
Чтобы научить агентов хорошо взаимодействовать с людьми, нам нужно иметь возможность измерять прогресс. Но человеческое взаимодействие сложно, и измерить прогресс сложно. В этой работе мы разработали метод, названный Standardized Test Suite (STS), для оценки агентов в расширенных во времени мультимодальных взаимодействиях. Мы рассмотрели взаимодействия, в которых участники-люди просят агентов выполнять задачи и отвечать на вопросы в моделируемой трехмерной среде.
Методология STS помещает агентов в набор поведенческих сценариев, извлеченных из реальных данных о взаимодействии людей. Агенты видят воспроизведенный контекст сценария, получают инструкции, а затем получают контроль над выполнением взаимодействия в автономном режиме. Эти действия агентов записываются, а затем отправляются оценщикам для пометки об успехе или неудаче. Затем агенты ранжируются в соответствии с долей сценариев, в которых они преуспели.
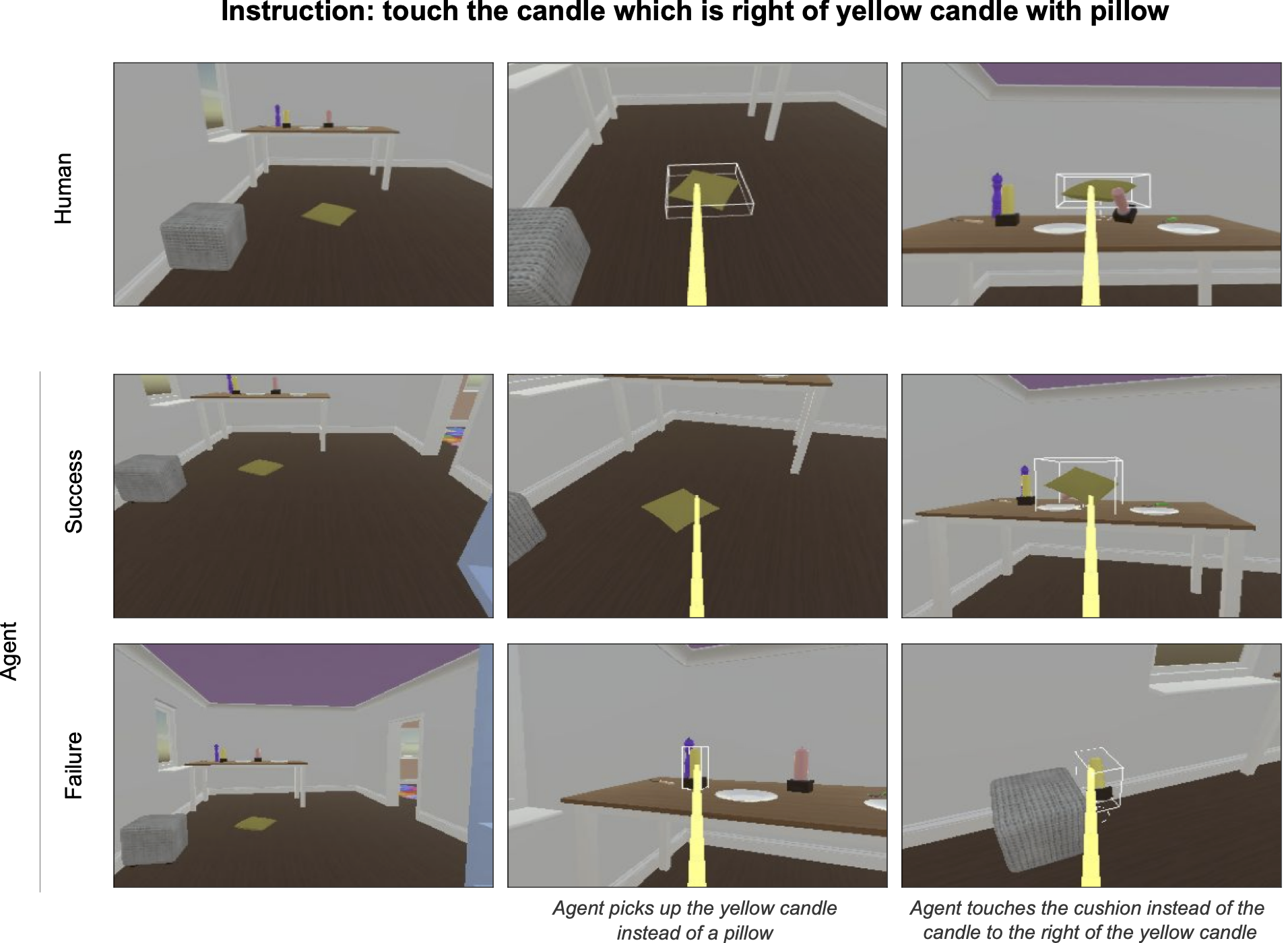
Многие виды поведения, которые являются второй натурой человека в наших повседневных взаимодействиях, трудно выразить словами и невозможно формализовать. Таким образом, механизм, используемый для решения игр (таких как Atari, Go, DotA и Starcraft) с обучением с подкреплением, не будет работать, когда мы пытаемся научить агентов плавному и успешному взаимодействию с людьми. Например, подумайте о разнице между этими двумя вопросами: «Кто выиграл эту игру в го?» против «На что ты смотришь?» В первом случае мы можем написать кусок компьютерного кода, который подсчитывает камни на доске в конце игры и с уверенностью определяет победителя. Во втором случае мы понятия не имеем, как это кодифицировать: ответ может зависеть от говорящих, размера и формы задействованных объектов, от того, шутит ли говорящий, и других аспектов контекста, в котором дано высказывание. Люди интуитивно понимают множество важных факторов, связанных с ответом на этот, казалось бы, обыденный вопрос.
