 на примере
| DeepTech")
После завершения курса № 4 специализации Coursera Deep Learning я хотел написать краткое изложение, чтобы помочь вам понять / освежить в памяти концепцию сверточной нейронной сети (CNN).
Давайте разберемся с CNN на примере –
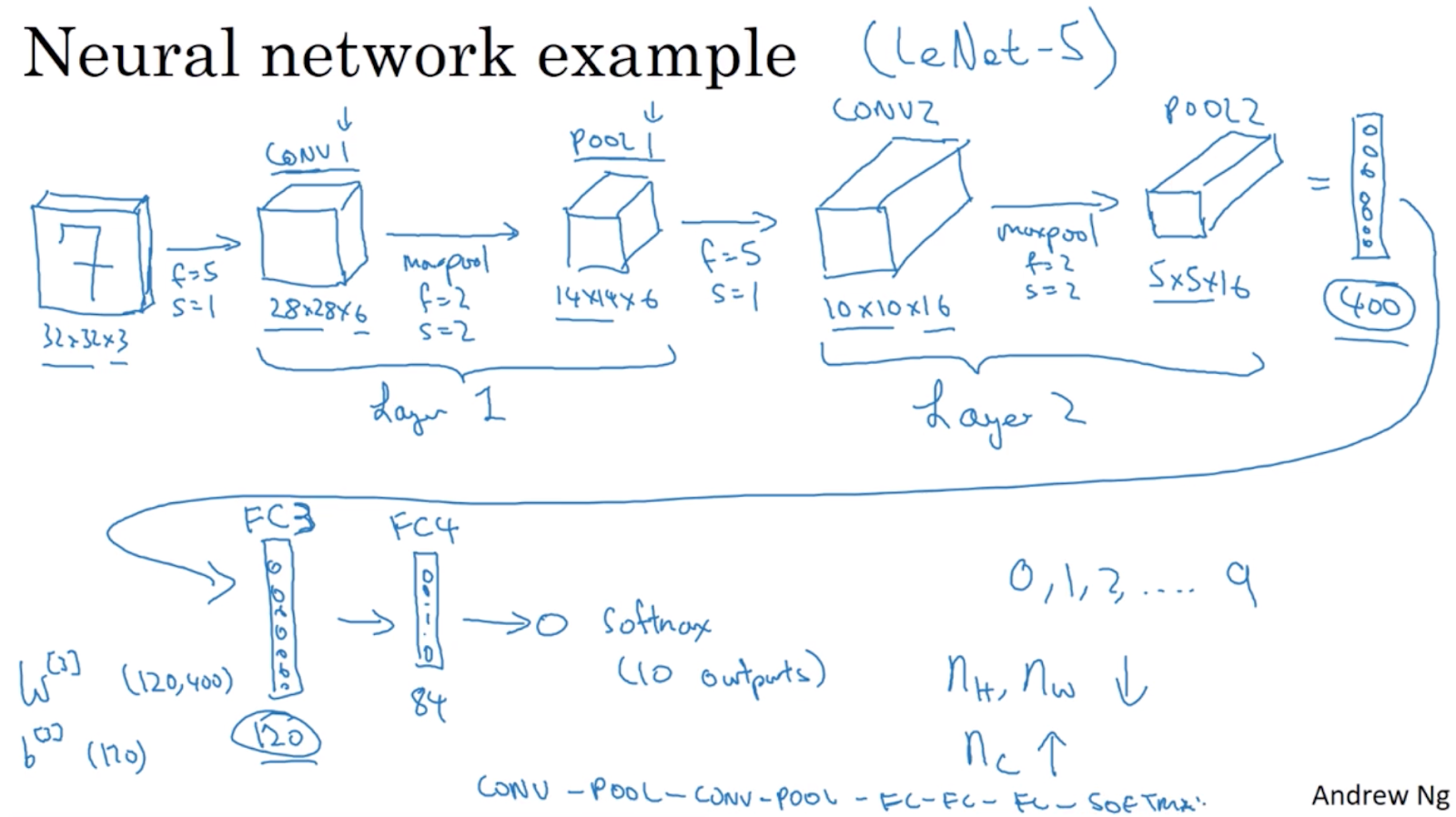
Рис. 1. Пример CNN — источник: специализация Coursera DL
Допустим, у вас есть изображение 32×32 цифр от 0 до 10 с 3 каналами (RGB). Вы пропускаете его через фильтр размера f в 1-м сверточном слое (CL1).
