
Одна вещь, которую мы узнали от наших клиентов, заключается в том, что им часто нужно больше, чем точечные прогнозы, чтобы принимать обоснованные решения. Примером таких точечных прогнозов может быть прогноз температуры (регрессия). Но что, если, помимо ожидаемой температуры, мы хотим предсказать вероятность для каждой температуры? В этом случае мы будем использовать прогнозы распределения. Но многие из самых мощных моделей машинного обучения не дают распределений в своих прогнозах. DataRobot еще раз расширяет границы возможного, предоставляя нашим клиентам эту важную возможность. В этой статье мы выделим один простой, но мощный подход к моделированию в условиях неопределенности: квантильная регрессия.
DataRobot уже поддерживает вероятности класса для многоклассового предсказания. Мы также предлагаем интервалы прогнозирования для временных рядов. Интервалы прогнозирования дают диапазон значений для всего распределения будущих наблюдений. Они часто применяются в таких областях, как финансы и эконометрика. Распределительная регрессия идет на шаг дальше, чем интервалы прогнозирования. Он оценивает распределение целевой переменной для каждого прогноза. Другой способ моделирования условного распределения — квантильная регрессия. Как следует из названия, он оценивает набор квантилей. Это проще сделать, чем прогнозы распределения, но помогает нам оценить полное распределение.
Небольшое напоминание: квантиль разбивает значения на подмножества заданного размера. Например, для q = 0,5 квантиль является медианой, а 50% точек данных находятся ниже, а 50% выше квантиля. Для q = 0,99 у нас есть 99-й процентиль, и только 1% данных находится выше этой линии.
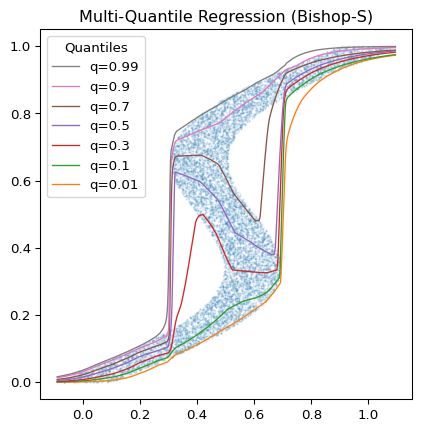
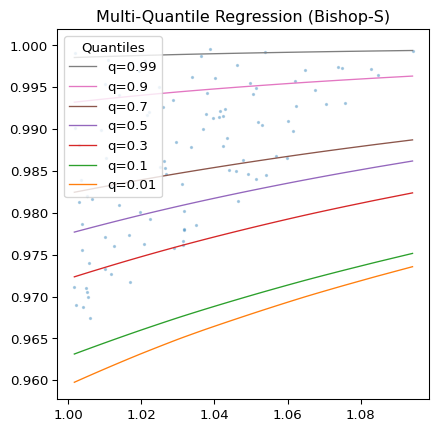
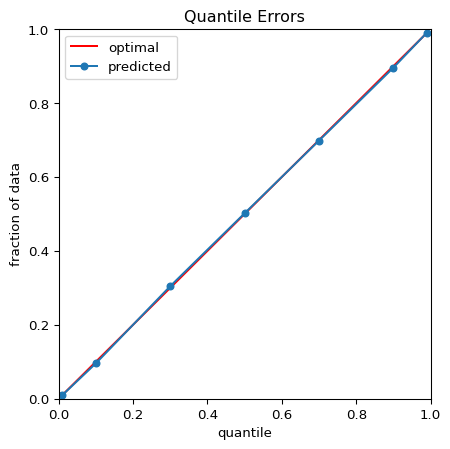
На рисунке 1 показаны результаты квантильной регрессии с использованием глубокие квантили Пакет Python и набор данных Bishop-S.1 Рисунок 2 приближается к верхнему правому углу графика с рисунка 1. Здесь распределение довольно гетероскедастично, но модель успешно избегает пересечения квантилей. На рисунке 3 показано, что квантили, предсказанные моделью, разделяют нашу случайную тестовую выборку как требуется.
Глубокое обучение для квантильной регрессии
Есть много способов включить неопределенность в прогнозы. Например, классическими примерами моделирования в условиях неопределенности являются модели временных рядов, такие как ARIMA.2 и ГАРЧ3 или, совсем недавно, NGBoost.4 Но что, если вы хотите использовать другую модель, которая соответствует вашей задаче, или, возможно, более производительную модель? Модели глубокого обучения могут различными способами помочь в моделировании в условиях неопределенности. Например, отдельная модель глубокого обучения может научиться прогнозировать квантили на основе прогнозов базовой модели. Таким образом, мы могли бы добавлять квантили во всевозможные интересные модели, которые не поддерживают это по умолчанию. В качестве первого шага мы с моим коллегой Питером Преттенхофером исследовали, насколько хорошо модели глубокого обучения предсказывают квантили различных целевых распределений напрямую, а не поверх предсказаний другой модели.
