
Организации постоянно тратят время и усилия на разработку интеллектуальных рекомендательных решений для предоставления персонализированного и актуального контента своим пользователям. Целей может быть много: изменить пользовательский опыт, создать значимое взаимодействие и стимулировать потребление контента. Некоторые из этих решений используют общие модели машинного обучения (ML), основанные на исторических шаблонах взаимодействия, демографических характеристиках пользователей, сходстве продуктов и групповом поведении. Помимо этих атрибутов, контекст (например, погода, местоположение и т. д.) во время взаимодействия может влиять на решения пользователей при навигации по содержимому.
В этом посте мы покажем, как использовать текущий тип устройства пользователя в качестве контекста для повышения эффективности ваших рекомендаций на основе Amazon Personalize. Кроме того, мы покажем, как использовать такой контекст для динамической фильтрации рекомендаций. Хотя в этом посте показано, как Amazon Personalize можно использовать для видео по запросу (VOD), стоит отметить, что Amazon Personalize можно использовать в различных отраслях.
Что такое персонализация Amazon?
Amazon Personalize позволяет разработчикам создавать приложения на основе технологии машинного обучения того же типа, что и Amazon.com для предоставления персонализированных рекомендаций в режиме реального времени. Amazon Personalize может предоставить широкий спектр возможностей персонализации, включая рекомендации по конкретным продуктам, персонализированное изменение рейтинга продуктов и индивидуализированный прямой маркетинг. Кроме того, как полностью управляемый сервис искусственного интеллекта, Amazon Personalize ускоряет цифровую трансформацию клиентов с помощью машинного обучения, упрощая интеграцию персонализированных рекомендаций в существующие веб-сайты, приложения, системы электронного маркетинга и многое другое.
Почему важен контекст?
Использование контекстных метаданных пользователя, таких как местоположение, время суток, тип устройства и погода, обеспечивает персонализированный опыт для существующих пользователей и помогает улучшить фазу холодного запуска для новых или неидентифицированных пользователей. фаза холодного пуска относится к периоду, когда ваш механизм рекомендаций предоставляет неперсонализированные рекомендации из-за отсутствия исторической информации об этом пользователе. В ситуациях, когда существуют другие требования для фильтрации и продвижения элементов (например, в новостях и погоде), добавление текущего контекста пользователя (сезона или времени суток) помогает повысить точность путем включения и исключения рекомендаций.
Давайте возьмем пример платформы VOD, которая рекомендует пользователю шоу, документальные фильмы и фильмы. Основываясь на поведенческом анализе, мы знаем, что пользователи VOD, как правило, потребляют более короткий контент, такой как ситкомы, на мобильных устройствах и более длинный контент, такой как фильмы, на телевизоре или компьютере.
Обзор решения
Расширяя пример рассмотрения типа устройства пользователя, мы показываем, как предоставить эту информацию в качестве контекста, чтобы Amazon Personalize мог автоматически определять влияние устройства пользователя на предпочитаемые им типы контента.
Мы следуем шаблону архитектуры, показанному на следующей диаграмме, чтобы проиллюстрировать, как контекст может автоматически передаваться в Amazon Personalize. Автоматическое получение контекста достигается с помощью заголовков Amazon CloudFront, которые включаются в запросы, такие как REST API в Amazon API Gateway, который вызывает функцию AWS Lambda для получения рекомендаций. См. полный пример кода, доступный на нашем Репозиторий GitHub. Мы предоставляем шаблон AWS CloudFormation для создания необходимых ресурсов.
