
Это совместный пост с Инбар Наор. Первоначально опубликовано на Engineering.taboola.com.
По мере того, как глубокие нейронные сети (ГНС) становятся более мощными, их сложность возрастает. Эта сложность создает новые проблемы, включая интерпретируемость модели.
Интерпретируемость имеет решающее значение для создания моделей, которые являются более надежными и устойчивыми к атакам злоумышленников. Более того, разработка модели для новой, недостаточно изученной области является сложной задачей, и способность интерпретировать то, что делает модель, может помочь нам в этом процессе.
Важность интерпретации модели побудила исследователей разработать разнообразие методов за последние несколько лет и весь мастерская был посвящен этой теме на конференции NIPS в прошлом году. Эти методы включают в себя:
Прежде чем мы углубимся в то, как использовать неопределенность для отладки и интерпретации ваших моделей, давайте поймем, почему неопределенность важна.
Одним из ярких примеров являются приложения с высоким риском. Допустим, вы строите модель, которая помогает врачам выбирать предпочтительное лечение для пациентов. В этом случае мы должны заботиться не только о точности модели, но и о том, насколько модель уверена в своих предсказаниях. Если неопределенность слишком высока, врач должен принять это во внимание.
Беспилотные автомобили — еще один интересный пример. Когда модель не уверена, есть ли на дороге пешеход, мы можем использовать эту информацию, чтобы замедлить машину или активировать предупреждение, чтобы водитель мог взять на себя ответственность.
Неопределенность также может помочь нам с примерами отсутствия данных. Если модель не обучалась на примерах, похожих на имеющийся образец, было бы лучше, если бы она могла сказать «извините, я не знаю». Это могло бы предотвратить неловкую ошибку, допущенную Google photos, когда они ошибочно классифицировали афроамериканцев как горилл. Подобные ошибки иногда случаются из-за недостаточно разнообразной обучающей выборки.
Последнее использование неопределенности, которое является целью этого поста, — это инструмент для практиков для отладки своей модели. Мы углубимся в это через мгновение, но сначала давайте поговорим о различных типах неопределенности.
Существуют разные типы неопределенности и моделирования, и каждый из них полезен для разных целей.
Неопределенность модели, также известная как эпистемическая неопределенность: допустим, у вас есть одна точка данных, и вы хотите знать, какая линейная модель лучше всего объясняет ваши данные. Нет хорошего способа выбирать между разными линиями на картинке — нам нужно больше данных!
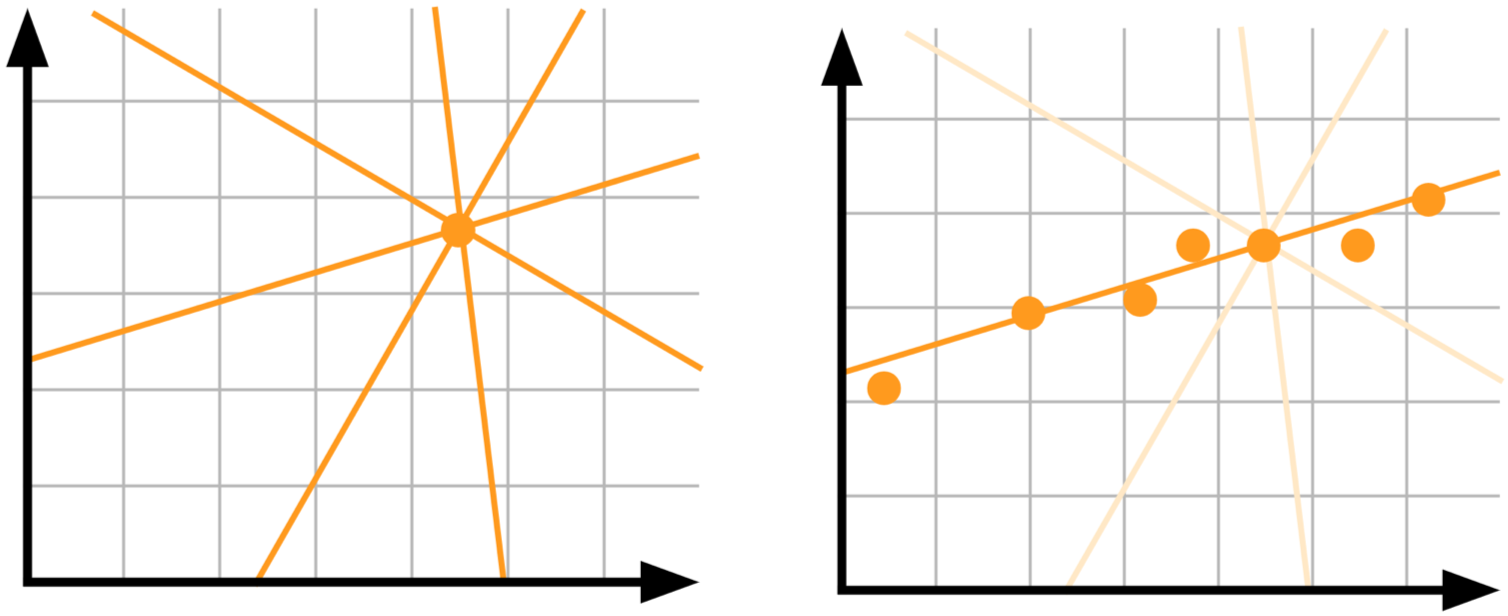
Слева: недостаток данных приводит к высокой неопределенности. Справа: при большем количестве данных неопределенность уменьшается.
