
Мотивация
Доступ, понимание и извлечение информации из документов играют центральную роль в бесчисленных процессах в различных отраслях. Работаете ли вы в сфере финансов, здравоохранения, в семейном магазине ковров или студентом университета, бывают ситуации, когда вы видите большой документ, который вам нужно прочитать, чтобы ответить на вопросы. Познакомьтесь с JITR, революционным инструментом, который принимает файлы PDF и использует LLM (языковые модели языка) для ответа на запросы пользователей о контенте. Давайте исследуем магию JITR.
Что такое JITR?
JITR, что означает «Извлечение точно в срок», — это один из новейших инструментов в пакете DataRobot GenAI Accelerator, предназначенный для обработки PDF-документов, извлечения их содержимого и предоставления точных ответов на вопросы и запросы пользователей. Представьте себе, что у вас есть личный помощник, который может прочитать и понять любой PDF-документ, а затем мгновенно ответить на ваши вопросы о нем. Это JITR для вас.
Как работает JITR?
Вставка PDF-файлов: Начальный этап включает в себя загрузку PDF-файла в систему JITR. Здесь инструмент преобразует статическое содержимое PDF-файла в цифровой формат, воспринимаемый моделью внедрения. Модель внедрения преобразует каждое предложение в PDF-файле в вектор. Этот процесс создает векторную базу данных входного PDF-файла.
Применение вашего LLM: Как только контент будет принят, инструмент вызывает LLM. LLM — это современные модели искусственного интеллекта, обученные на огромных объемах текстовых данных. Они превосходно понимают контекст, распознают смысл и создают текст, похожий на человеческий. JITR использует эти модели для понимания и индексирования содержимого PDF-файла.
Интерактивный запрос: Затем пользователи могут задавать вопросы о содержании PDF-файла. LLM собирает соответствующую информацию и представляет ответы в краткой и последовательной форме.
Преимущества использования JITR
Каждая организация создает множество документов, которые создаются в одном отделе и потребляются другим. Часто поиск информации для сотрудников и команд может занять много времени. Использование JITR повышает эффективность работы сотрудников за счет сокращения времени просмотра объемных PDF-файлов и предоставления мгновенных и точных ответов на их вопросы. Кроме того, JITR может обрабатывать любой тип PDF-контента, что позволяет организациям встраивать и использовать его в различных рабочих процессах, не заботясь о входном документе.
Многие организации могут не иметь ресурсов и опыта в разработке программного обеспечения для разработки инструментов, использующих LLM в своем рабочем процессе. JITR позволяет командам и отделам, не владеющим Python, конвертировать PDF-файл в векторную базу данных в качестве контекста для LLM. Имея конечную точку для отправки PDF-файлов, JITR можно интегрировать в любое веб-приложение, такое как Slack (или другие инструменты обмена сообщениями), или внешние порталы для клиентов. Никаких знаний LLM, обработки естественного языка (NLP) или векторных баз данных не требуется.
Реальные приложения
Благодаря своей универсальности JITR можно интегрировать практически в любой рабочий процесс. Ниже приведены некоторые из приложений.
Бизнес-отчет: Профессионалы могут быстро получить ценную информацию из объемных отчетов, контрактов и технических документов. Аналогично, этот инструмент можно интегрировать во внутренние процессы, позволяя сотрудникам и командам взаимодействовать с внутренними документами.
Обслуживание клиентов: От понимания технических руководств до глубокого изучения учебных пособий — JITR может позволить клиентам взаимодействовать с руководствами и документами, связанными с продуктами и инструментами. Это может повысить удовлетворенность клиентов и сократить количество обращений в службу поддержки и эскалаций.
Исследования и разработки: Группы исследований и разработок могут быстро извлекать актуальную и удобоваримую информацию из сложных исследовательских работ для внедрения новейших технологий в продукт или внутренние процессы.
Соответствие рекомендациям: Во многих организациях есть рекомендации, которым должны следовать сотрудники и команды. JITR позволяет сотрудникам эффективно извлекать соответствующую информацию из руководств.
Юридические: JITR может принимать юридические документы и контракты и отвечать на вопросы на основе информации, представленной во входных документах.
Как создать бота JITR с помощью DataRobot
Рабочий процесс создания бота JITR аналогичен рабочему процессу развертывания любого конвейера LLM с использованием DataRobot. Два основных различия заключаются в следующем:
- Ваша векторная база данных определяется во время выполнения
- Вам нужна логика для обработки закодированного PDF-файла
Для последнего мы можем определить простую функцию, которая принимает кодировку и записывает ее обратно во временный PDF-файл в нашем развертывании.