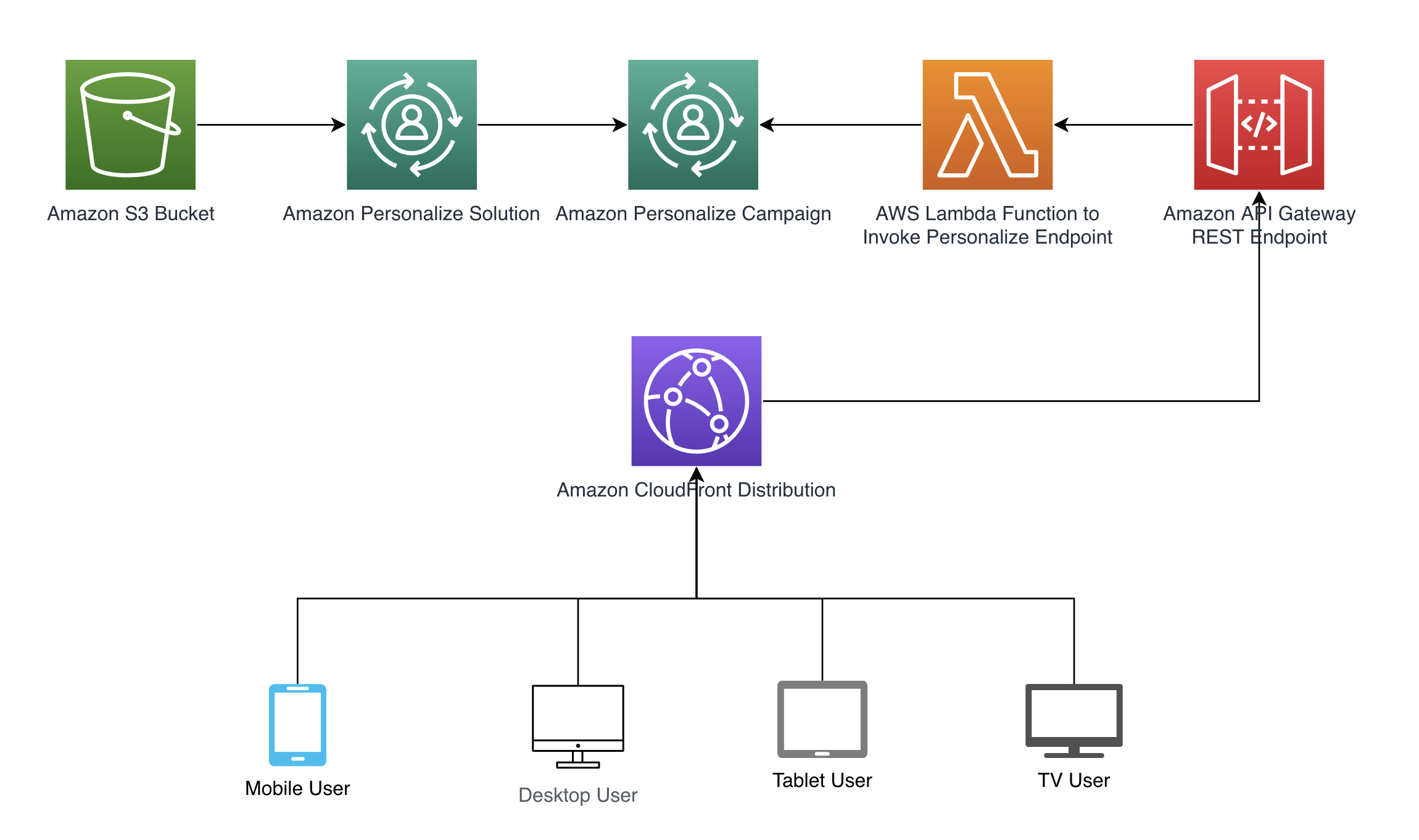
В следующих разделах мы рассмотрим, как настроить каждый шаг образца архитектуры.
Выберите рецепт
Рецепты — это алгоритмы Amazon Personalize, подготовленные для конкретных случаев использования. Amazon Personalize предоставляет рецепты, основанные на распространенных случаях использования обучающих моделей. В нашем случае мы создаем простой пользовательский рекомендатель Amazon Personalize, используя рецепт User-Personalization. Он предсказывает элементы, с которыми пользователь будет взаимодействовать, на основе набора данных о взаимодействиях. Кроме того, этот рецепт также использует элементы и наборы данных пользователей, чтобы влиять на рекомендации, если они предоставлены. Чтобы узнать больше о том, как работает этот рецепт, обратитесь к рецепту User-Personalization.
Создание и импорт набора данных
Использование контекста требует указания значений контекста с взаимодействиями, чтобы рекомендатели могли использовать контекст в качестве признаков при обучении моделей. Мы также должны предоставить текущий контекст пользователя во время вывода. Схема взаимодействий (см. следующий код) определяет структуру исторических данных и данных о взаимодействии пользователей с элементами в реальном времени. USER_ID, ITEM_IDи TIMESTAMP поля требуются Amazon Personalize для этого набора данных. DEVICE_TYPE — это пользовательское категориальное поле, которое мы добавляем для этого примера, чтобы зафиксировать текущий контекст пользователя и включить его в обучение модели. Amazon Personalize использует этот набор данных о взаимодействиях для обучения моделей и создания рекомендательных кампаний.