Интерактивная оценка участниками-людьми может служить пробным камнем для понимания производительности агентов, но это шумно и дорого. Трудно контролировать точные инструкции, которые люди дают агентам при взаимодействии с ними для оценки. Этот вид оценки также выполняется в режиме реального времени, поэтому он слишком медленный, чтобы полагаться на быстрый прогресс. В предыдущих работах использовались прокси для интерактивной оценки. Заместители, такие как потери и запрограммированные исследовательские задачи (например, «поднимите х», где х выбирается случайным образом из среды, а функция успеха тщательно создается вручную), полезны для быстрого получения информации об агентах, но на самом деле не коррелируют. что хорошо с интерактивной оценкой. Наш новый метод имеет преимущества, в основном предоставляя контроль и скорость для метрики, которая тесно связана с нашей конечной целью — создать агентов, которые хорошо взаимодействуют с людьми.
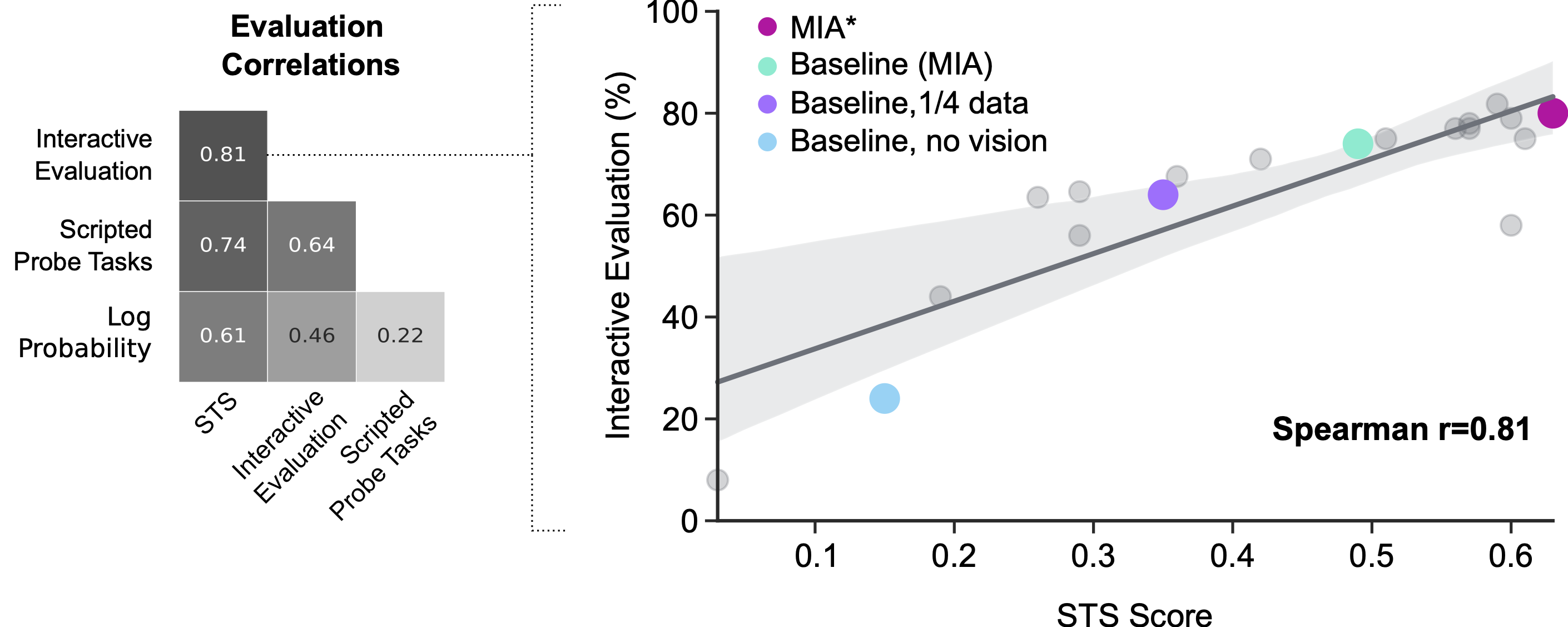
Разработка MNIST, ImageNet и других наборов данных, аннотированных человеком, была необходима для прогресса в машинном обучении. Эти наборы данных позволили исследователям обучать и оценивать модели классификации за единовременные затраты на человеческий фактор. Методология STS направлена на то же самое для исследования взаимодействия человека и агента. Этот метод оценки по-прежнему требует, чтобы люди аннотировали продолжения агента; однако ранние эксперименты предполагают, что автоматизация этих аннотаций возможна, что позволит быстро и эффективно автоматически оценивать интерактивные агенты. Тем временем мы надеемся, что другие исследователи смогут использовать методологию и дизайн системы для ускорения собственных исследований в этой области.