
Введение
Токенизация — обычная задача в обработке естественного языка (NLP). Это фундаментальный шаг как в традиционных методах НЛП, таких как векторизатор подсчета, так и в архитектурах на основе расширенного глубокого обучения, таких как трансформаторы.
Источник: Ютуб | Токенизация.
Токенизация
Токенизация — это способ разделения фрагмента текста на более мелкие единицы, называемые токенами. Здесь токенами могут быть слова, символы или подслова. Следовательно, токенизацию можно разделить на три типа: токенизацию слов, символов и подслов (n-граммных символов).
Читайте также: Использование искусственного интеллекта для повышения прибыльности издательского дела.

Например, рассмотрим предложение: «Никогда не теряй надежду».
Самый распространенный способ формирования токенов основан на пространстве. Если предположить, что в качестве разделителя используется пробел, токенизация предложения приводит к образованию трех токенов – «Никогда не теряй надежду». Поскольку каждый токен представляет собой слово, он становится примером токенизации слова.
Аналогично, токены могут быть либо символами, либо подсловами. Например, давайте рассмотрим «умнее»:
Жетоны персонажей: умнее
Токены подслов: умнее
Поскольку токены являются строительными блоками естественного языка, наиболее распространенный способ обработки необработанного текста происходит на уровне токенов.
Читайте также: Демократия победит с улучшенным искусственным интеллектом.
Трансформатор
Например, модели на основе Transformer — современные архитектуры глубокого обучения (SOTA) в NLP — обрабатывают необработанный текст на уровне токенов. Аналогичным образом, наиболее популярные архитектуры глубокого обучения для НЛП, такие как RNN, GRU и LSTM, также обрабатывают необработанный текст на уровне токенов.
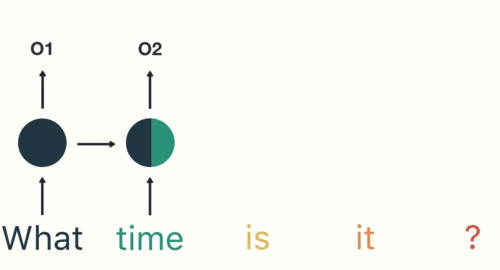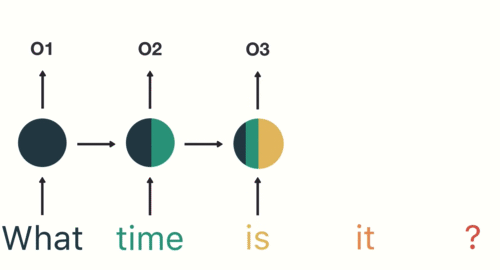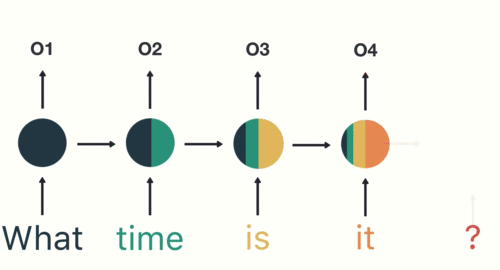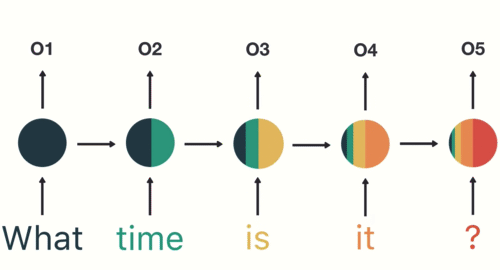
Следовательно, токенизация является основным шагом при моделировании текстовых данных. Токенизация выполняется в корпусе для получения токенов. Следующие токены затем используются для подготовки словаря. Словарь относится к набору уникальных токенов в корпусе. Помните, что словарный запас можно составить, рассматривая каждый уникальный токен в корпусе или рассматривая K самых часто встречающихся слов.
Читайте также: Робототехника и производство.
Теперь давайте разберемся в использовании словаря в традиционных и продвинутых методах НЛП, основанных на глубоком обучении.
Традиционные подходы НЛП, такие как Count Vectorizer и TF-IDF, используют словарь в качестве функций. Каждое слово в словаре рассматривается как уникальная особенность:
В архитектурах НЛП на основе расширенного глубокого обучения словарь используется для создания токенизированных входных предложений. Наконец, токены этих предложений передаются в качестве входных данных модели.
Заключение
Токенизация — это фундаментальный шаг в обработке естественного языка (NLP), который влияет на выполнение задач высокого уровня, таких как анализ настроений, языковой перевод и извлечение тем. Это процесс разбиения текста на более мелкие единицы или лексемы, такие как слова или фразы. Токенизация не только упрощает последующие процессы в конвейере НЛП, но также позволяет модели понять контекст и семантические отношения между словами.
Несмотря на кажущуюся простоту, токенизация позволяет обрабатывать сложные лингвистические нюансы и адаптироваться к различным языкам и текстовым структурам. Его важность в НЛП невозможно переоценить, поскольку качество токенизации напрямую влияет на эффективность всей системы НЛП. По мере дальнейшего развития искусственного интеллекта и машинного обучения ожидается появление более сложных методов токенизации, что еще больше повысит производительность систем НЛП.

Рекомендации
Бэндлер, Ричард и др. Полное введение в НЛП: как построить успешную жизнь. ХарперКоллинз, Великобритания, 2013.