
В последние годы значительный прирост производительности в авторегрессионном языковом моделировании был достигнут за счет увеличения количества параметров в моделях Transformer. Это привело к огромному увеличению затрат энергии на обучение и привело к созданию плотных «больших языковых моделей» (LLM) с более чем 100 миллиардами параметров. Одновременно были собраны большие наборы данных, содержащие триллионы слов, чтобы облегчить обучение этих LLM.
Мы изучаем альтернативный путь улучшения языковых моделей: мы дополняем преобразователи поиском по базе данных отрывков текста, включая веб-страницы, книги, новости и код. Мы называем наш метод РЕТРО, что означает «Поиск расширенных трансформеров».
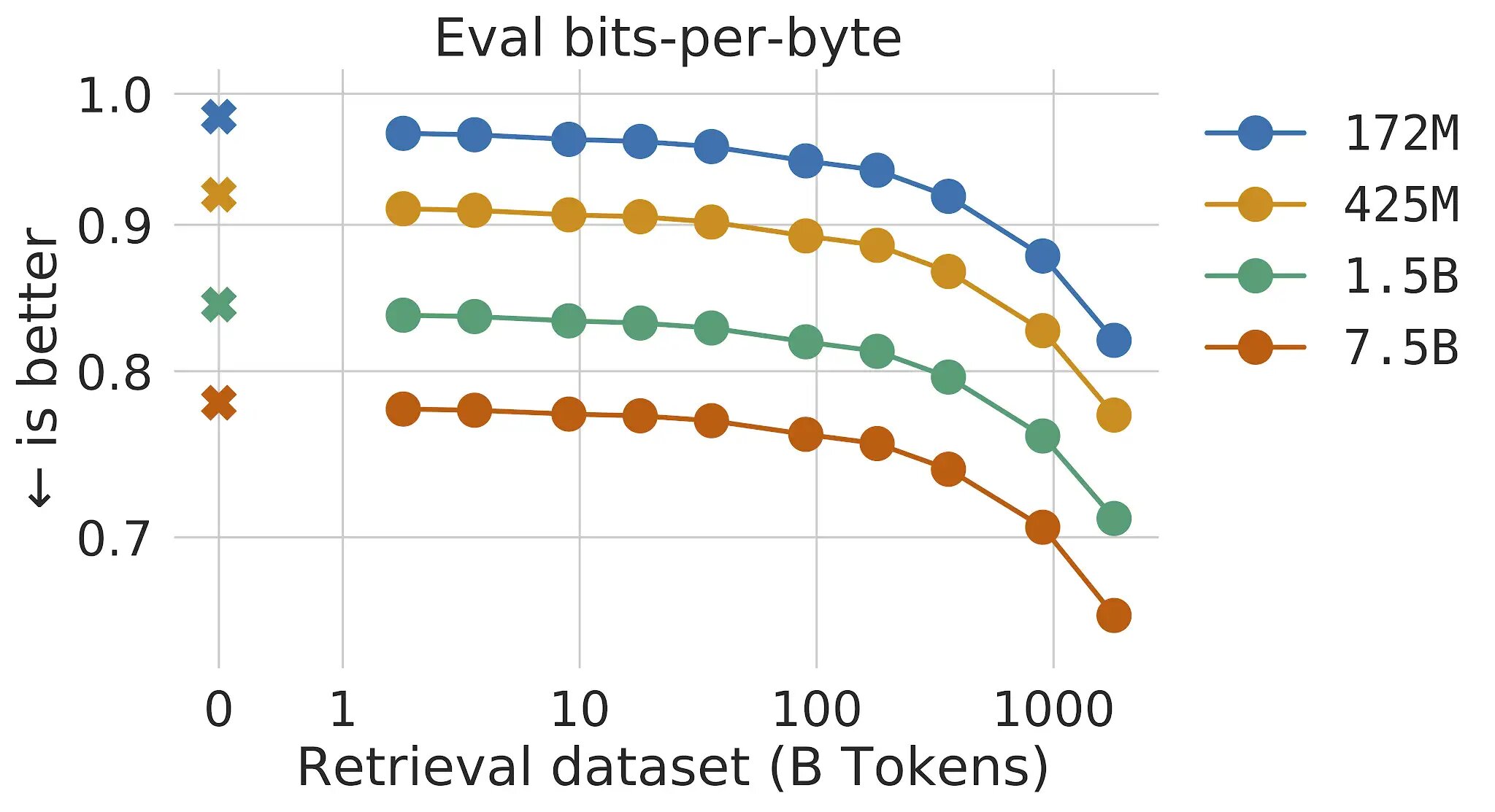
В традиционных языковых моделях преобразования преимущества размера модели и размера данных связаны: пока набор данных достаточно велик, производительность языкового моделирования ограничена размером модели. Однако с RETRO модель не ограничивается данными, увиденными во время обучения, — она имеет доступ ко всему набору обучающих данных через механизм поиска. Это приводит к значительному приросту производительности по сравнению со стандартным преобразователем с тем же количеством параметров. Мы показываем, что языковое моделирование постоянно совершенствуется по мере увеличения размера поисковой базы данных, по крайней мере, до 2 триллионов токенов — 175 полных жизней непрерывного чтения.
