
- 21 января 2018 г.
- Василис Вриниотис
- . 1 Комментарий
 Глубокое обучение (любимое модное словечко конца 2010-х наряду с блокчейном/биткойном и наукой о данных/машинном обучении) позволило нам сделать несколько действительно крутых вещей за последние несколько лет. Помимо достижений в алгоритмах (которые, по общему признанию, основаны на идеях, уже известных с 1990-х годов, известных как «эра интеллектуального анализа данных»), основными причинами его успеха можно назвать доступность больших бесплатных наборов данных, введение библиотек с открытым исходным кодом и использование графических процессоров. В этом посте я сосредоточусь на последних двух и поделюсь с вами некоторыми советами, которые я усвоил на собственном горьком опыте.
Глубокое обучение (любимое модное словечко конца 2010-х наряду с блокчейном/биткойном и наукой о данных/машинном обучении) позволило нам сделать несколько действительно крутых вещей за последние несколько лет. Помимо достижений в алгоритмах (которые, по общему признанию, основаны на идеях, уже известных с 1990-х годов, известных как «эра интеллектуального анализа данных»), основными причинами его успеха можно назвать доступность больших бесплатных наборов данных, введение библиотек с открытым исходным кодом и использование графических процессоров. В этом посте я сосредоточусь на последних двух и поделюсь с вами некоторыми советами, которые я усвоил на собственном горьком опыте.
Почему TensorFlow и Keras?
ТензорФлоу — это очень популярная библиотека глубокого обучения, разработанная Google, которая позволяет быстро создавать прототипы сложных сетей. Он поставляется с множеством интересных функций, таких как автоматическое дифференцирование (что избавляет вас от оценки/кодирования градиентов функций стоимости) и поддержка графического процессора (что позволяет вам легко получить 200-кратное улучшение скорости с использованием достойного оборудования). Кроме того, он предлагает интерфейс Python, что означает, что вы можете быстро создавать прототипы, не требуя написания кода C или CUDA. По общему признанию, есть много других фреймворков, которые можно использовать вместо TensorFlow, таких как Torch, MXNet, Theano, Caffe, Deeplearning4j, CNTK и т. д., но все сводится к вашему варианту использования и вашим личным предпочтениям.
Но почему Керас? Для меня использование TF напрямую похоже на машинное обучение с Numpy. Да, это осуществимо, и время от времени вам приходится это делать (особенно если вы пишете собственные слои/функции потерь), но действительно ли вы хотите писать код, описывающий сложные сети как серию векторных операций (да, я знаю в ТФ есть высокоуровневые методы но они не такие крутые как Керас)? И что, если вы хотите перейти в другую библиотеку? Ну, тогда вам, вероятно, придется переписать код, что отстой. Та та тааа, Керас спешит на помощь! Keras позволяет вам описывать ваши сети, используя концепции высокого уровня, и писать код, который не зависит от серверной части, что означает, что вы можете запускать сети в разных библиотеках глубокого обучения. Что мне нравится в Keras, так это то, что он хорошо написан, имеет объектно-ориентированную архитектуру, легко вносить свой вклад и имеет дружелюбное сообщество. Если вам понравилось, скажите спасибо Франсуа Шолле за его разработку и открытие исходного кода.
Советы и подсказки по обучению работе с несколькими графическими процессорами
Без дальнейших церемоний, давайте перейдем к нескольким советам о том, как максимально эффективно использовать обучение графическому процессору в Keras, и к нескольким подводным камням, которые вы должны иметь в виду:
1. Обучение на нескольких GPU не происходит автоматически
Обучение моделей на графическом процессоре с использованием Keras и Tensorflow происходит без проблем. Если у вас есть карта NVIDIA и вы установили CUDA, библиотеки автоматически обнаружат ее и будут использовать для обучения. Так круто! Но что, если вы избалованный ребенок и у вас несколько графических процессоров? Что ж, к сожалению, вам придется немного поработать, чтобы добиться обучения с несколькими графическими процессорами.![]()
Существует несколько способов распараллеливания сети в зависимости от того, чего вы хотите достичь, но два основных подхода — это распараллеливание модели и данных. Первый может помочь вам, если ваша модель слишком сложна для одного графического процессора, а второй помогает, когда вы хотите ускорить выполнение. Обычно, когда люди говорят об обучении с использованием нескольких графических процессоров, они имеют в виду последнее. Раньше этого было сложнее достичь, но, к счастью, Keras недавно включил служебный метод под названием mutli_gpu_model что упрощает параллельное обучение/прогнозирование (в настоящее время доступно только с бэкэндом TF). Основная идея заключается в том, что вы передаете свою модель через метод, и она копируется на разные графические процессоры. Исходный ввод разбивается на фрагменты, которые передаются на различные графические процессоры, а затем объединяются в один вывод. Этот метод можно использовать для достижения параллельного обучения и прогнозирования, однако имейте в виду, что для обучения он не масштабируется линейно с количеством графических процессоров из-за необходимой синхронизации.
