
Технологии, развернутые в реальном мире, неизбежно сталкиваются с непредвиденными проблемами. Эти проблемы возникают из-за того, что среда, в которой технология была разработана, отличается от среды, в которой она будет развернута. Когда технология успешно передается, мы говорим, что она обобщает. В многоагентная система, таких как технология автономных транспортных средств, есть два возможных источника трудностей обобщения: (1) вариации физической среды, такие как изменения погоды или освещения, и (2) вариации социальной среды: изменения в поведении других взаимодействующих людей. Работа с вариациями социальной среды не менее важна, чем с вариациями физической среды, однако она гораздо менее изучена.
В качестве примера социальной среды рассмотрим, как беспилотные автомобили взаимодействуют на дороге с другими автомобилями. У каждого автомобиля есть стимул перевезти своего пассажира как можно быстрее. Однако эта конкуренция может привести к плохой координации (заторым на дорогах), что негативно сказывается на всех. Если автомобили будут работать сообща, больше пассажиров смогут добраться до места назначения быстрее. Этот конфликт называется социальная дилемма.
Однако не все взаимодействия являются социальными дилеммами. Например, есть синергетический взаимодействия в программном обеспечении с открытым исходным кодом, существуют игра с нулевой суммой взаимодействия в спорте и проблемы с координацией лежат в основе цепочек поставок. Навигация в каждой из этих ситуаций требует совершенно разных подходов.
Мультиагентное обучение с подкреплением предоставляет инструменты, которые позволяют нам исследовать, как искусственные агенты могут взаимодействовать друг с другом и с незнакомыми людьми (например, пользователями-людьми). Ожидается, что этот класс алгоритмов будет работать лучше при тестировании на способность к социальному обобщению, чем другие. Однако до сих пор не существовало систематической контрольной точки для оценки этого.
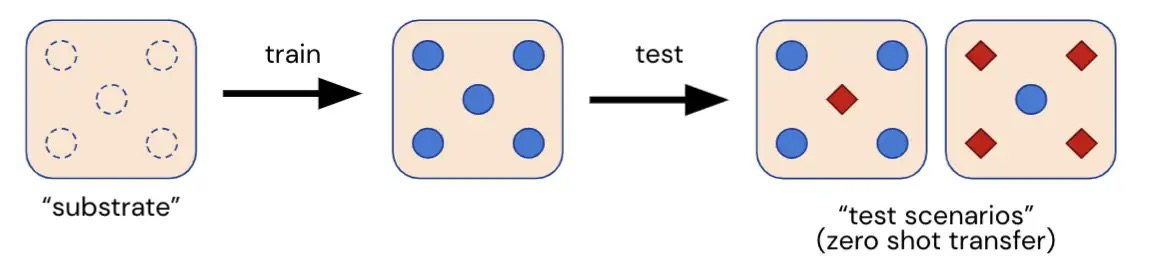
Здесь мы представляем Melting Pot, масштабируемый оценочный пакет для мультиагентного обучения с подкреплением. Плавильный котел оценивает обобщение новых социальных ситуаций с участием как знакомых, так и незнакомых людей и был разработан для проверки широкого спектра социальных взаимодействий, таких как: сотрудничество, конкуренция, обман, взаимность, доверие, упрямство и так далее. Melting Pot предлагает исследователям набор из 21 «подложки» MARL (многоагентных игр), на которых можно обучать агентов, и более 85 уникальных тестовых сценариев, на которых можно оценить этих обученных агентов. Производительность агентов в этих затянувшихся тестовых сценариях количественно определяет, являются ли агенты:
- Хорошо проявляйте себя в различных социальных ситуациях, когда люди взаимозависимы,
- Эффективно взаимодействовать с незнакомыми людьми, которых не видели во время обучения,
- Пройти тест на универсализацию: положительно ответить на вопрос «а что, если бы все вели себя так?»
Полученную оценку затем можно использовать для ранжирования различных многоагентных алгоритмов RL по их способности обобщать к новым социальным ситуациям.
Мы надеемся, что Melting Pot станет эталоном мультиагентного обучения с подкреплением. Мы планируем сохранить его и будем расширять в ближайшие годы, чтобы охватить больше социальных взаимодействий и сценариев обобщения.
Узнайте больше из нашего Страница GitHub.