
Способы предоставления данных в модель
Многие организации сейчас изучают возможности генеративного искусственного интеллекта для повышения своей эффективности и получения новых возможностей. В большинстве случаев, чтобы полностью раскрыть эти возможности, ИИ должен иметь доступ к соответствующим корпоративным данным. Большие языковые модели (LLM) обучаются на общедоступных данных (например, статьях Википедии, книгах, веб-индексе и т. д.), чего достаточно для многих приложений общего назначения, но существует множество других, которые сильно зависят от частных данных. особенно в корпоративной среде.
Существует три основных способа предоставления новых данных в модель:
- Предварительное обучение модели с нуля. Для большинства компаний это редко имеет смысл, поскольку это очень дорого и требует много ресурсов и технических знаний.
- Доработка существующего LLM общего назначения. Это может снизить требования к ресурсам по сравнению с предварительным обучением, но все равно требует значительных ресурсов и опыта. Точная настройка создает специализированные модели, которые имеют лучшую производительность в одной области, для которой она настроена, но могут иметь худшую производительность в других.
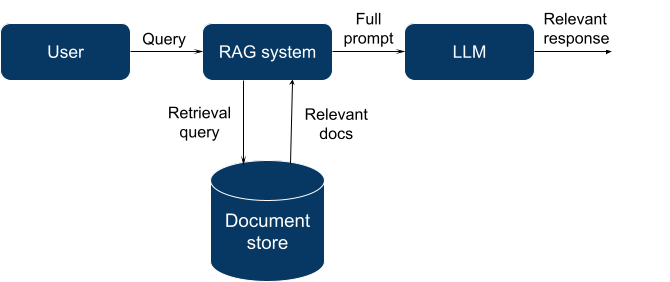
- Поисковая дополненная генерация (RAG). Идея состоит в том, чтобы получить данные, относящиеся к запросу, и включить их в контекст LLM, чтобы он мог «обосновать» свои собственные выходные данные на этой информации. Такие соответствующие данные в этом контексте называются «обоснованными данными». RAG дополняет общие модели LLM, но объем информации, которая может быть предоставлена, ограничен размером контекстного окна LLM (количество текста, которое LLM может обработать одновременно, когда информация генерируется).
В настоящее время RAG является наиболее доступным способом предоставления новой информации LLM, поэтому давайте сосредоточимся на этом методе и углубимся немного глубже.
Поисковая расширенная генерация
В общем, RAG означает использование поисковой или поисковой системы для получения соответствующего набора документов по заданному запросу.
Для этой цели мы можем использовать множество существующих систем: полнотекстовую поисковую систему (например, Elasticsearch + традиционные методы поиска информации), базу данных общего назначения с расширением векторного поиска (Postgres с pgvector, Elasticsearch с плагином векторного поиска) или специализированная база данных, созданная специально для поиска векторов.
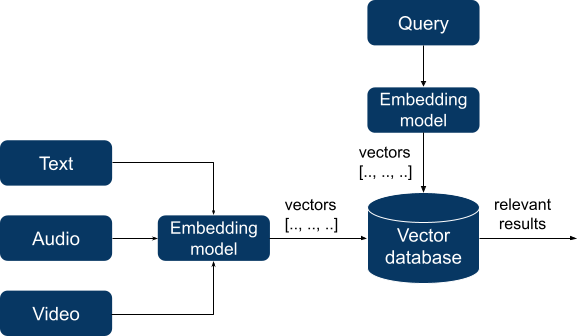
В двух последних случаях RAG аналогичен семантическому поиску. Долгое время семантический поиск был узкоспециализированной и сложной областью с экзотическими языками запросов и нишевыми базами данных. Индексирование данных потребовало тщательной подготовки и построения графиков знаний, но недавний прогресс в глубоком обучении резко изменил ситуацию. Современные приложения семантического поиска теперь зависят от моделей внедрения, которые успешно изучают семантические шаблоны в представленных данных. Эти модели принимают неструктурированные данные (текст, аудио или даже видео) в качестве входных данных и преобразуют их в векторы чисел фиксированной длины, превращая таким образом неструктурированные данные в числовую форму, которую можно использовать для вычислений. Затем становится возможным вычислить расстояние. между векторами с использованием выбранной метрики расстояния, и полученное расстояние будет отражать семантическое сходство между векторами и, в свою очередь, между частями исходных данных.
Эти векторы индексируются базой данных векторов и при запросе наш запрос также преобразуется в вектор. База данных ищет N ближайших векторов (в соответствии с выбранной метрикой расстояния, например, косинусным сходством) к вектору запроса и возвращает их.