В прошлом специалисты-практики избегали моделей глубокого обучения для моделирования неопределенностей. Модели глубокого обучения было сложно интерпретировать, они были чувствительны к гиперпараметрам и требовали большого количества данных и времени на обучение. Теперь архитектура трансформатора.5 находится в центре внимания и поддерживает такие успешные инструменты, как ChatGPT. Несколько лет назад архитектура преобразователя в основном использовалась для построения больших языковых моделей (LLM). Теперь понятно, что его можно использовать и с табличными данными.6
В нашем исследовании мы адаптировали два существующих решения для наших целей, чтобы сравнить их с квантилями, которые мы получаем из прогнозируемых распределений NGBoost, используя функцию процентной точки:
- Пользовательский многоквантильный регрессор DeepQuantiles с архитектурой, похожей на многоквантильный регрессор из глубокие квантили Пакет Python. Это пример классической многослойной нейронной сети.
- FTTransformer,7 который использует архитектуру преобразователя, как в современных больших языковых моделях, но со специальным токенизатором для числовых и категориальных данных.
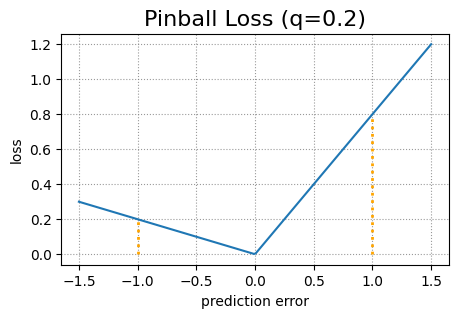
Обе модели глубокого обучения используют измененную функцию потери пинбола, чтобы лучше справляться с проблемой пересечения квантилей. Исходная функция потерь пинбола — это стандартная функция потерь, используемая для квантильной регрессии. Он состоит из двух частей. Пусть y будет истинным целевым значением, а ŷ – прогнозируемым целевым значением. Тогда потеря пинбола для данного квантиля q равна (1 – q)(ŷ – y) в случае y < ŷ и q(y – ŷ) в случае y ≥ ŷ.
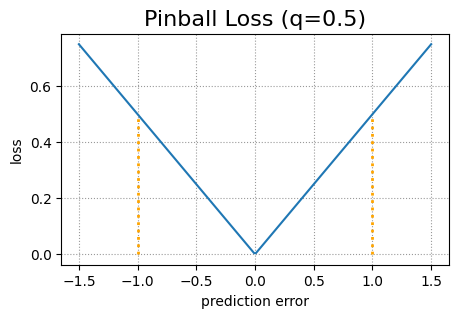
Сравнение
Ниже вы видите результаты для восьми общедоступных наборов данных, которые часто используются для регрессионного анализа с числовыми и категориальными переменными и от 506 до 11934 строк.
| ИДЕНТИФИКАТОР | # Строки | # Категориальный | # Числовой | # Ценности |
| Эймс-жилье | 1460 | 43 | 37 | 116 800 |
| конкретный | 1030 | 0 | 8 | 8240 |
| энергия | 768 | 0 | 8 | 6144 |
| Корпус | 506 | 0 | 13 | 6578 |
| kin8nm | 8192 | 0 | 8 | 65 536 |
| военно-морской | 11 934 | 0 | 16 | 190 944 |
| власть | 9 568 | 0 | 4 | 38 272 |
| вино | 1599 | 0 | 11 | 17 589 |
Графики ниже показывают производительность вне выборки для трех моделей NGBoost, DeepQuantiles и FTTransformer. Мы выбрали квантили 0,01, 0,1, 0,3, 0,5, 0,7, 0,9 и 0,99. Для каждой модели мы провели 20-кратную перекрестную проверку с 5 повторениями. Это означает 100 запусков на набор данных. Точки изображают средние предсказанные квантили. Столбики погрешностей представляют собой стандартные отклонения, а не стандартные ошибки.
