
Компании в различных отраслях создают, сканируют и хранят большие объемы PDF-документов. Во многих случаях контент содержит много текста и часто написан на другом языке и требует перевода. Чтобы решить эту проблему, вам необходимо автоматизированное решение для извлечения содержимого из этих PDF-файлов и его быстрого и экономичного перевода.
Многие компании имеют разных пользователей по всему миру и нуждаются в переводе текста, чтобы обеспечить межъязыковое общение между ними. Это ручное, медленное и дорогое человеческое усилие. Необходимо найти масштабируемое, надежное и экономичное решение для перевода документов с сохранением исходного форматирования документа.
Для таких вертикалей, как здравоохранение, из-за нормативных требований переведенные документы требуют дополнительного человека для проверки действительности документа, переведенного с помощью машины.
Если переведенный документ не сохраняет исходное форматирование и структуру, он теряет свой контекст. Это может затруднить рецензенту проверку и внесение исправлений.
В этом посте мы покажем, как создать новый переведенный PDF-файл из отсканированного PDF-файла, сохранив при этом исходную структуру и форматирование документа, используя подход на основе геометрии с помощью Amazon Textract, Amazon Translate и Апач PDFBox.
Обзор решения
Решение, представленное в этом посте, использует следующие компоненты:
- Амазонка Текст – Полностью управляемая служба машинного обучения (ML), которая автоматически извлекает печатный текст, рукописный текст и другие данные из отсканированных документов, что выходит за рамки простого оптического распознавания символов (OCR) для идентификации, понимания и извлечения данных из форм и таблиц. Amazon Textract может обнаруживать текст в различных документах, включая финансовые отчеты, медицинские записи и налоговые формы.
- Амазон Переводчик – Служба нейронного машинного перевода, обеспечивающая быстрый, качественный и доступный языковой перевод. Amazon Translate предоставляет возможности высококачественного перевода по требованию и пакетного перевода для более чем 2970 языковых пар, снижая при этом ваши затраты на перевод.
- PDF-перевод – Библиотека с открытым исходным кодом, написанная на Java и опубликованная на Примеры AWS на GitHub. Эта библиотека содержит логику для создания переведенных PDF-документов на нужный язык с помощью Amazon Textract и Amazon Translate. Он также использует библиотеку Java с открытым исходным кодом Apache PDFBox для создания документов PDF. Существуют аналогичные библиотеки обработки PDF, доступные на других языках программирования, например Узел PDFBox.
При выполнении машинного перевода у вас могут возникнуть ситуации, когда вы захотите сохранить от перевода определенные части текста, например имена или уникальные идентификаторы. Amazon Translate позволяет изменять теги, что позволяет указать, какой текст не следует переводить. Amazon Translate также поддерживает настройку формальностей, что позволяет настроить уровень формальности при переводе.
Подробнее об ограничениях Amazon Textract см. в разделе Квоты в Amazon Textract.
Решение ограничено языками, которые может извлекать Amazon Textract, который в настоящее время поддерживает английский, испанский, итальянский, португальский, французский и немецкий языки. Эти языки также поддерживаются Amazon Translate. Полный список языков, поддерживаемых Amazon Translate, см. в разделе Поддерживаемые языки и языковые коды.
Мы используем следующий PDF-файл, чтобы продемонстрировать перевод текста с английского на испанский. Решение также поддерживает создание переведенного документа без какого-либо форматирования. Позиция переведенного текста сохраняется. Исходные и переведенные PDF-документы также можно найти в Репозиторий AWS Samples на GitHub.
В следующих разделах мы покажем, как запустить код перевода на локальном компьютере, и рассмотрим код перевода более подробно.

Предпосылки
Прежде чем приступить к работе, настройте свою учетную запись AWS и интерфейс командной строки AWS (AWS CLI). Для доступа к любым сервисам AWS, таким как Textract и Translate, необходимы соответствующие разрешения IAM. Мы рекомендуем использовать разрешения с наименьшими привилегиями. Чтобы узнать больше о разрешениях IAM, см. Политики и разрешения в IAM, а также Как Amazon Textract работает с IAM и Как Amazon Translate работает с IAM.
Запустите код перевода на локальном компьютере
Это решение ориентировано на автономный код Java для извлечения и перевода PDF-документа. Это сделано для упрощения тестирования и настройки, чтобы получить переведенный PDF-документ с наилучшей визуализацией. Затем код можно интегрировать в автоматизированное решение для развертывания и запуска в AWS. См. раздел Перевод документов PDF с помощью Amazon Translate и Amazon Textract для примера архитектуры, использующей Amazon Simple Storage Service (Amazon S3) для хранения документов и AWS Lambda для выполнения кода.
Чтобы запустить код на локальном компьютере, выполните следующие шаги. Примеры кода доступны на Репозиторий GitHub.
- Клонируйте репозиторий GitHub:
- Выполните следующую команду:
- Запустите следующую команду для перевода с английского на испанский:
В папке документов создаются два переведенных PDF-документа с исходным форматированием и без него (SampleOutput-es.pdf и SampleOutput-min-es.pdf).
Код для создания переведенного PDF
В следующих фрагментах кода показано, как взять PDF-документ и создать соответствующий переведенный PDF-документ. Он извлекает текст с помощью Amazon Textract и создает переведенный PDF-файл, добавляя переведенный текст в виде слоя к изображению. Он основан на решении, показанном в публикации Автоматическое создание PDF-файлов с возможностью поиска из отсканированных документов с помощью Amazon Textract..
Сначала код получает каждую строку текста с помощью Amazon Textract. Amazon Translate используется для получения переведенного текста и сохранения геометрии переведенного текста.