```python
def base_64_to_file(b64_string, filename: str="temp.PDF", directory_path: str = "./storage/data") -> str:
"""Decode a base64 string into a PDF file"""
import os
if not os.path.exists(directory_path):
os.makedirs(directory_path)
file_path = os.path.join(directory_path, filename)
with open(file_path, "wb") as f:
f.write(codecs.decode(b64_string, "base64"))
return file_path
```
Определив эту вспомогательную функцию, мы можем пройти и создать наши перехватчики. Хуки — это просто причудливое словосочетание для функций с определенным именем. В нашем случае нам просто нужно определить крючок с именем load_model и еще один крючок с именем Score_unstructured. В `load_model` мы установим модель внедрения, которую мы хотим использовать для поиска наиболее релевантных фрагментов текста, а также LLM, который мы будем пинговать с помощью нашей контекстно-зависимой подсказки.
```python
def load_model(input_dir):
"""Custom model hook for loading our knowledge base."""
import os
import datarobot_drum as drum
from langchain.chat_models import AzureChatOpenAI
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
try:
# Pull credentials from deployment
key = drum.RuntimeParameters.get("OPENAI_API_KEY")("apiToken")
except ValueError:
# Pull credentials from environment (when running locally)
key = os.environ.get('OPENAI_API_KEY', '')
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2",
cache_folder=os.path.join(input_dir, 'storage/deploy/sentencetransformers')
)
llm = AzureChatOpenAI(
deployment_name=OPENAI_DEPLOYMENT_NAME,
openai_api_type=OPENAI_API_TYPE,
openai_api_base=OPENAI_API_BASE,
openai_api_version=OPENAI_API_VERSION,
openai_api_key=OPENAI_API_KEY,
openai_organization=OPENAI_ORGANIZATION,
model_name=OPENAI_DEPLOYMENT_NAME,
temperature=0,
verbose=True
)
return llm, embedding_function
```Итак, у нас есть функция внедрения и LLM. У нас также есть способ взять кодировку и вернуться к PDF-файлу. Итак, теперь мы переходим к сути бота JITR, где мы создадим наше векторное хранилище во время выполнения и будем использовать его для запроса LLM.
```python
def score_unstructured(model, data, query, **kwargs) -> str:
"""Custom model hook for making completions with our knowledge base.
When requesting predictions from the deployment, pass a dictionary
with the following keys:
- 'question' the question to be passed to the retrieval chain
- 'document' a base64 encoded document to be loaded into the vector database
datarobot-user-models (DRUM) handles loading the model and calling
this function with the appropriate parameters.
Returns:
--------
rv : str
Json dictionary with keys:
- 'question' user's original question
- 'answer' the generated answer to the question
"""
import json
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores.base import VectorStoreRetriever
from langchain.vectorstores.faiss import FAISS
llm, embedding_function = model
DIRECTORY = "./storage/data"
temp_file_name = "temp.PDF"
data_dict = json.loads(data)
# Write encoding to file
base_64_to_file(data_dict('document').encode(), filename=temp_file_name, directory_path=DIRECTORY)
# Load up the file
loader = PyPDFLoader(os.path.join(DIRECTORY, temp_file_name))
docs = loader.load_and_split()
# Remove file when done
os.remove(os.path.join(DIRECTORY, temp_file_name))
# Create our vector database
texts = (doc.page_content for doc in docs)
metadatas = (doc.metadata for doc in docs)
db = FAISS.from_texts(texts, embedding_function, metadatas=metadatas)
# Define our chain
retriever = VectorStoreRetriever(vectorstore=db)
chain = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever
)
# Run it
response = chain(inputs={'question': data_dict('question'), 'chat_history': ()})
return json.dumps({"result": response})
```Когда наши перехватчики определены, остается только развернуть наш конвейер, чтобы у нас была конечная точка, с которой люди могли бы взаимодействовать. Для некоторых процесс создания безопасной, контролируемой и запрашиваемой конечной точки из произвольного кода Python может показаться пугающим или, по крайней мере, трудоемким для настройки. Используя доктор package, мы можем развернуть нашего бота JITR за один вызов функции.
```python
import datarobotx as drx
deployment = drx.deploy(
"./storage/deploy/", # Path with embedding model
name=f"JITR Bot {now}",
hooks={
"score_unstructured": score_unstructured,
"load_model": load_model
},
extra_requirements=("pyPDF"), # Add a package for parsing PDF files
environment_id="64c964448dd3f0c07f47d040", # GenAI Dropin Python environment
)
```Как использовать JITR
Ладно, тяжелая работа окончена. Теперь мы можем наслаждаться взаимодействием с нашим новым развертыванием. С помощью Python мы снова можем воспользоваться преимуществами пакета drx, чтобы ответить на наши самые насущные вопросы.