База данных векторов отвечает за эти 3 вещи:
- Индексирование. База данных создает индекс векторов, используя какой-либо встроенный алгоритм (например, локально-зависимое хеширование (LSH) или иерархический навигационный малый мир (HNSW)) для предварительного вычисления данных для ускорения выполнения запросов.
- Запрос. База данных использует вектор запроса и индекс для поиска наиболее релевантных векторов в базе данных.
- Постобработка. После формирования набора результатов иногда нам может потребоваться выполнить дополнительный шаг, например, фильтрацию метаданных или повторное ранжирование в наборе результатов, чтобы улучшить результат.
Цель векторной базы данных — предоставить быстрый, надежный и эффективный способ хранения и запроса данных. На скорость поиска и качество поиска может влиять выбор типа индекса. Помимо уже упомянутых LSH и HNSW, есть и другие, каждый из которых имеет свой набор сильных и слабых сторон. Большинство баз данных делают выбор за нас, но в некоторых вы можете выбрать тип индекса вручную, чтобы контролировать компромисс между скоростью и точностью.
В DataRobot мы считаем, что эта технология никуда не денется. Точная настройка может потребовать очень сложной подготовки данных, чтобы превратить необработанный текст в данные, готовые к обучению, и уговаривать LLM «изучать» новые факты посредством точной настройки, сохраняя при этом свои общие знания и следовать инструкциям, — это скорее искусство, чем наука. поведение.
LLM, как правило, очень хорошо применяют знания, полученные в контексте, особенно когда предоставляется только самый релевантный материал, поэтому хорошая система поиска имеет решающее значение.
Обратите внимание, что выбор модели внедрения, используемой для RAG, имеет важное значение. Он не является частью базы данных, и выбор правильной модели внедрения для вашего приложения имеет решающее значение для достижения хорошей производительности. Кроме того, хотя новые и улучшенные модели выпускаются постоянно, переход на новую модель требует переиндексации всей базы данных.
Оценка ваших возможностей
Выбор базы данных в корпоративной среде – непростая задача. База данных часто является сердцем вашей программной инфраструктуры, которая управляет очень важным бизнес-активом: данными.
Обычно, когда мы выбираем базу данных, мы хотим:
- Надежное хранение
- Эффективные запросы
- Возможность детальной вставки, обновления и удаления данных (CRUD)
- Настройка нескольких пользователей с различными уровнями доступа для них (RBAC)
- Согласованность данных (предсказуемое поведение при изменении данных)
- Умение восстанавливаться после неудач
- Масштабируемость в соответствии с размером наших данных
Этот список не является исчерпывающим и может показаться очевидным, но не все новые векторные базы данных обладают этими функциями. Часто именно доступность корпоративных функций определяет окончательный выбор между хорошо известной зрелой базой данных, обеспечивающей векторный поиск с помощью расширений, и более новой базой данных, предназначенной только для векторов.
Базы данных, содержащие только векторные данные, имеют встроенную поддержку векторного поиска и могут выполнять запросы очень быстро, но часто не имеют корпоративных функций и являются относительно незрелыми. Имейте в виду, что на создание сложных функций и их боевое тестирование уходят годы, поэтому неудивительно, что первые пользователи сталкиваются с перебоями в работе и потерей данных. С другой стороны, в существующих базах данных, которые обеспечивают векторный поиск через расширения, вектор не является первоклассным гражданином, и производительность запросов может быть намного хуже.
Мы разделим все существующие базы данных, обеспечивающие поиск векторов, на следующие группы, а затем обсудим их более подробно:
- Библиотеки векторного поиска
- Векторные базы данных
- Базы данных NoSQL с векторным поиском
- Базы данных SQL с векторным поиском
- Решения для векторного поиска от облачных поставщиков
Библиотеки векторного поиска
Библиотеки векторного поиска, такие как FAISS и ANNOY, не являются базами данных — скорее, они предоставляют индексы векторов в памяти и лишь ограниченные возможности сохранения данных. Хотя эти функции не идеальны для пользователей, которым требуется полная корпоративная база данных, они обеспечивают очень быстрый поиск ближайших соседей и имеют открытый исходный код. Они предлагают хорошую поддержку многомерных данных и легко настраиваются (вы можете выбрать тип индекса и другие параметры).
В целом они хороши для прототипирования и интеграции в простые приложения, но непригодны для долговременного многопользовательского хранения данных.
Векторные базы данных
В эту группу входят разнообразные продукты, такие как Milvus, Chroma, Pinecone, Weaviate и другие. Между ними есть заметные различия, но все они специально предназначены для хранения и извлечения векторов. Они оптимизированы для эффективного поиска по сходству с индексированием и изначально поддерживают многомерные данные и векторные операции.
