
Наш мозг обладает удивительной способностью обрабатывать визуальную информацию. Мы можем одним взглядом взглянуть на сложную сцену и за миллисекунды разбить ее на объекты и их атрибуты, такие как цвет или размер, и использовать эту информацию для описания сцены простым языком. В основе этой, казалось бы, легкой способности лежит сложное вычисление, выполняемое нашей зрительной корой, которое включает в себя прием миллионов нервных импульсов, передаваемых от сетчатки, и преобразование их в более осмысленную форму, которую можно сопоставить с простым языковым описанием. Чтобы полностью понять, как этот процесс работает в мозгу, нам необходимо выяснить, как семантически значимая информация представлена при срабатывании нейронов в конце иерархии обработки зрительной информации, и как такое представление может быть усвоено в значительной степени из необученный опыт.
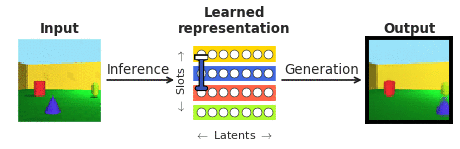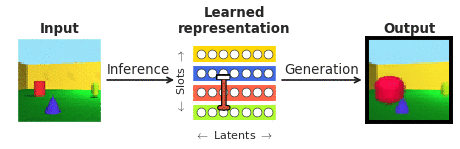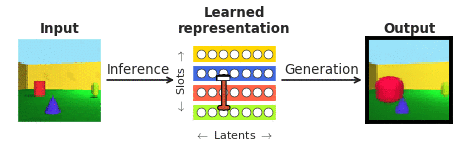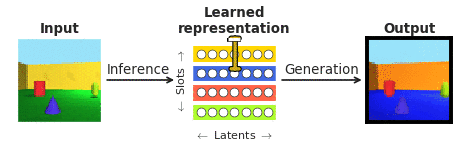
Чтобы ответить на эти вопросы в контексте восприятия лица, мы объединили усилия с нашими сотрудниками из Калифорнийского технологического института (Caltech).Дорис Цао) и Китайской академии наук (Ле Чанг). Мы выбрали лица, потому что они хорошо изучены в нейробиологическом сообществе и часто рассматриваются как «микромир распознавания объектов». В частности, мы хотели сравнить ответы отдельных корковых нейронов в участках лица в конце иерархии обработки изображений, записанные нашими сотрудниками, с недавно появившимся классом так называемых «распутывающих» глубоких нейронных сетей, которые, в отличие от обычных « системы «черный ящик» явно нацелены на то, чтобы их могли интерпретировать люди. «Распутывающая» нейронная сеть учится отображать сложные изображения на небольшое количество внутренних нейронов (называемых скрытыми единицами), каждая из которых представляет один семантически значимый атрибут сцены, такой как цвет или размер объекта (см. рис. 1). В отличие от глубинных классификаторов «черного ящика», обученных распознавать визуальные объекты с помощью биологически нереалистичного объема внешнего наблюдения, такие распутывающие модели обучаются без внешнего обучающего сигнала с использованием самоконтролируемой цели восстановления входных изображений (генерация на рис. 1) из их исходных изображений. выученное скрытое представление (полученное путем логического вывода на рис. 1).
Распутывание было предположил быть важным в сообществе машинного обучения почти десять лет назад как неотъемлемый компонент для создания большего эффективное использование данных, передаваемый, справедливыйи творческий системы искусственного интеллекта. Однако в течение многих лет создание модели, которая могла бы распутываться на практике, ускользало от полевых исследований. Первая модель, способная сделать это успешно и надежно, называется β-ВАЭбыл разработан путем принятия вдохновение из нейронауки: β-VAE учится предсказание собственных входов; для успешного обучения требуется такой же визуальный опыт, как с которыми сталкиваются младенцы; и его усвоенное латентное представление отражает известные свойства зрительного мозга.
В нашем новая бумага, мы измерили степень, в которой распутанные единицы, обнаруженные β-VAE, обученным на наборе данных изображений лиц, подобны ответам одиночных нейронов в конце визуальной обработки, зарегистрированным у приматов, смотрящих на те же лица. Нейронные данные были собраны нашими сотрудниками под строгим контролем со стороны Комитет по уходу и использованию животных Калифорнийского технологического института. Когда мы провели сравнение, мы обнаружили кое-что удивительное: казалось, что несколько распутанных единиц, обнаруженных с помощью β-VAE, ведут себя так, как если бы они были эквивалентны подмножеству реальных нейронов аналогичного размера. Приглядевшись повнимательнее, мы обнаружили сильное взаимно-однозначное соответствие между реальными и искусственными нейронами (см. рис. 2). Это сопоставление было намного сильнее, чем для альтернативных моделей, включая глубокие классификаторы, которые ранее считались современными вычислительными моделями обработки изображений, или созданную вручную модель восприятия лица, считающуюся «золотым стандартом» в нейробиологическом сообществе. Мало того, единицы β-VAE кодировали семантически значимую информацию, такую как возраст, пол, размер глаз или наличие улыбки, что позволяло нам понять, какие атрибуты используются отдельными нейронами в мозгу для представления лиц.
.jpg)
Если β-VAE действительно может автоматически обнаруживать искусственные латентные единицы, которые эквивалентны реальным нейронам с точки зрения того, как они реагируют на изображения лиц, тогда должна быть возможность перевести активность реальных нейронов в их соответствующие искусственные аналоги и использовать генератор (см. рисунок 1) обученного β-VAE, чтобы визуализировать, какие лица представляют настоящие нейроны. Чтобы проверить это, мы представили приматам новые изображения лиц, которых модель никогда не видела, и проверили, можем ли мы визуализировать их с помощью генератора β-VAE (см. рис. 3). Мы обнаружили, что это действительно возможно. Используя активность всего лишь 12 нейронов, мы смогли генерировать изображения лиц, которые были более точными реконструкциями оригиналов и имели лучшее визуальное качество, чем изображения, созданные альтернативными моделями глубокой генерации. И это несмотря на то, что альтернативные модели, как известно, лучше генерируют изображения, чем β-VAE в целом.
.jpg)
Наши выводы, обобщенные в новая бумага предполагают, что зрительный мозг можно понять на уровне одного нейрона, даже в конце его иерархии обработки. Это противоречит распространенному мнению, что семантически значимая информация мультиплексированы между большим количеством таких нейронов, каждый из которых остается в значительной степени не интерпретируемым по отдельности, мало чем отличаясь от того, как информация кодируется через полные слои искусственных нейронов в глубоких классификаторах. Мало того, наши результаты показывают, что, возможно, мозг учится поддерживать нашу способность к визуальному восприятию без усилий, оптимизируя цель распутывания. Хотя β-VAE изначально разрабатывался под влиянием принципы нейробиологии высокого уровняполезность распутанных репрезентаций для разумного поведения до сих пор демонстрировалась главным образом в сообщество машинного обучения. В соответствии с богатой историей взаимовыгодного взаимодействие между нейронаукой и машинным обучениеммы надеемся, что последние результаты машинного обучения теперь могут быть переданы сообществу нейробиологов для изучения достоинств распутанных представлений для поддержки интеллекта в биологических системах, в частности, в качестве основы для отвлеченные рассужденияили обобщаемый и эффективный обучение задачам.