
В последние годы агенты искусственного интеллекта преуспели в ряде сложных игровых сред. Например, АльфаНоль побеждать в программах чемпионов мира по шахматам, сёги и го, начав со знания лишь основных правил игры. Через обучение с подкреплением (RL), эта единственная система обучалась, играя раунд за раундом в повторяющийся процесс проб и ошибок. Но AlphaZero по-прежнему тренировался отдельно для каждой игры — он не мог просто выучить другую игру или задачу, не повторяя процесс RL с нуля. То же самое верно и для других успехов RL, таких как Атари, Захват флага, Старкрафт 2, Dota 2и Прятки. Миссия DeepMind по использованию интеллекта для развития науки и человечества привела нас к изучению того, как мы можем преодолеть это ограничение, чтобы создать агентов ИИ с более общим и адаптивным поведением. Вместо того, чтобы изучать одну игру за раз, эти агенты смогут реагировать на совершенно новые условия и играть в целую вселенную игр и задач, в том числе невиданных ранее.
Сегодня мы опубликовали “Открытое обучение ведет к созданию способных агентов, — препринт, подробно описывающий наши первые шаги по обучению агента, способного играть во множество разных игр, не нуждаясь в данных о взаимодействии с человеком. Мы создали обширную игровую среду, которую назвали XLand, которая включает в себя множество многопользовательских игр в согласованных трехмерных мирах, связанных с человеком. Эта среда позволяет сформулировать новые алгоритмы обучения, которые динамически управляют тем, как тренируется агент, и играми, на которых он тренируется. агент никогда не перестает учиться. В результате получается агент, способный успешно решать широкий спектр задач — от простых задач на поиск предметов до сложных игр, таких как прятки и захват флага, которые не встречались во время обучения. агент демонстрирует общее эвристическое поведение, такое как экспериментирование, поведение, которое широко применимо ко многим задачам, а не специализировано к отдельной задаче. Этот новый подход знаменует собой важный шаг к созданию более универсальных агентов, способных быстро адаптироваться к постоянно меняющимся условиям.
Вселенная тренировочных заданий
Недостаток обучающих данных — где точки данных — это разные задачи — был одним из основных факторов, ограничивающих поведение агентов, обученных RL, достаточно общим, чтобы его можно было применять в играх. Не имея возможности обучать агентов достаточно широкому набору задач, агенты, обученные с помощью RL, не могут адаптировать свое выученное поведение к новым задачам. Но, спроектировав смоделированное пространство, позволяющее процедурно генерируемые задачи, наша команда создала способ обучения и накопления опыта на задачах, созданных программно. Это позволяет нам включать миллиарды задач в XLand для различных игр, миров и игроков.
Наши агенты ИИ обитают в трехмерных аватарах от первого лица в многопользовательской среде, предназначенной для имитации физического мира. Игроки ощущают свое окружение, наблюдая за RGB-изображениями и получая текстовое описание своей цели, а также тренируются в различных играх. Эти игры так же просты, как совместные игры для поиска объектов и навигации по мирам, где целью игрока может быть «оказаться рядом с фиолетовым кубом». Более сложные игры могут быть основаны на выборе из нескольких вариантов вознаграждения, таких как «быть рядом с фиолетовым кубом или положить желтую сферу на красный пол», а более соревновательные игры включают в себя игру против других игроков, например, симметричные прятки, где у каждого игрока есть цель «увидеть противника и сделать так, чтобы противник не видел меня». Каждая игра определяет награды для игроков, и конечная цель каждого игрока — максимизировать награды.
Поскольку XLand можно указать программно, игровое пространство позволяет генерировать данные автоматически и алгоритмически. А поскольку в заданиях в XLand участвуют несколько игроков, поведение других игроков сильно влияет на проблемы, с которыми сталкивается агент ИИ. Эти сложные нелинейные взаимодействия создают идеальный источник данных для обучения, поскольку иногда даже небольшие изменения в компонентах среды могут привести к большим изменениям в задачах для агентов.