2. Обратите внимание на размер партии
Когда вы выполняете обучение с несколькими графическими процессорами, обратите внимание на размер пакета, так как он оказывает множественное влияние на скорость/память, конвергенцию вашей модели, и если вы не будете осторожны, вы можете повредить вес вашей модели!
Скорость/память: Очевидно, что чем больше партия, тем быстрее обучение/прогнозирование. Это связано с тем, что при вводе и извлечении данных из графических процессоров возникают накладные расходы, поэтому небольшие пакеты имеют больше накладных расходов. С другой стороны, чем больше пакет, тем больше памяти вам нужно для графического процессора. Особенно во время обучения входные данные каждого слоя хранятся в памяти, поскольку они требуются на этапе обратного распространения, поэтому слишком большое увеличение размера пакета может привести к ошибкам нехватки памяти.
Конвергенция: Если вы используете Stochastic Gradient Decent (SGD) или некоторые из его вариантов для обучения вашей модели, вы должны иметь в виду, что размер пакета может повлиять на способность вашей сети сходиться и обобщать. Типичные размеры пакетов для многих задач компьютерного зрения составляют от 32 до 512 примеров. Как Кескар и др. выразился так: «На практике было замечено, что при использовании большей партии (чем 512) происходит ухудшение качества модели, измеряемое ее способностью к обобщению». Обратите внимание, что другие оптимизаторы имеют другие свойства, и специализированные методы распределенной оптимизации могут помочь решить эту проблему. Если вас интересуют математические подробности, рекомендую прочитать «Тезис Джоэри Херманса».О масштабируемом глубоком обучении и распараллеливании градиентного спуска».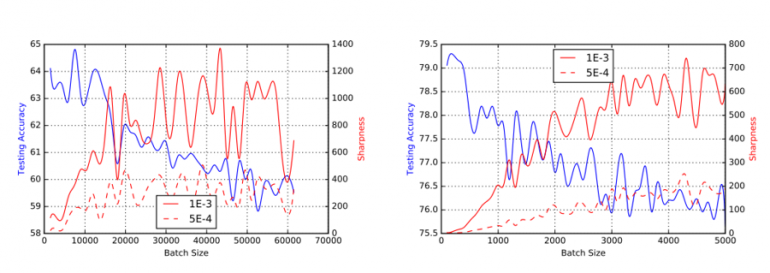
Искажение весов: Это неприятная техническая деталь, которая может иметь разрушительные последствия. Когда вы проводите обучение с несколькими графическими процессорами, важно подавать данные на все графические процессоры. Может случиться так, что самый последний пакет вашей эпохи содержит меньше данных, чем определено (поскольку размер вашего набора данных не может быть точно разделен на размер вашего пакета). Это может привести к тому, что некоторые графические процессоры не получат никаких данных на последнем шаге. К сожалению, некоторые слои Keras, в первую очередь слой пакетной нормализации, не могут справиться с этим, что приводит к появлению значений nan в весах (скользящее среднее и дисперсия в слое BN). Чтобы сделать вещи еще более неприятными, проблема не будет наблюдаться во время обучения (пока фаза обучения равна 1), потому что конкретный слой использует среднее/дисперсию партии в оценках. Тем не менее, во время прогнозов (фаза обучения установлена на 0) используется скользящее среднее / дисперсия, что в нашем случае может стать nan, что приведет к плохим результатам. Так что сделайте себе одолжение и всегда следите за тем, чтобы размер вашего пакета был фиксированным, когда вы проводите обучение с несколькими графическими процессорами. Этого можно добиться двумя простыми способами: либо отбрасывая пакеты, не соответствующие предварительно определенному размеру, либо повторяя записи в пакете до тех пор, пока не будет достигнут заданный размер. И последнее, но не менее важное: имейте в виду, что в конфигурации с несколькими графическими процессорами размер пакета должен быть кратен количеству доступных графических процессоров в вашей системе.
3. Нехватка данных графического процессора, иначе говоря, процессоры не поспевают за графическими процессорами.