Эпистемическая неопределенность объясняет неопределенность параметра модели. Мы не уверены, какие веса моделей лучше всего описывают данные, но с учетом большего количества данных наша неопределенность уменьшается. Этот тип неопределенности важен в приложениях с высоким риском и при работе с небольшими и разреженными данными.

В качестве примера предположим, что вы хотите построить модель, которая получает изображение животного и предсказывает, попытается ли это животное вас съесть. Допустим, вы обучали модель на разных картинках львов и жирафов и теперь она увидела зомби. Поскольку модель не обучалась на изображениях зомби, неопределенность будет высокой. Эта неопределенность является результатом модели, и при наличии достаточного количества изображений зомби она будет уменьшаться.
Неопределенность данных, или алеаторическая неопределенность, улавливает шум, присущий наблюдению. Иногда сам мир является стохастическим. Получение дополнительных данных в этом случае нам не поможет, потому что шум заложен в данных.
Чтобы понять этот момент, давайте вернемся к нашей модели плотоядных животных. Наша модель может распознать, что изображение содержит льва, и поэтому вас, скорее всего, съедят. Но что, если этот лев сейчас не голоден? На этот раз неопределенность исходит из данных. Другой пример — две змеи, которые выглядят одинаково, но одна из них ядовита, а другая — нет.
Алеаторическая неопределенность делится на два типа:
- Гомоскедастическая неопределенность: неопределенность одинакова для всех входных данных.
- Гетероскедастическая неопределенность: неопределенность, зависящая от конкретных входных данных. Например, для модели, которая предсказывает глубину изображения Ожидается, что безликая стена будет иметь более высокий уровень неопределенности, чем у изображения с четкими исчезающими линиями.
Погрешность измерения: еще одним источником неопределенности является само измерение. Когда измерение зашумлено, неопределенность увеличивается. В примере с животными уверенность модели может быть подорвана, если некоторые снимки сделаны камерой плохого качества; или если бы мы убегали от страшного бегемота, и в результате у нас были бы только размытые изображения для работы.
Шумные этикетки: при обучении с учителем мы используем метки для обучения моделей. Если метки зашумлены, неопределенность возрастает.
Существуют различные способы моделирования каждого типа неопределенности. Они будут рассмотрены в следующих постах этой серии. А пока предположим, что у нас есть модель черного ящика, которая демонстрирует неопределенность своих прогнозов. Как мы можем использовать его для отладки модели?
Давайте рассмотрим одну из наших моделей в Taboola, используемую для прогнозирования вероятности того, что пользователь нажмет на рекомендацию контента, также известную как CTR (Click Through Rate).
Модель имеет много категориальных признаков. представлен векторами вложения. У модели могут возникнуть трудности с изучением обобщенных вложений для редких значений. Обычный способ решить эту проблему — использовать специальное вложение Out Of Vocabulary (OOV).