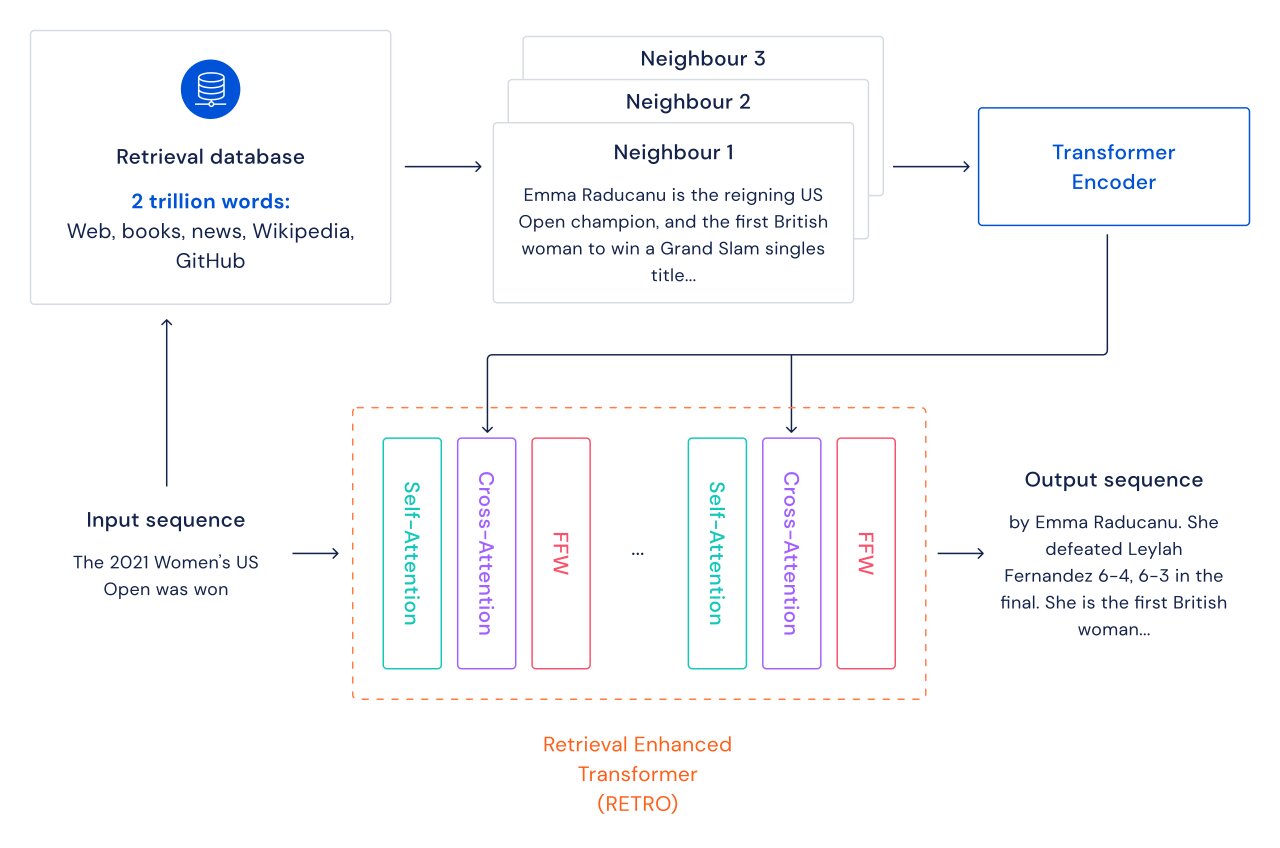
Для каждого фрагмента текста (примерно абзаца документа) выполняется поиск ближайшего соседа, который возвращает похожие последовательности, найденные в обучающей базе данных, и их продолжение. Эти последовательности помогают предсказать продолжение введенного текста. Архитектура RETRO чередует обычное внимание к себе на уровне документа и перекрестное внимание с извлеченными соседями на более тонком уровне перехода. Это приводит к более точным и более фактическим продолжениям. Кроме того, RETRO повышает интерпретируемость прогнозов моделей и обеспечивает возможность прямого вмешательства в базу данных поиска для повышения безопасности продолжения текста. В наших экспериментах с Pile, эталоном стандартного языкового моделирования, модель RETRO с 7,5 миллиардами параметров превосходит Jurassic-1 со 175 миллиардами параметров на 10 из 16 наборов данных и превосходит 280B Gopher на 9 из 16 наборов данных.
Ниже мы показываем два образца из нашей базовой модели 7B и из нашей модели модели 7.5B RETRO, которые подчеркивают, что образцы RETRO являются более фактическими и более актуальными, чем базовый образец.