Методы обучения
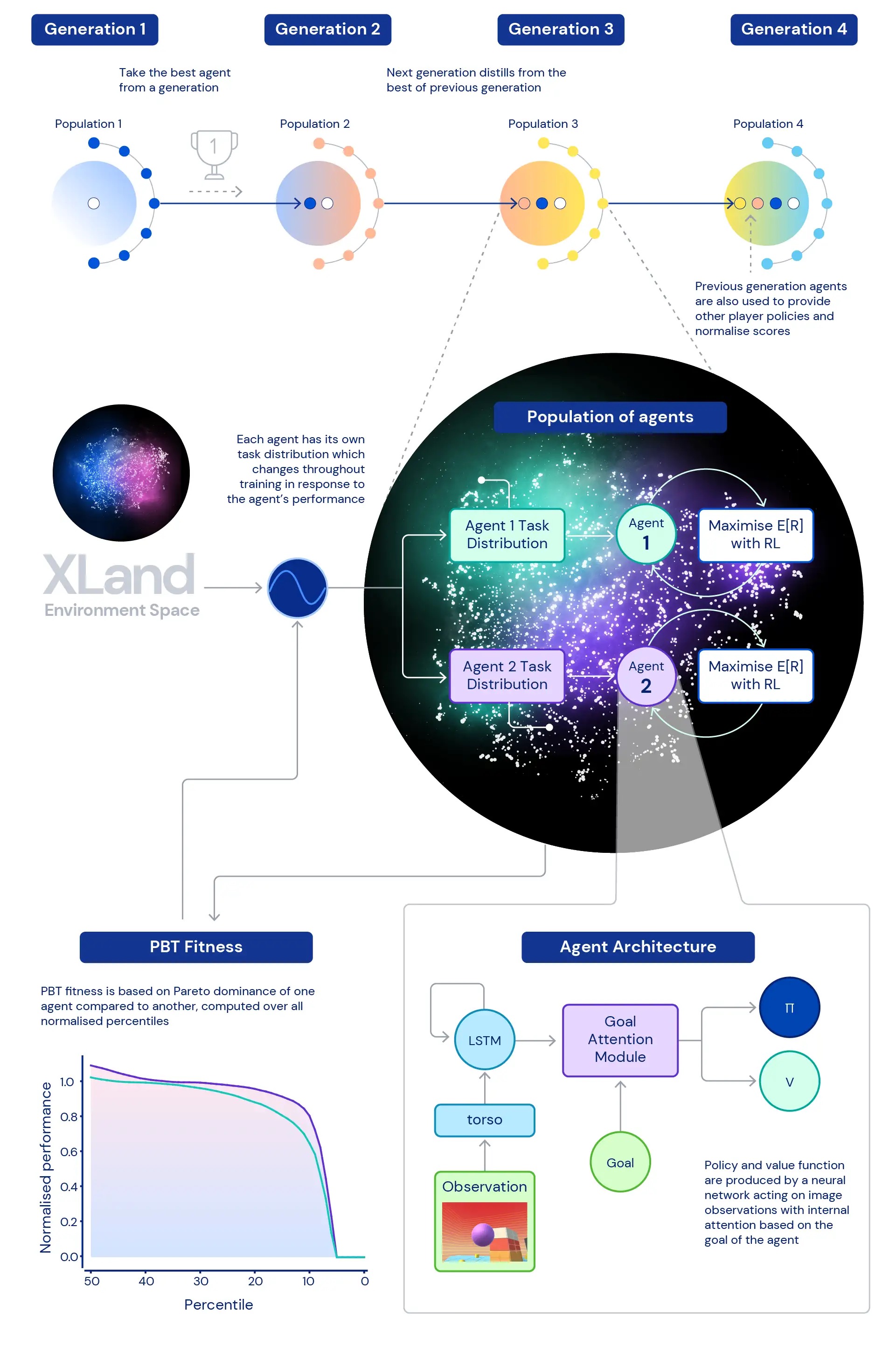
Центральное место в нашем исследовании занимает роль глубокий RL в обучении нейронных сетей наших агентов. Архитектура нейронной сети, которую мы используем, обеспечивает механизм внимания к внутреннему повторяющемуся состоянию агента, помогая направлять внимание агента с помощью оценок подцелей, уникальных для игры, в которую играет агент. Мы обнаружили, что этот ориентированный на цель агент (GOAT) изучает более общие политики.