Подумайте о рекламодателе статьи. Все редкие рекламодатели используют одно и то же встраивание OOV, поэтому с точки зрения модели они по сути являются одним рекламодателем. У этого рекламодателя OOV много разных элементов, каждый из которых имеет разный CTR. Если бы мы использовали только рекламодателя в качестве предиктора CTR, мы должны были бы получить высокую неопределенность для OOV.
Чтобы проверить, что модель выдает высокую неопределенность для OOV, мы взяли проверочный набор и переключили все вложения рекламодателей в OOV. Затем мы проверили, какова была неопределенность до и после переключения. Как и ожидалось, неопределенность увеличилась из-за переключения. Модель смогла узнать, что при наличии информативного рекламодателя неопределенность должна уменьшиться.
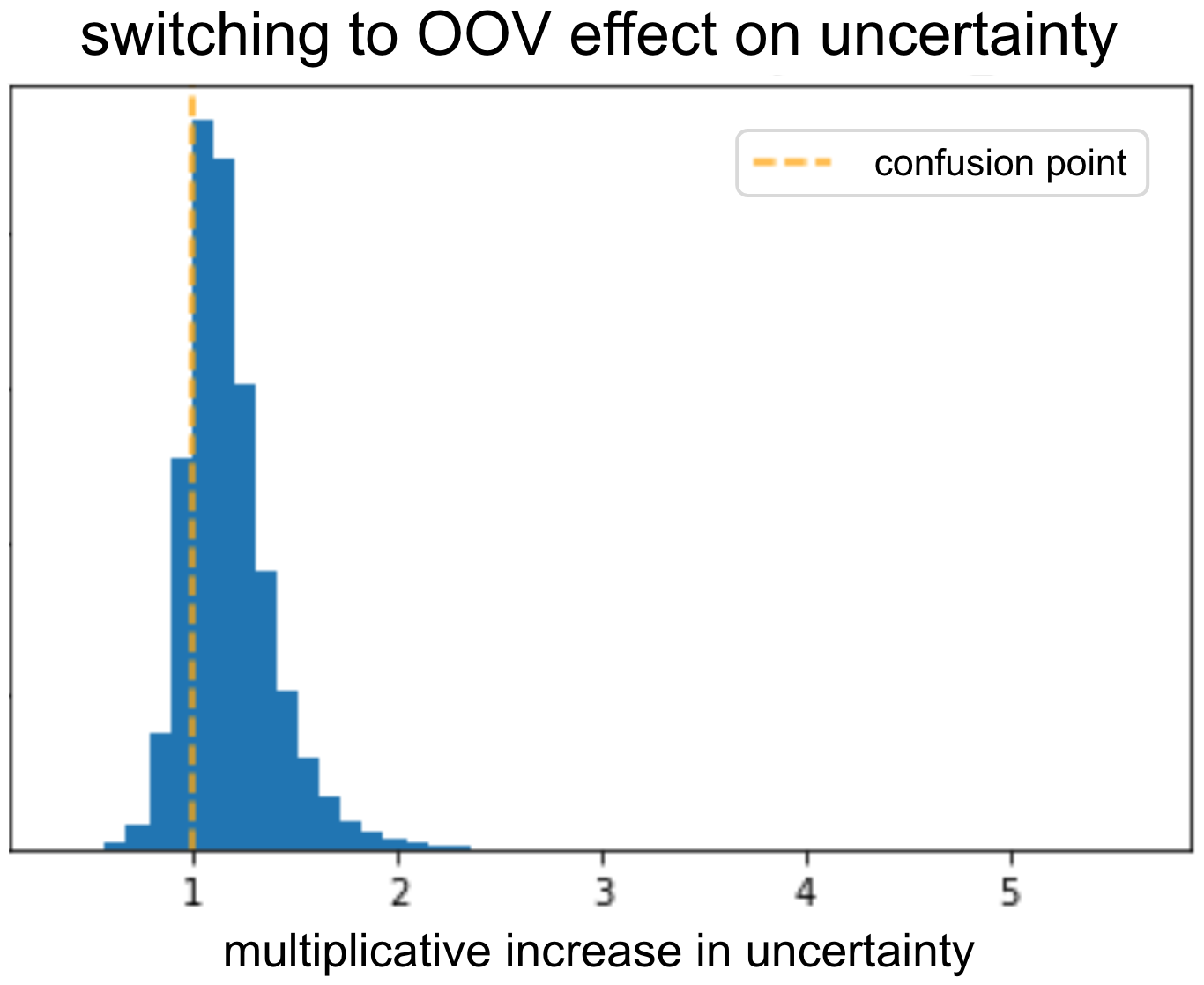
Мы можем повторить это для разных функций и искать те, которые приводят к низкой неопределенности при замене вложениями OOV. Либо эти функции неинформативны, либо что-то в том, как мы подаем их в модель, неидеально.