Точно так же схема элементов (см. следующий код) определяет структуру данных о продуктах и видеокаталогах. ITEM_ID требуется Amazon Personalize для этого набора данных. CREATION_TIMESTAMP зарезервированное имя столбца, но оно не обязательно. GENRE и ALLOWED_COUNTRIES — это настраиваемые поля, которые мы добавляем для этого примера, чтобы зафиксировать жанр видео и страны, в которых разрешено воспроизведение видео. Amazon Personalize использует этот набор данных для обучения моделей и создания рекомендательных кампаний.
В нашем контексте, исторические данные относится к истории взаимодействия конечного пользователя с видео и элементами на платформе VOD. Эти данные обычно собираются и хранятся в базе данных приложения.
В демонстрационных целях мы используем библиотеку Python Faker для создания некоторых тестовых данных, имитирующих набор данных о взаимодействиях с различными элементами, пользователями и типами устройств за 3-месячный период. После того, как схема и расположение файла входных взаимодействий определены, следующие шаги заключаются в создании группы наборов данных, включении набора данных взаимодействий в группу наборов данных и, наконец, импорте обучающих данных в набор данных, как показано в следующих фрагментах кода:
Соберите исторические данные и обучите модель
На этом этапе мы определяем выбранный рецепт и создаем решение и версию решения, ссылаясь на ранее определенную группу наборов данных. При создании пользовательского решения вы указываете рецепт и настраиваете параметры обучения. Когда вы создаете версию решения для решения, Amazon Personalize обучает модель, поддерживающую версию решения, на основе рецепта и конфигурации обучения. См. следующий код:
Создание конечной точки кампании
После обучения модели вы развертываете ее в кампания. Кампания создает и управляет конечной точкой с автоматическим масштабированием для вашей обученной модели, которую вы можете использовать для получения персонализированных рекомендаций с помощью GetRecommendations API. На более позднем этапе мы используем эту конечную точку кампании для автоматической передачи типа устройства в качестве контекста в качестве параметра и получения персонализированных рекомендаций. См. следующий код:
Создать динамический фильтр
Получая рекомендации из созданной кампании, вы можете фильтровать результаты на основе настраиваемых критериев. В нашем примере мы создаем фильтр, чтобы удовлетворить требование рекомендации видео, которые разрешено воспроизводить только из текущей страны пользователя. Информация о стране передается динамически из HTTP-заголовка CloudFront.
Создайте лямбда-функцию
Следующим шагом в нашей архитектуре является создание функции Lambda для обработки запросов API, поступающих от базы раздачи CloudFront, и ответа путем вызова конечной точки кампании Amazon Personalize. В этой функции Lambda мы определяем логику для анализа следующих HTTP-заголовков запроса CloudFront и параметров строки запроса, чтобы определить тип устройства пользователя и идентификатор пользователя соответственно:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerCloudFront-Viewer-Country
Код для создания этой функции развертывается через шаблон CloudFormation.
Создать REST-API
Чтобы сделать функцию Lambda и конечную точку кампании Amazon Personalize доступной для дистрибутива CloudFront, мы создаем конечную точку REST API, настроенную как прокси-сервер Lambda. Шлюз API предоставляет инструменты для создания и документирования API, которые направляют HTTP-запросы к функциям Lambda. Функция интеграции прокси-сервера Lambda позволяет CloudFront вызывать одну функцию Lambda, абстрагируя запросы к конечной точке кампании Amazon Personalize. Код для создания этой функции развертывается через шаблон CloudFormation.
Создайте раздачу CloudFront
При создании раздачи CloudFront, поскольку это демонстрационная установка, мы отключаем кэширование с помощью пользовательской политики кэширования, чтобы каждый раз запрос направлялся к источнику. Кроме того, мы используем политику запроса источника, определяющую необходимые заголовки HTTP и параметры строки запроса, которые включены в запрос источника. Код для создания этой функции развертывается через шаблон CloudFormation.
Рекомендации по тестированию
При доступе к URL-адресу раздачи CloudFront с разных устройств (настольный компьютер, планшет, телефон и т. д.) мы можем видеть персонализированные рекомендации по видео, которые наиболее актуальны для их устройств. Кроме того, если представлен холодный пользователь, будут представлены рекомендации, адаптированные для устройства пользователя. В следующих примерах выходных данных названия видео используются только для представления их жанра и времени выполнения, чтобы сделать их похожими.