```python
# Find a PDF
url = "https://s3.amazonaws.com/datarobot_public_datasets/drx/Instantnoodles.PDF"
resp = requests.get(url).content
encoding = base64.b64encode(io.BytesIO(resp).read()) # encode it
# Interact
response = deployment.predict_unstructured(
{
"question": "What does this say about noodle rehydration?",
"document": encoding.decode(),
}
)('result')
— – – –
{'question': 'What does this say about noodle rehydration?',
'chat_history': (),
'answer': 'The article mentions that during the frying process, many tiny holes are created due to mass transfer, and they serve as channels for water penetration upon rehydration in hot water. The porous structure created during frying facilitates rehydration.'}
```Но что еще более важно, мы можем выполнить развертывание на любом языке, который захотим, поскольку это всего лишь конечная точка. Ниже я показываю снимок экрана, на котором я взаимодействую с развертыванием прямо через Postman. Это означает, что мы можем интегрировать нашего JITR-бота практически в любое приложение, которое захотим, просто заставив приложение выполнить вызов API.
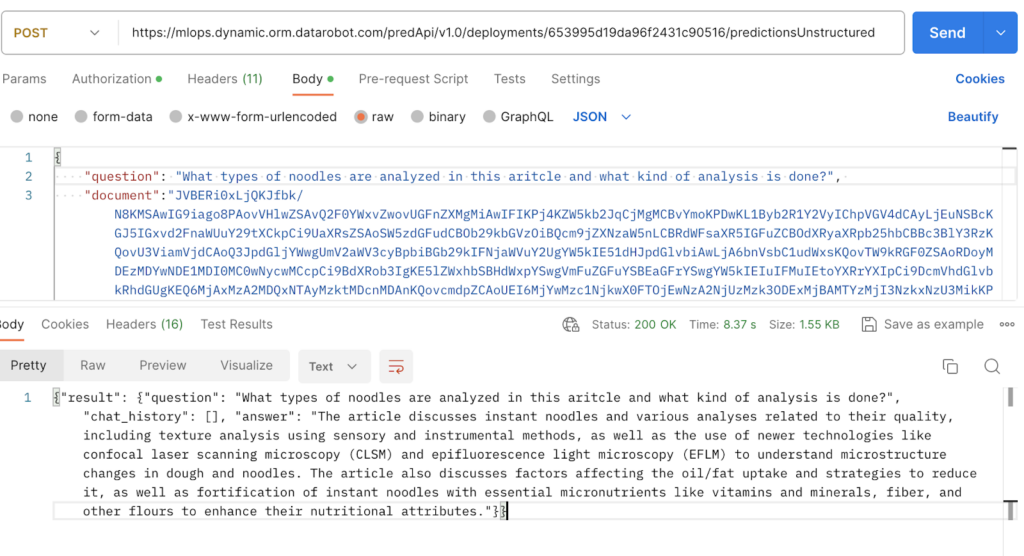
После внедрения в приложение использовать JITR становится очень просто. Например, в приложении Slackbot, используемом внутри DataRobot, пользователи просто загружают PDF-файл с вопросом, чтобы начать разговор, связанный с документом.
JITR позволяет любому сотруднику организации начать получать реальную пользу от генеративного искусственного интеллекта в бесчисленных точках взаимодействия в повседневных рабочих процессах сотрудников. Посмотрите это видео, чтобы узнать больше о JITR.
Что вы можете сделать, чтобы сделать бота JITR более мощным
В коде, который я показал, мы рассмотрели простую реализацию JITRBot, который принимает закодированный PDF-файл и сохраняет векторные данные во время выполнения, чтобы отвечать на вопросы. Поскольку они не имели отношения к основной концепции, я решил исключить ряд наворотов, которые мы реализовали внутри себя с помощью JITRBot, таких как:
- Возврат контекстно-зависимого приглашения и токенов завершения
- Ответы на вопросы, основанные на нескольких документах
- Отвечаем на несколько вопросов одновременно
- Разрешение пользователям предоставлять историю разговоров
- Использование других цепочек для разных типов вопросов
- Передача отчетов о пользовательских метриках обратно в развертывание
Также нет причин, по которым JITRBot должен работать только с файлами PDF! Пока документ можно закодировать и преобразовать обратно в текстовую строку, мы можем встроить в нашу систему больше логики. `score_unstructured` перехватчик для обработки любого типа файла, предоставленного пользователем.
Начните использовать JITR в своем рабочем процессе
JITR упрощает взаимодействие с произвольными PDF-файлами. Если вы хотите попробовать, вы можете следовать инструкциям в блокноте. здесь.