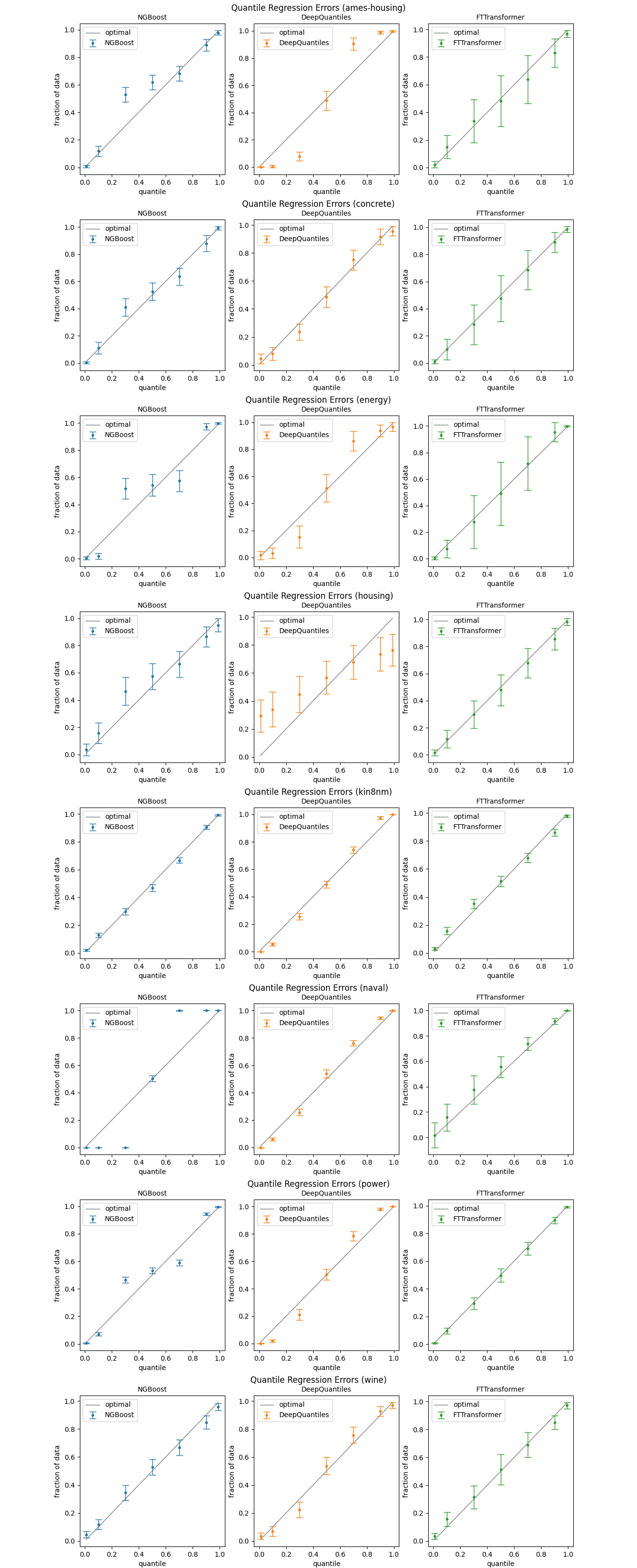
Наблюдения
NGBoost неплохо справляется со своей задачей, но, судя по всему, у него есть проблемы с некоторыми наборами данных (амес-жилье, энергетика, военно-морской флот, мощность). DeepQuantiles кажется немного сильнее, но также и разочаровывает в нескольких случаях (жилье, энергия, жилье). FTTransformer дает в среднем очень хорошие результаты, но с огромной дисперсией.
Одним из недостатков NGBoost является то, что он требует от нас заранее указать тип дистрибутива. Мы не делали никаких дополнительных предположений и использовали только нормальное распределение по умолчанию. Это может быть причиной того, что NGBoost довольно плохо работает с некоторыми наборами данных. Учитывая, что производительность DeepQuantiles весьма чувствительна к выбору его гиперпараметров, он не является хорошей альтернативой NGBoost. Во многих ситуациях ансамбль FTTransformers может быть хорошим способом проведения квантильной регрессии. Модель также не так чувствительна к выбору гиперпараметров и довольно быстро обучается.
Заключение
Мы постоянно стремимся использовать знания наших клиентов в DataRobot, и моделирование в условиях неопределенности, несомненно, является очень важной возможностью, которую мы изучаем. В этом исследовании мы увидели, что квантильная регрессия — это простой способ моделирования в условиях неопределенности, и что архитектура преобразователя оказывается полезной для этого приложения. Глубокое обучение даже может улучшить регрессионные модели DataRobot, которые в настоящее время лишены этой возможности. Оставайтесь с нами, поскольку мы освещаем еще больше инноваций и исследований, происходящих в DataRobot.
1 Распознавание образов и машинное обучение, Кристофер М. Бишоп, Springer, 2007.
2 Анализ временных рядов: прогнозирование и контроль, Дженкинс, Гвилим М. и др. Уайли, 2015.
3 Обобщенная авторегрессионная условная гетероскедастичность, Тим Боллерслев, Journal of Econometrics, vol. 31, нет. 3, 1986, стр. 307-327.
4 arXiv, NGBoost: повышение естественного градиента для вероятностного прогнозирования, Тони Дуан и др. 2019.
5 arXiv, Внимание — это все, что вам нужно, Ашиш Васвани и др. июнь 2017 г.
6 arXiv, Пересмотр моделей глубокого обучения для табличных данных, Юрий Горишный и др. июнь 2021.
7 Там же
Об авторе

Стефан Хакманн — старший инженер по машинному обучению в DataRobot, работающий в офисе технического директора. Он математик, который также работал разработчиком, количественным расчетом и портфельным менеджером. Стефан увлечен инновациями в области искусственного интеллекта, но при этом хорошо разбирается в практических последствиях.
Познакомьтесь со Стефаном Хакманном