Каков размер выходного изображения фильтра?
Размер выходного изображения рассчитывается по следующей формуле:
 |
| Источник: Средний |
В нашем случае предположим, что отступ равен 0, а шаг равен 1. Приведенная выше формула дает выходной размер 28×28 как для высоты, так и для ширины изображения. Хорошо, это хорошее начало! Давайте продолжим.
Обратите внимание на размерность 6 на выходе слоя 1.
Откуда мы берем третье измерение?
Третье измерение — это не что иное, как количество фильтров в слое. Учитывая фильтр размера f. В слое имеется #f фильтров, и размерность КАЖДОГО фильтра равна размерности fxfxnс
Где нс количество каналов/объем в предыдущем слое. В случае первого уровня предыдущий уровень имеет 3 канала.
Теперь, если в слое 1 есть 6 таких фильтров, каждый фильтр производит нвне хпвне х 1 выход, и учитывая, что у нас есть 6 фильтров – выход сверточного слоя 1 нвне хпвне х 6.
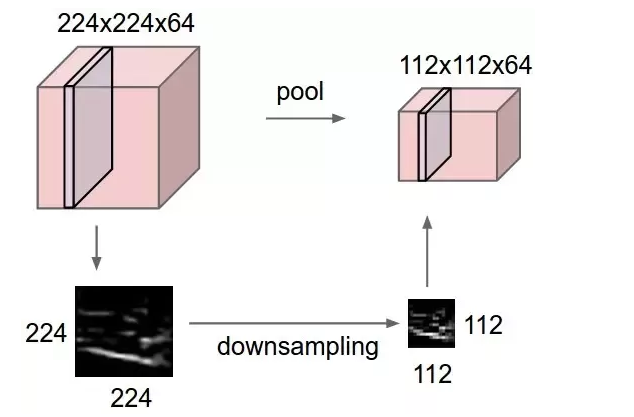
Что делает Max Pooling?
Объединение — это метод сжатия информации, думайте о высоких значениях пикселей как о большем количестве информации, а о низких значениях пикселей — как о меньшем количестве информации. Max Pooling используется для выбора максимального элемента в окне фильтра при свертывании выходных данных предыдущего слоя.
 |
| Источник: ComputerScienceWiki |
 |
| Источник: ComputerScienceWiki
Формула для выходных размеров слоя пула такая же, как и для сверточного слоя. Обычно для размера фильтра (f) для объединения шаг совпадает с размером фильтра, а размер выходных измерений обратно пропорционален размеру шага. Это объясняет резкое уменьшение размеров слоя POOL1. Что нам нужно Convolution, Можем ли мы просто сгладить входное изображение?Размер нашего входного изображения 32x32x3, если бы мы сгладили его, размер нашего входного слоя был бы 3072. Представьте, что первый скрытый слой имеет 1000 нейронов. Мы получили бы 307 200 00 параметров на первом уровне сети. Обучение такого большого слоя может привести к сильному переоснащению. Со сверткой у нас есть параметры fxfx 3 x 6. Для слоя 1 f = 5, что соответствует 450 параметрам входного слоя. Свертка значительно повышает эффективность вычислений! К тому времени, когда мы достигнем полностью связанных слоев с помощью свертки с последующей реализацией пула, у нас будет 120 нейронов в первом полносвязном слое. Это приводит к постепенному снижению количества нейронов, что, как оказалось, приводит к лучшему обобщению. Еще одна вещь, которую следует отметить, это то, что по мере того, как мы углубляемся в сеть, размеры высоты и ширины уменьшаются за счет увеличения размеров объема / канала. Это означает, что Сеть по-прежнему сохраняет информацию, извлекая признаки — для этого и предназначен каждый из этих фильтров. По сути, сеть изучает параметры фильтра, чтобы извлечь значимую информацию из ваших обучающих данных, а затем передать эти функции полностью связанным слоям для классификации. |

Рис. 2. Сводная информация о структуре CNN — источник: специализация Coursera DL.
Как вы можете заметить, размер активации Сети постепенно уменьшается до 10 активаций на выходе Softmax для классификации чисел от 0 до 9, а количество параметров значительно меньше, чем было бы, если бы мы чтобы реализовать этот классификатор со всеми слоями как полностью связанными.
Больше чтений:
http://cs231n.github.io/convolutional-networks/