Размер шрифта рассчитывается следующим образом и может быть легко настроен:
Переведенный PDF создается из сохраненной геометрии и переведенного текста. Изменения цвета переведенного текста можно легко настроить.
На следующем изображении показан документ, переведенный на испанский язык с исходным форматированием (SampleOutput-es.pdf).
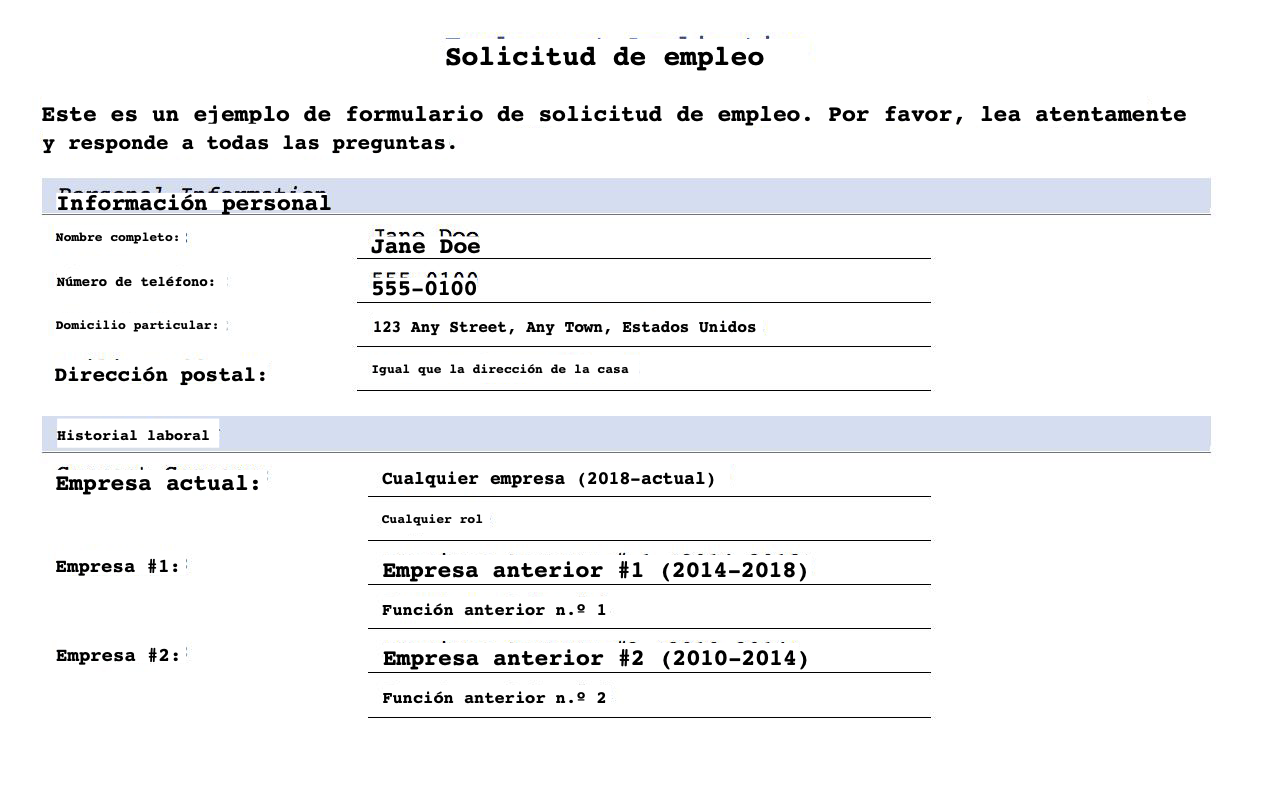
На следующем изображении показан переведенный PDF-файл на испанский язык без какого-либо форматирования (SampleOutput-min-es.pdf).

Время обработки
Заявление о приеме на работу в формате pdf заняло около 10 секунд, чтобы извлечь, обработать и отобразить переведенный pdf. Время обработки тяжелого текстового документа, такого как Декларация независимости PDF занял меньше минуты.
Расходы
С Amazon Textract вы платите по мере использования в зависимости от количества обработанных страниц и изображений. С Amazon Translate вы платите по мере использования в зависимости от количества обработанных текстовых символов. Фактические затраты см. в ценах на Amazon Textract и Amazon Translate.
Заключение
В этом посте показано, как использовать Amazon Textract и Amazon Translate для создания переведенных PDF-документов с сохранением исходной структуры документа. Вы можете дополнительно обработать результаты Amazon Textract, чтобы улучшить качество перевода, например, извлеченные слова могут быть переданы через проверки орфографии на основе ML, такие как SymSpell для проверки данных или алгоритмы кластеризации могут использоваться для сохранения порядка чтения. Вы также можете использовать Amazon Augmented AI (Amazon A2I) для создания рабочих процессов проверки человеком, в которых вы можете использовать свою личную рабочую силу для проверки исходных и переведенных документов PDF, чтобы обеспечить большую точность и контекст. Чтобы приступить к работе, см. разделы «Разработка рабочих процессов проверки человеком с помощью Amazon Translate и Amazon Augmented AI» и «Создание рабочего процесса многоязычного перевода документов с настройкой для конкретного домена и языка».
Об авторах
 Анубха Сингхал является старшим облачным архитектором в Amazon Web Services в организации AWS Professional Services.
Анубха Сингхал является старшим облачным архитектором в Amazon Web Services в организации AWS Professional Services.
 Шон Лоуренс ранее был Front End Engineer в AWS. Он специализировался на разработке интерфейсов в организации AWS Professional Services и команде Amazon Privacy.
Шон Лоуренс ранее был Front End Engineer в AWS. Он специализировался на разработке интерфейсов в организации AWS Professional Services и команде Amazon Privacy.