Как правило, самая дорогая часть при обучении/прогнозировании глубоких сетей — это оценка, которая происходит на графических процессорах. Данные предварительно обрабатываются центральными процессорами в фоновом режиме и периодически передаются на графические процессоры. Тем не менее, не следует недооценивать скорость графических процессоров; может случиться так, что если ваша сеть слишком мелкая или этап предварительной обработки слишком сложен, ваши процессоры не могут идти в ногу с вашими графическими процессорами или, другими словами, они не передают им данные достаточно быстро. Это может привести к низкому использованию графического процессора, что означает напрасную трату денег/ресурсов.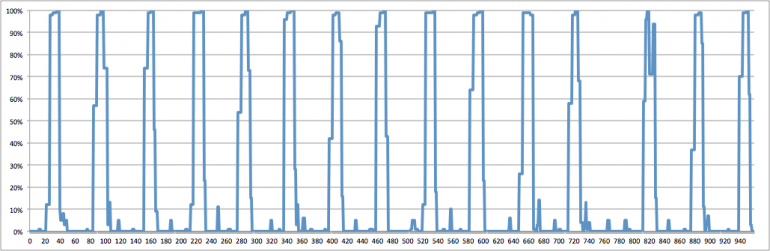
Keras обычно выполняет оценку пакетов параллельно, однако из-за Python GIL (Global Interpreter Lock) вы не можете добиться настоящей многопоточности в Python. Для этого есть два решения: либо использовать несколько процессов (обратите внимание, что в этом есть много ошибок, которые я не собираюсь здесь описывать), либо сделать шаг предварительной обработки простым. В прошлом я отправлял запрос на включение в Keras, чтобы уменьшить часть ненужной нагрузки, которую мы оказывали на ЦП во время предварительной обработки изображения, поэтому большинство пользователей не должны быть затронуты, если они используют стандартные генераторы. Если у вас есть собственные генераторы, постарайтесь передать как можно больше логики в библиотеки C, такие как Numpy, потому что некоторые из этих методов на самом деле выпустить ГИЛ что означает, что вы можете увеличить степень распараллеливания. Хороший способ определить, сталкиваетесь ли вы с нехваткой данных графического процессора, — это отслеживать использование графического процессора, однако имейте в виду, что это не единственная причина наблюдения (синхронизация, которая происходит во время обучения между несколькими графическими процессорами, также виновата в низком использовании). ). Обычно нехватку данных графического процессора можно обнаружить, наблюдая за всплесками графического процессора, за которыми следуют длительные паузы без использования. В прошлом у меня было расширение с открытым исходным кодом для Dstat, которое может помочь вам измерить использование вашего графического процессора, так что взгляните на исходную запись в блоге.
4. Сохранение ваших параллельных моделей
Допустим, вы использовали метод mutli_gpu_model для распараллеливания модели, обучение завершено и теперь вы хотите сохранить ее веса. Плохая новость заключается в том, что вы не можете просто вызвать save(). В настоящее время у Keras есть ограничение, которое не позволяет вам сохранить параллельную модель. Есть 2 способа обойти это: либо вызвать save() для ссылки на исходную модель (веса будут обновлены автоматически), либо вам нужно сериализовать модель, убрав параллельную версию и очистив все ненужные соединения. Первый вариант намного проще, но в будущем я планирую открыть исходный код метода serialize(), который выполняет последний.
5. Подсчет доступных графических процессоров имеет неприятный побочный эффект
К сожалению, на данный момент существует неприятный побочный эффект метода tensorflow.python.client.device_lib.list_local_devices(), который вызывает создание нового сеанса TensorFlow и инициализацию всех доступных графических процессоров в системе. Это может привести к неожиданным результатам, таким как просмотр большего количества графических процессоров, чем указано, или преждевременная инициализация новых сеансов (вы можете прочитать все подробности на этом пул-реквест). Чтобы избежать подобных сюрпризов, вам рекомендуется вместо этого использовать метод Keras K.get_session().list_devices(), который вернет вам все зарегистрированные в настоящее время графические процессоры в сеансе. И последнее, но не менее важное: имейте в виду, что вызов метода list_devices() несколько дорог, поэтому, если вас просто интересует количество доступных графических процессоров, вызовите метод один раз и сохраните их количество в локальной переменной.
Вот и все! Надеюсь, вы нашли этот список полезным. Если вы нашли другие подсказки/советы по обучению графическому процессору в Keras, поделитесь ими ниже в комментариях. 🙂