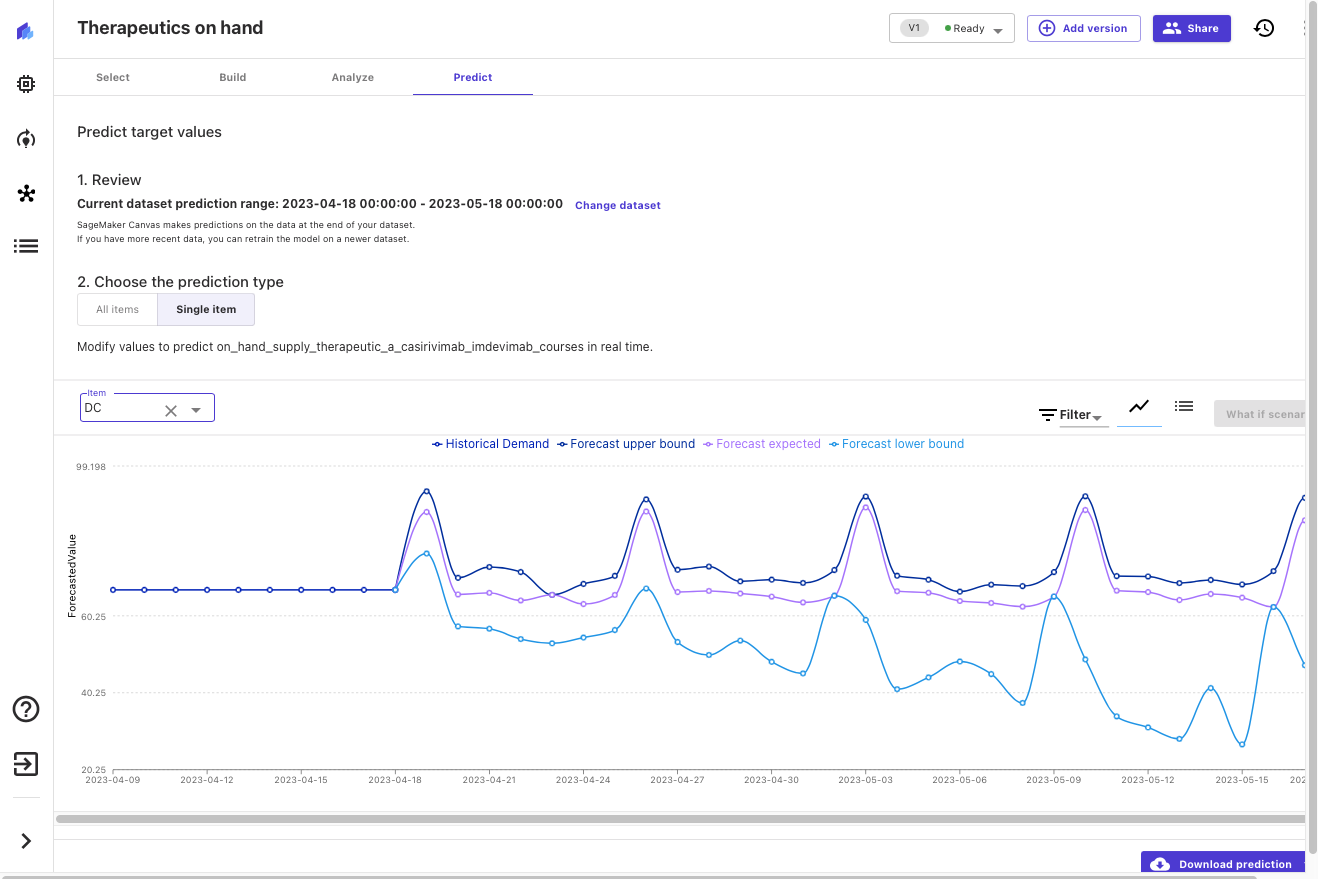
Изучение верхних и нижних границ дает представление о распределении вероятностей прогноза и позволяет нам принимать обоснованные решения о желаемых уровнях местных запасов для этого терапевтического средства. Мы можем добавить эту информацию к другим данным (например, к прогнозам прогрессирования заболевания или терапевтической эффективности и усвоению), чтобы принимать обоснованные решения о будущих заказах и уровнях запасов.
Заключение
Инструменты машинного обучения без кода позволяют экспертам в области общественного здравоохранения быстро и эффективно применять машинное обучение к угрозам для общественного здравоохранения. Эта демократизация машинного обучения делает организации общественного здравоохранения более гибкими и эффективными в их миссии по защите общественного здоровья. Специальные анализы, которые могут выявить важные тенденции или точки перегиба в проблемах общественного здравоохранения, теперь могут выполняться непосредственно специалистами, без необходимости конкурировать за ограниченные ресурсы экспертов по машинному обучению и замедлять время реагирования и принятия решений.
В этом посте мы показали, как человек, не знакомый с машинным обучением, может использовать Canvas для прогнозирования наличных запасов определенного терапевтического средства. Этот анализ может выполнить любой аналитик в этой области благодаря возможностям облачных технологий и машинного обучения без кода. Это позволяет широко распределять возможности и позволяет учреждениям общественного здравоохранения более оперативно реагировать и более эффективно использовать ресурсы централизованных и местных отделений для достижения лучших результатов в области общественного здравоохранения.
Какие вопросы вы можете задавать и как инструменты low-code/no-code могут помочь вам ответить на них? Если вы хотите узнать больше о Canvas, обратитесь к Amazon SageMaker Canvas и начните применять машинное обучение к своим количественным вопросам здоровья.
Об авторах
 Хенрик Балле является старшим архитектором решений в AWS, поддерживающей государственный сектор США. Он тесно сотрудничает с клиентами по целому ряду тем, от машинного обучения до безопасности и управления в любом масштабе. В свободное время он любит кататься на шоссейном велосипеде, мотоцикле, или вы можете найти его работающим над еще одним проектом по благоустройству дома.
Хенрик Балле является старшим архитектором решений в AWS, поддерживающей государственный сектор США. Он тесно сотрудничает с клиентами по целому ряду тем, от машинного обучения до безопасности и управления в любом масштабе. В свободное время он любит кататься на шоссейном велосипеде, мотоцикле, или вы можете найти его работающим над еще одним проектом по благоустройству дома.
 Дэн Синнрайх руководит управлением продуктами Go to Market для Amazon SageMaker Canvas и Amazon Forecast. Он сосредоточен на демократизации машинного обучения low-code/no-code и применении его для улучшения бизнес-результатов. До AWS Дэн создавал корпоративные платформы SaaS и модели рисков временных рядов, используемые институциональными инвесторами для управления рисками и формирования портфелей. Вне работы его можно найти играющим в хоккей, ныряющим с аквалангом, путешествующим и читающим научную фантастику.
Дэн Синнрайх руководит управлением продуктами Go to Market для Amazon SageMaker Canvas и Amazon Forecast. Он сосредоточен на демократизации машинного обучения low-code/no-code и применении его для улучшения бизнес-результатов. До AWS Дэн создавал корпоративные платформы SaaS и модели рисков временных рядов, используемые институциональными инвесторами для управления рисками и формирования портфелей. Вне работы его можно найти играющим в хоккей, ныряющим с аквалангом, путешествующим и читающим научную фантастику.