Мы также исследовали вопрос, какое распределение обучающих задач позволит создать наилучшего агента, особенно в такой обширной среде? Используемая нами динамическая генерация задач позволяет постоянно изменять распределение обучающих задач агента: каждая задача генерируется не слишком сложной и не слишком легкой, а как раз подходящей для обучения. Затем мы используем обучение населения (PBT) для настройки параметров генерации динамических задач на основе приспособленности, направленной на улучшение общих возможностей агентов. И, наконец, мы объединяем несколько тренировочных прогонов, чтобы каждое поколение агентов могло запускать предыдущее поколение.
Это приводит к окончательному процессу обучения с глубоким RL в основе, обновляющим нейронные сети агентов с каждым шагом опыта:
- этапы опыта происходят из обучающих задач, которые динамически генерируются в ответ на поведение агентов,
- функции агентов по созданию задач мутируют в зависимости от относительной производительности и надежности агентов,
- в самом дальнем цикле поколения агентов загружаются друг из друга, обеспечивая многопользовательскую среду еще более богатыми со-игроками и переопределяя измерение самого прогресса.
Процесс обучения начинается с нуля и постепенно усложняется, постоянно меняя задачу обучения, чтобы агент продолжал обучение. Итеративный характер комбинированной системы обучения, которая оптимизирует не ограниченный показатель производительности, а скорее итеративно определенный спектр общих возможностей, приводит к потенциально открытому процессу обучения для агентов, ограниченному только выразительностью пространства среды и агента. нейронная сеть.
Измерение прогресса
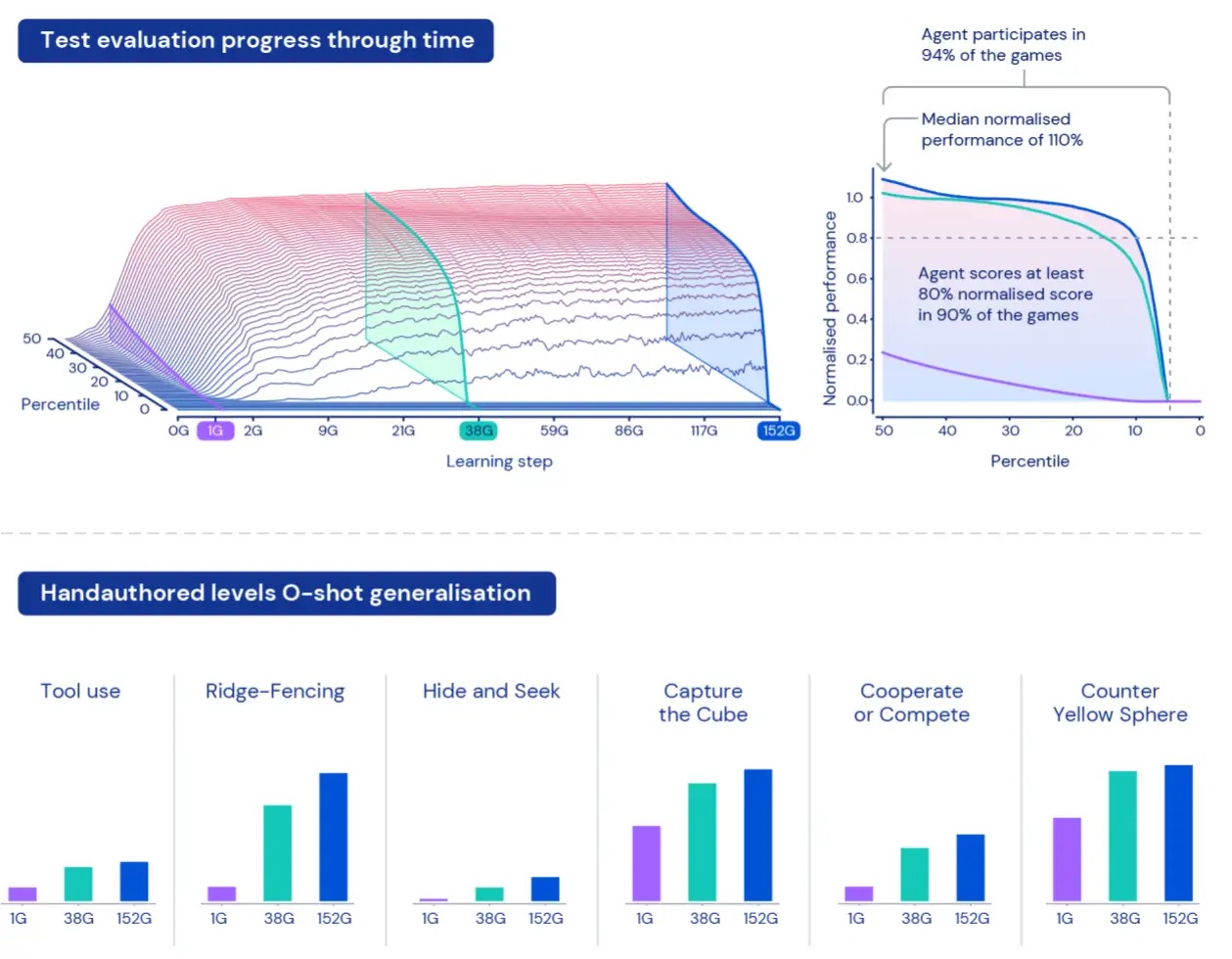
Чтобы измерить, как агенты работают в этой огромной вселенной, мы создаем набор оценочных задач, используя игры и миры, которые остаются отдельными от данных, используемых для обучения. Эти «отложенные» задачи включают в себя специально разработанные человеком задачи, такие как прятки и захват флага.