В следующем коде известный пользователь, который любит комедии на основе прошлых взаимодействий и заходит с мобильного устройства, представлен более короткими ситкомами:
Следующему известному пользователю отображаются художественные фильмы при доступе с устройства Smart TV на основе прошлых взаимодействий:
Холодному (неизвестному) пользователю, заходящему с телефона, показывают более короткие, но популярные шоу:
Recommendations for user: 666 ITEM_ID GENRE ALLOWED_COUNTRIES 940 Satire US|FI|CN|ES|HK|AE 760 Satire US|FI|CN|ES|HK|AE 160 Sitcom US|FI|CN|ES|HK|AE 880 Comedy US|FI|CN|ES|HK|AE 360 Satire US|PK|NI|JM|IN|DK 840 Satire US|PK|NI|JM|IN|DK 420 Satire US|PK|NI|JM|IN|DK
Холодному (неизвестному) пользователю, заходящему с рабочего стола, показываются лучшие научно-фантастические и документальные фильмы:
Следующий известный пользователь, получающий доступ с телефона, возвращает отфильтрованные рекомендации на основе местоположения (США):
Заключение
В этом посте мы описали, как использовать тип пользовательского устройства в качестве контекстных данных, чтобы сделать ваши рекомендации более актуальными. Использование контекстных метаданных для обучения моделей Amazon Personalize поможет вам рекомендовать продукты, актуальные как для новых, так и для существующих пользователей, не только из данных профиля, но и из платформы устройства просмотра. Мало того, такой контекст, как местоположение (страна, город, регион, почтовый индекс) и время (день недели, выходные, будний день, сезон), открывает возможность давать рекомендации, относящиеся к пользователю. Вы можете запустить полный пример кода, используя шаблон CloudFormation, представленный в нашем Репозиторий GitHub и клонирование блокнотов в Amazon SageMaker Studio.
Об авторах
 Жиль-Кюссан Сатчиви является архитектором корпоративных решений AWS с опытом работы в области сетей, инфраструктуры, безопасности и ИТ-операций. Он увлечен тем, что помогает клиентам создавать системы Well-Architected на AWS. До прихода в AWS он 17 лет работал в сфере электронной коммерции. Вне работы он любит проводить время со своей семьей и болеть за свою детскую футбольную команду.
Жиль-Кюссан Сатчиви является архитектором корпоративных решений AWS с опытом работы в области сетей, инфраструктуры, безопасности и ИТ-операций. Он увлечен тем, что помогает клиентам создавать системы Well-Architected на AWS. До прихода в AWS он 17 лет работал в сфере электронной коммерции. Вне работы он любит проводить время со своей семьей и болеть за свою детскую футбольную команду.
 Адитья Пендьяла является старшим архитектором решений в AWS из Нью-Йорка. Он имеет большой опыт в разработке облачных приложений. В настоящее время он работает с крупными предприятиями, помогая им создавать масштабируемые, гибкие и отказоустойчивые облачные архитектуры, а также консультирует их по всем вопросам, связанным с облаком. Он имеет степень магистра компьютерных наук Шиппенсбургского университета и верит в цитату: «Когда вы перестаете учиться, вы перестаете расти».
Адитья Пендьяла является старшим архитектором решений в AWS из Нью-Йорка. Он имеет большой опыт в разработке облачных приложений. В настоящее время он работает с крупными предприятиями, помогая им создавать масштабируемые, гибкие и отказоустойчивые облачные архитектуры, а также консультирует их по всем вопросам, связанным с облаком. Он имеет степень магистра компьютерных наук Шиппенсбургского университета и верит в цитату: «Когда вы перестаете учиться, вы перестаете расти».
 Прабхакар Чандрашекаран является старшим техническим менеджером по работе с клиентами в службе поддержки AWS Enterprise. Прабхакару нравится помогать клиентам создавать передовые решения AI/ML в облаке. Он также работает с корпоративными клиентами, предоставляя упреждающие рекомендации и оперативную помощь, помогая им повышать ценность своих решений при использовании AWS. Прабхакар имеет шесть сертификатов AWS и шесть других профессиональных сертификатов. Обладая более чем 20-летним профессиональным опытом, Прабхакар до прихода в AWS был инженером данных и руководителем программы в сфере финансовых услуг.
Прабхакар Чандрашекаран является старшим техническим менеджером по работе с клиентами в службе поддержки AWS Enterprise. Прабхакару нравится помогать клиентам создавать передовые решения AI/ML в облаке. Он также работает с корпоративными клиентами, предоставляя упреждающие рекомендации и оперативную помощь, помогая им повышать ценность своих решений при использовании AWS. Прабхакар имеет шесть сертификатов AWS и шесть других профессиональных сертификатов. Обладая более чем 20-летним профессиональным опытом, Прабхакар до прихода в AWS был инженером данных и руководителем программы в сфере финансовых услуг.