Большинство из них новы и могут не иметь упомянутых выше корпоративных функций, например, у некоторых из них нет CRUD, проверенного восстановления после сбоев, RBAC и т. д. По большей части они могут хранить необработанные данные, вектор внедрения и небольшой объем метаданных, но они не могут хранить другие типы индексов или реляционные данные, а это означает, что вам придется использовать другую, вторичную базу данных и поддерживать согласованность. между ними.
Их производительность часто не имеет себе равных, и они являются хорошим вариантом при наличии мультимодальных данных (изображений, аудио или видео).
Базы данных NoSQL с векторным поиском
Многие так называемые базы данных NoSQL недавно добавили векторный поиск в свои продукты, включая MongoDB, Redis, neo4j и ElasticSearch. Они предлагают хорошие корпоративные функции, являются зрелыми и имеют сильное сообщество, но предоставляют функции векторного поиска через расширения, что может привести к не идеальной производительности и отсутствию первоклассной поддержки векторного поиска. Elasticsearch выделяется здесь тем, что он предназначен для полнотекстового поиска и уже имеет множество традиционных функций поиска информации, которые можно использовать в сочетании с векторным поиском.
Базы данных NoSQL с векторным поиском — хороший выбор, если вы уже вложили в них средства и вам нужен векторный поиск как дополнительная, но не очень требовательная функция.
Базы данных SQL с векторным поиском
Эта группа чем-то похожа на предыдущую, но здесь у нас есть такие авторитетные игроки, как PostgreSQL и ClickHouse. Они предлагают широкий спектр корпоративных функций, хорошо документированы и имеют сильное сообщество. Что касается их недостатков, то они предназначены для структурированных данных, и их масштабирование требует определенных навыков.
Варианты их использования также аналогичны: хороший выбор, если они у вас уже есть и есть опыт для их запуска.
Решения для векторного поиска от облачных поставщиков
Гиперскейлеры также предлагают услуги векторного поиска. Обычно они имеют базовые функции для векторного поиска (вы можете выбрать модель внедрения, тип индекса и другие параметры), хорошую совместимость с остальной частью облачной платформы и большую гибкость с точки зрения стоимости, особенно если вы используете другие сервисы на их платформа. Однако они имеют разную зрелость и разные наборы функций: векторный поиск Google Cloud использует быстрый собственный алгоритм поиска по индексу под названием ScaNN и фильтрацию метаданных, но он не очень удобен для пользователя; Поиск Azure Vector предлагает возможности структурированного поиска, но находится на стадии предварительной версии и т. д.
Объектами векторного поиска можно управлять с помощью корпоративных функций их платформы, таких как IAM (управление идентификацией и доступом), но они не так просты в использовании и подходят для общего использования в облаке.
Правильный выбор
Основным вариантом использования векторных баз данных в этом контексте является предоставление модели соответствующей информации. Для вашего следующего проекта LLM вы можете выбрать базу данных из существующего массива баз данных, которые предлагают возможности поиска векторов через расширения, или из новых баз данных только для векторов, которые предлагают встроенную поддержку векторов и быстрые запросы.
Выбор зависит от того, нужны ли вам корпоративные функции или высокомасштабная производительность, а также от вашей архитектуры развертывания и желаемой зрелости (исследования, создание прототипов или производство). Также следует учитывать, какие базы данных уже присутствуют в вашей инфраструктуре и есть ли у вас мультимодальные данные. В любом случае, какой бы выбор вы ни сделали, полезно его подстраховать: рассматривайте новую базу данных как вспомогательный кэш хранилища, а не как центральную точку операций, и абстрагируйте операции с базой данных в коде, чтобы облегчить адаптацию к следующему. итерация векторного ландшафта RAG.
Как DataRobot может помочь
Существует уже так много вариантов баз данных векторов на выбор. У каждого из них есть свои плюсы и минусы: ни одна векторная база данных не подойдет для всех случаев использования генеративного ИИ в вашей организации. Вот почему важно сохранять опциональность и использовать решение, которое позволит вам адаптировать решения генеративного ИИ к конкретным сценариям использования и адаптироваться по мере изменения ваших потребностей или развития рынка.
Платформа DataRobot AI позволяет вам использовать собственную базу данных векторов — в зависимости от того, что подходит для создаваемого вами решения. Если вам потребуются изменения в будущем, вы можете заменить свою базу данных векторов, не нарушая при этом производственную среду и рабочие процессы.
Об авторе
Ник Волынец — старший инженер по данным, работающий в офисе технического директора, где ему нравится быть в центре инноваций DataRobot. Он интересуется крупномасштабным машинным обучением и увлечен искусственным интеллектом и его влиянием.
Знакомьтесь: Ник Волынец