Из-за размера XLand понимание и характеристика работы наших агентов может оказаться сложной задачей. Каждая задача включает в себя разные уровни сложности, разные масштабы достижимых вознаграждений и разные возможности агента, поэтому простое усреднение вознаграждения по протянутым задачам скроет фактические различия в сложности и вознаграждениях — и фактически все задачи будут рассматриваться как одинаково интересные. что не обязательно верно для процедурно сгенерированных сред.
Чтобы преодолеть эти ограничения, мы используем другой подход. Во-первых, мы нормализуем баллы за задачу, используя равновесное значение Нэша, рассчитанное с использованием нашего текущего набора обученных игроков. Во-вторых, мы принимаем во внимание все распределение нормализованных оценок — вместо того, чтобы рассматривать средние нормализованные оценки, мы смотрим на различные процентили нормализованных оценок — а также процент задач, в которых агент получает хотя бы одну ступень вознаграждения: участие. Это означает, что агент считается лучше другого агента только в том случае, если его производительность превосходит все процентили. Такой подход к измерению дает нам осмысленный способ оценки производительности и надежности наших агентов.
Агенты с более широкими способностями
Обучив наших агентов в течение пяти поколений, мы увидели последовательные улучшения в обучении и производительности в нашем пространстве оценки. Сыграв около 700 000 уникальных игр в 4 000 уникальных мирах в XLand, каждый агент последнего поколения прошел 200 миллиардов тренировочных шагов в результате 3,4 миллиона уникальных задач. В настоящее время наши агенты могут участвовать во всех процедурно сгенерированных оценочных задачах, за исключением нескольких, которые были невозможны даже для человека. И результаты, которые мы видим, ясно демонстрируют общее, нулевое поведение во всем пространстве задач — с постоянным улучшением границы нормализованных процентилей оценки.
Глядя на наших агентов с качественной точки зрения, мы часто видим появление общего, эвристического поведения, а не высокооптимизированного, специфического поведения для отдельных задач. Вместо агентов, точно знающих, что «лучше всего» делать в новой ситуации, мы видим свидетельства того, что агенты экспериментируют и изменяют состояние мира до тех пор, пока не достигнут полезного состояния. Мы также видим, что агенты полагаются на использование других инструментов, в том числе объектов для закрытия видимости, создания пандусов и извлечения других объектов. Поскольку среда является многопользовательской, мы можем исследовать развитие поведения агентов, тренируясь на задержке. социальные дилеммынапример, в игре «курица». По мере обучения наши агенты проявляют более склонное к сотрудничеству поведение, когда играют с копиями самих себя. Учитывая характер окружающей среды, трудно точно определить преднамеренность — поведение, которое мы наблюдаем, часто кажется случайным, но тем не менее мы видим, что оно происходит постоянно.
