
В наша недавняя статья, мы исследуем, как популяции агентов глубокого обучения с подкреплением (глубокое RL) могут изучать микроэкономическое поведение, такое как производство, потребление и торговля товарами. Мы обнаружили, что искусственные агенты учатся принимать экономически рациональные решения о производстве, потреблении и ценах и соответствующим образом реагировать на изменения спроса и предложения. Население стремится к местным ценам, которые отражают изобилие ресурсов поблизости, и некоторые агенты учатся перевозить товары между этими районами, чтобы «покупать дешево и продавать дорого». Эта работа продвигает более широкую программу исследований многоагентного обучения с подкреплением, предлагая агентам новые социальные задачи, которые нужно научиться решать.
Поскольку цель исследования многоагентного обучения с подкреплением состоит в том, чтобы в конечном итоге создать агентов, которые работают во всем диапазоне и сложности человеческого социального интеллекта, набор областей, рассмотренных до сих пор, был крайне неполным. В нем по-прежнему отсутствуют важные области, в которых превосходит человеческий интеллект, и люди тратят значительное количество времени и энергии. Одной из таких областей является предмет экономической науки. Наша цель в этой работе — создать среду, основанную на темах торговли и переговоров, для использования исследователями в мультиагентном обучении с подкреплением.
Экономика использует агентные модели для имитации поведения экономики. Эти агентные модели часто строятся на экономических предположениях о том, как должны действовать агенты. В этой работе мы представляем многоагентный смоделированный мир, в котором агенты могут изучать экономическое поведение с нуля способами, знакомыми любому студенту микроэкономики 101: принимать решения о производстве, потреблении и ценах. Но наши агенты также должны делать и другие выборы, вытекающие из более физически воплощенного способа мышления. Они должны ориентироваться в физической среде, находить деревья, чтобы собирать фрукты, и партнеров, с которыми можно ими торговать. Недавние достижения в методах глубокого RL теперь позволяют создавать агенты, которые могут изучать эти поведения самостоятельно, не требуя от программиста кодирования знаний предметной области.
Наша среда, называемая Фруктовый рынок, представляет собой многопользовательскую среду, в которой агенты производят и потребляют два вида фруктов: яблоки и бананы. Каждый агент умеет производить один вид фруктов, но предпочитает другой — если агенты научатся бартеру и обмену товарами, обе стороны выиграют.

В наших экспериментах мы демонстрируем, что нынешние агенты глубокого RL могут научиться торговать, и их поведение в ответ на изменения спроса и предложения согласуется с тем, что предсказывает микроэкономическая теория. Затем мы основываемся на этой работе, чтобы представить сценарии, которые было бы очень сложно решить с помощью аналитических моделей, но которые легко понять для наших агентов глубокого RL. Например, в условиях, когда каждый вид фруктов растет в разных районах, мы наблюдаем появление разных ценовых регионов, связанных с локальным изобилием фруктов, а также последующее обучение некоторым агентам арбитражному поведению, которые начинают специализироваться на перевозки фруктов между этими регионами.