Мы можем даже перейти к более тонкой детализации: некоторые рекламодатели имеют высокую изменчивость между CTR разных элементов, в то время как у других есть элементы с примерно одинаковым CTR. Мы ожидаем, что модель будет иметь более высокую неопределенность для рекламодателей первого типа. Поэтому полезным анализом является рассмотрение корреляции между неопределенностью и изменчивостью CTR у рекламодателя. Если корреляция не является положительной, это означает, что модель не смогла определить, какую неопределенность следует связать с каждым рекламодателем. Этот инструмент позволяет нам понять, если что-то пошло не так в процессе обучения или в архитектуре модели, указывая на то, что нам следует продолжить ее отладку.
Мы можем выполнить аналогичный анализ и посмотреть, уменьшается ли неопределенность, связанная с конкретным элементом, чем больше раз мы его показываем (т.е. показываем большему количеству пользователей/в большем количестве мест). Опять же, мы ожидаем, что модель станет более определенной, а если нет — отладим!
Еще один классный пример — функция заголовков: уникальные заголовки с редкими словами должны вызывать высокую неопределенность модели. Это результат того, что модель не видит много примеров из этой области всех возможных заголовков. Мы можем найти в проверочном наборе группу похожих названий, которые встречаются редко, и оценить неопределенность модели для этих названий. Затем мы переобучим модель, используя один из заголовков, и посмотрим, уменьшилась ли неопределенность для всей группы. Действительно, мы видим, что именно это и произошло:
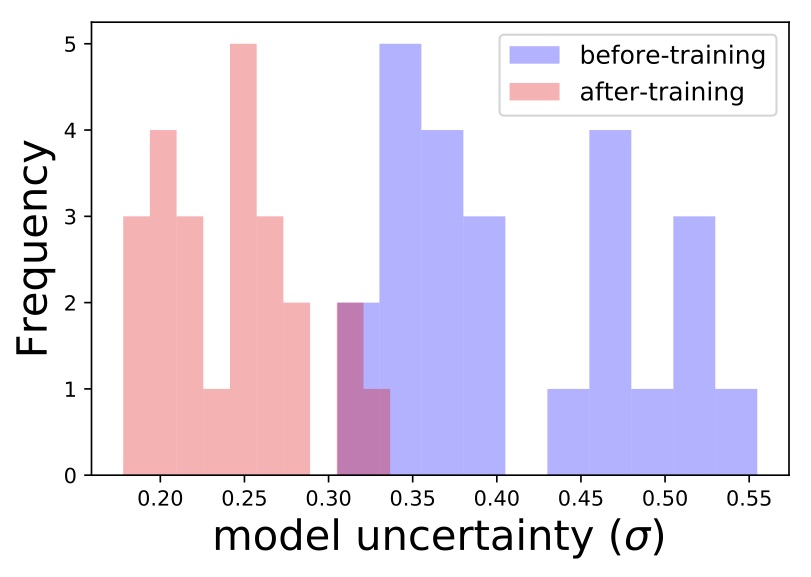
Подождите секунду… Подвергнув модель некоторым названиям, она стала лучше и стала более уверенной в отношении кучи новых названий. Может быть, мы можем использовать это, чтобы как-то стимулировать исследование новых предметов? Ну да, мы можем! Об этом в следующем посте серии.
Неопределенность имеет большое значение во многих областях. Определение важного типа неопределенности зависит от конкретного приложения. Вы можете использовать их по-разному, если знаете, как их моделировать. В этом посте мы обсудили, как вы можете использовать их для отладки вашей модели. В следующем посте мы поговорим о различных способах получения оценок неопределенности из вашей модели.
Это первый пост из серии статей, которые мы представляем на семинаре конференции KDD в этом году: сети с высокой плотностью и неопределенность в рекомендательных системах.