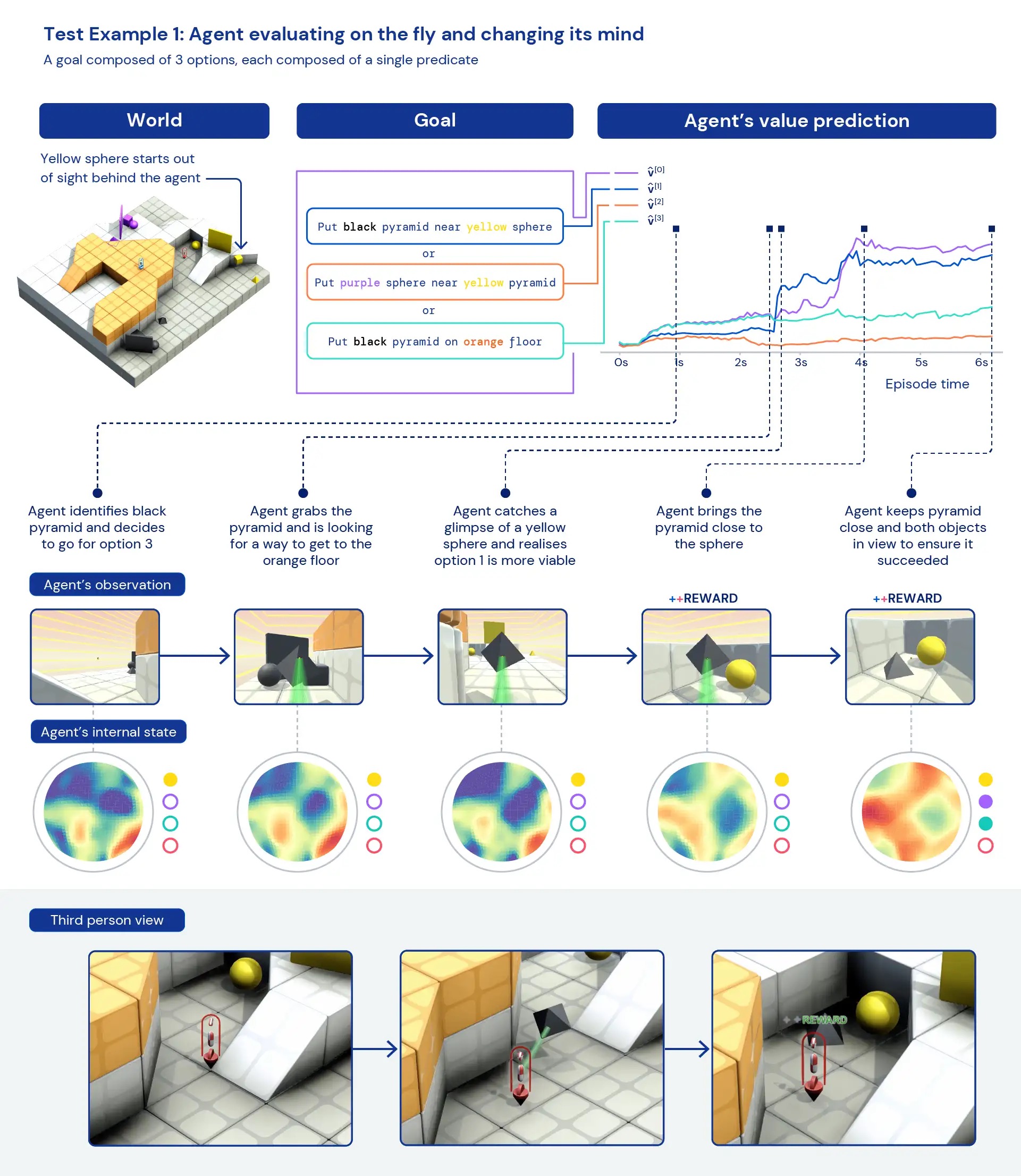
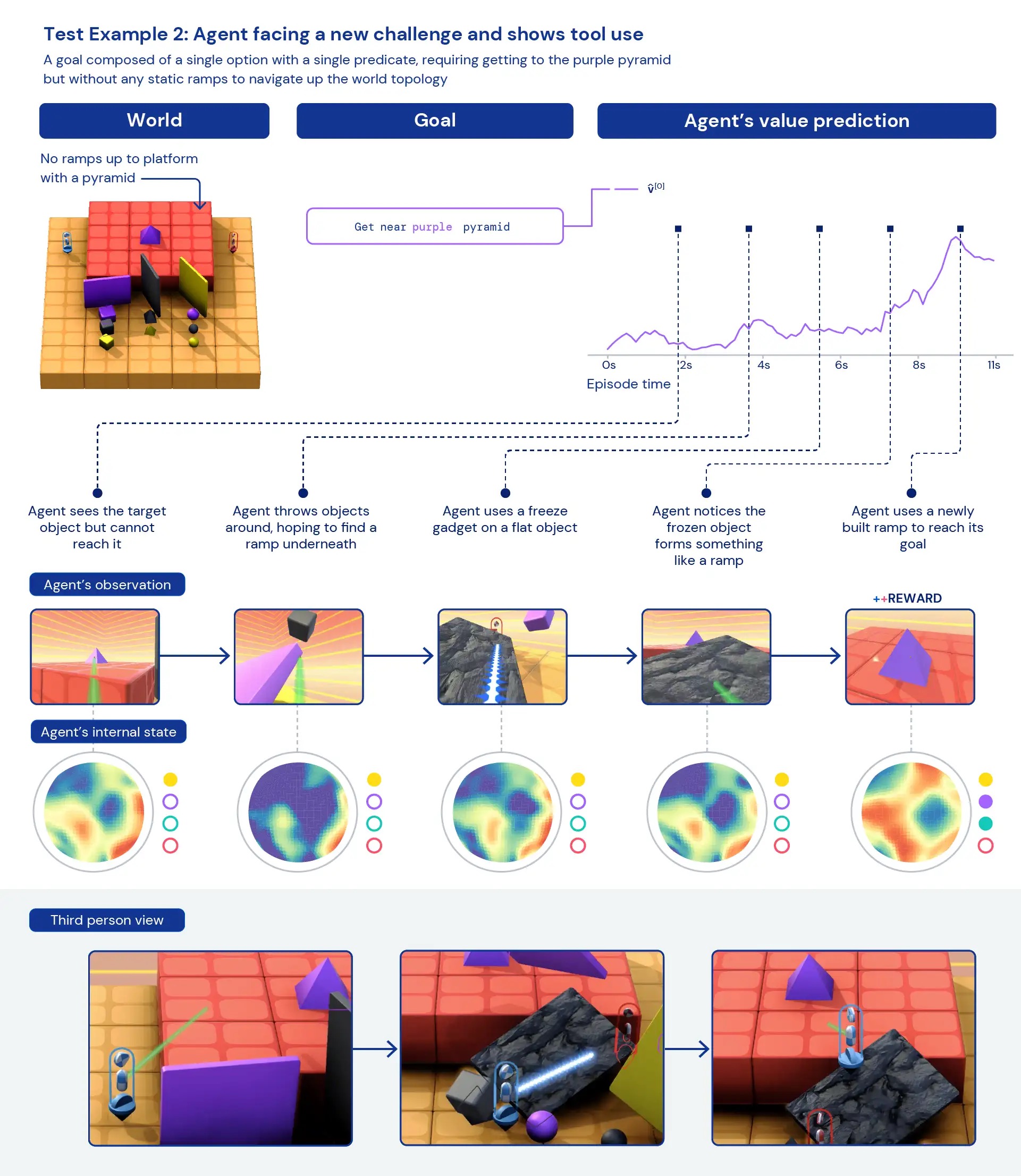
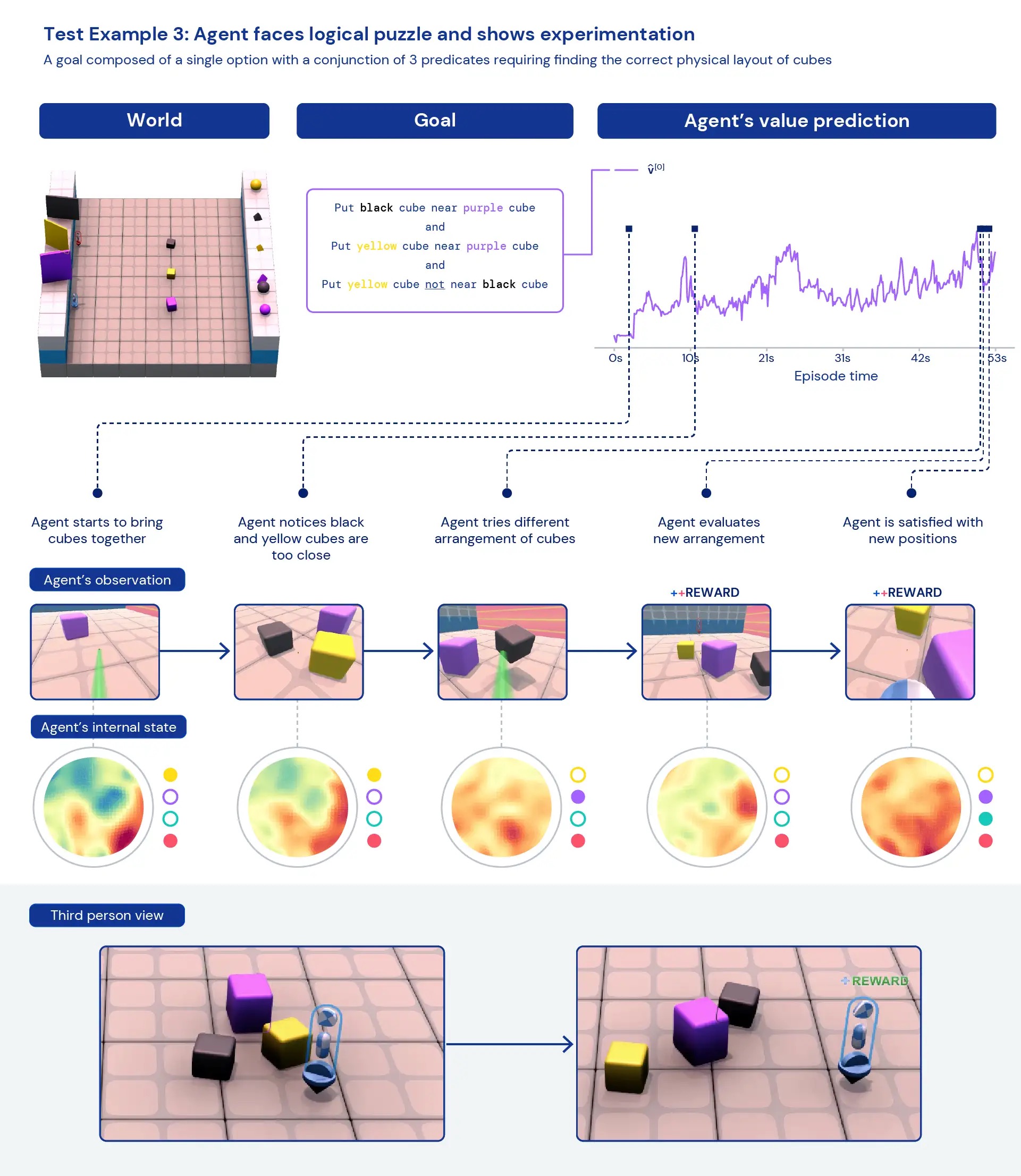



Анализируя внутренние представления агента, мы можем сказать, что, применяя этот подход к обучению с подкреплением в обширном пространстве задач, наши агенты осознают основы своего тела и течения времени, а также понимают высокоуровневую структуру игр. они сталкиваются. Возможно, что еще более интересно, они четко распознают состояния вознаграждения в своем окружении. Эта общность и разнообразие поведения в новых задачах намекает на возможность тонкой настройки этих агентов для последующих задач. Например, в техническом документе мы показываем, что всего за 30 минут целенаправленного обучения новой сложной задаче агенты могут быстро адаптироваться, в то время как агенты, обученные RL с нуля, вообще не могут изучить эти задачи.
Разработав такую среду, как XLand, и новые обучающие алгоритмы, поддерживающие неограниченное создание сложности, мы увидели явные признаки того, что агенты RL не могут обобщать с нуля. В то время как эти агенты в целом начинают работать в этой области задач, мы с нетерпением ждем продолжения наших исследований и разработок для дальнейшего повышения их производительности и создания еще более адаптивных агентов.
Для получения более подробной информации см. препринт нашей технической статьи – и видео результатов мы видели. Мы надеемся, что это может помочь другим исследователям также увидеть новый путь к созданию более адаптивных, в целом способных агентов ИИ. Если вы в восторге от этих достижений, подумайте присоединиться к нашей команде.