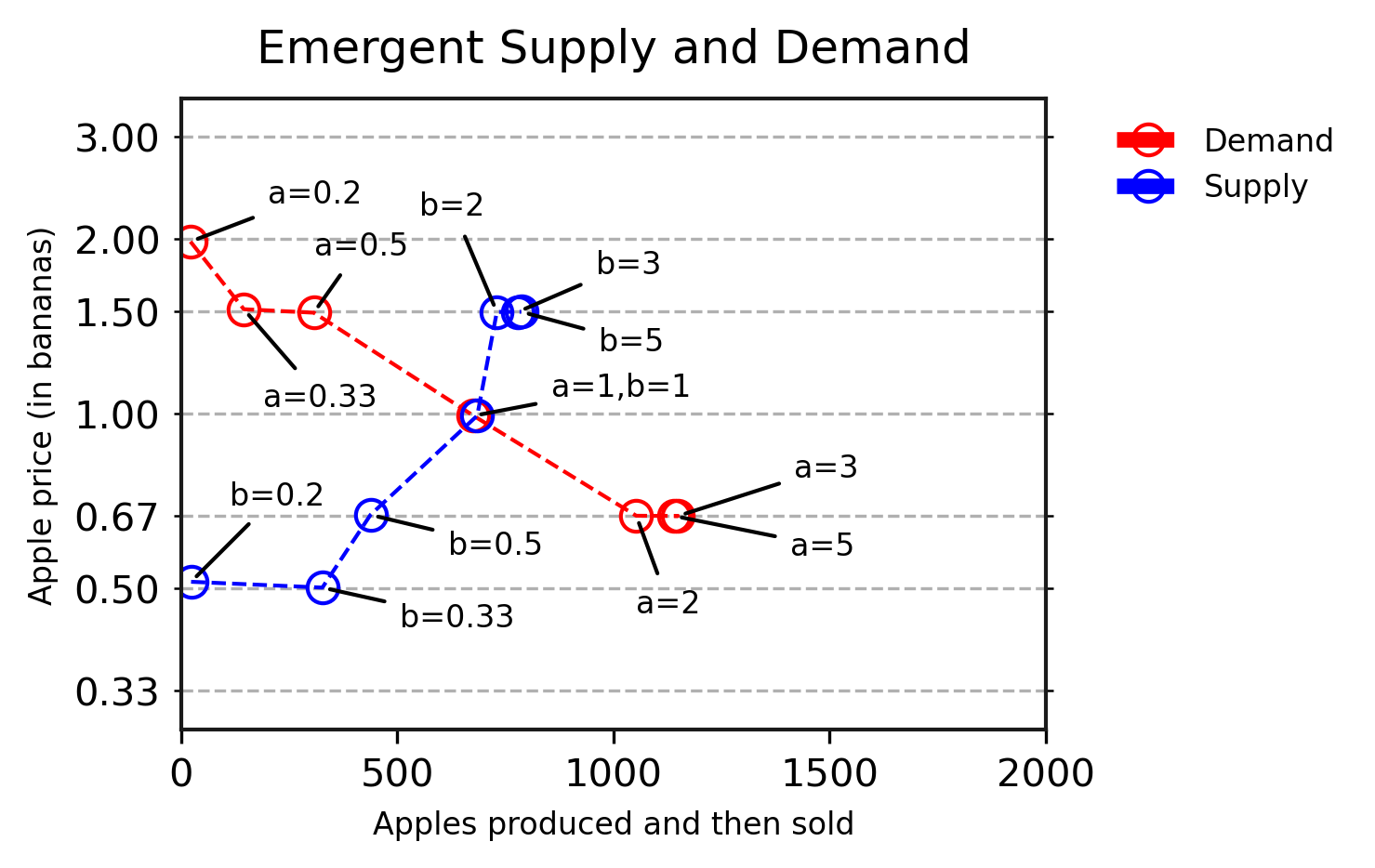
В области агентной вычислительной экономики аналогичные модели используются для экономических исследований. В этой работе мы также демонстрируем, что современные методы глубокого RL могут гибко учиться действовать в этих средах на основе собственного опыта, без необходимости иметь встроенные экономические знания. Это подчеркивает недавний прогресс сообщества обучения с подкреплением в мульти -агентное RL и глубокое RL, а также демонстрирует потенциал многоагентных методов в качестве инструментов для продвижения имитационных экономических исследований.
Как путь к искусственному общему интеллекту (AGI), исследования мультиагентного обучения с подкреплением должны охватывать все критические области социального интеллекта. Однако до сих пор он не включал в себя традиционные экономические явления, такие как торговля, торг, специализация, потребление и производство. Данная статья восполняет этот пробел и предоставляет платформу для дальнейших исследований. Чтобы помочь будущим исследованиям в этой области, среда Fruit Market будет включена в следующую версию Плавильный котел комплект сред.