
Представляем платформу для создания агентов ИИ, которые могут понимать человеческие инструкции и выполнять действия в открытых условиях.
Поведение человека удивительно сложно. Даже простая просьба типа “Положите мяч близко к коробке” по-прежнему требует глубокого понимания ситуативного намерения и языка. Значение такого слова, как «близко», может быть трудно определить – размещение мяча внутри коробка может быть технически ближайшей, но, вероятно, говорящий хочет, чтобы мяч был помещен рядом с коробка. Чтобы человек правильно отреагировал на запрос, он должен уметь понимать и оценивать ситуацию и окружающий контекст.
Большинство исследователей искусственного интеллекта (ИИ) теперь считают, что написание компьютерного кода, который может фиксировать нюансы ситуативных взаимодействий, невозможно. В качестве альтернативы, современные исследователи машинного обучения (ML) сосредоточились на изучении этих типов взаимодействий из данных. Чтобы изучить эти основанные на обучении подходы и быстро создать агентов, способных понимать человеческие инструкции и безопасно выполнять действия в неограниченных условиях, мы создали исследовательскую структуру в среде видеоигр.
Сегодня мы публикация статьи и коллекция видеопоказывающий наши первые шаги в создании ИИ для видеоигр, которые могут понимать нечеткие человеческие концепции и, следовательно, могут начать взаимодействовать с людьми на их собственных условиях.
Большая часть недавнего прогресса в обучении искусственного интеллекта видеоигр основана на оптимизации счета игры. Мощные агенты ИИ для StarCraft и Дота были обучены с использованием четких выигрышей/проигрышей, рассчитанных компьютерным кодом. Вместо того, чтобы оптимизировать игровой счет, мы просим людей придумывать задачи и самим оценивать прогресс.
Используя этот подход, мы разработали исследовательскую парадигму, которая позволяет нам улучшать поведение агентов посредством обоснованного и открытого взаимодействия с людьми. Хотя эта парадигма все еще находится в зачаточном состоянии, она создает агентов, которые могут слушать, говорить, задавать вопросы, перемещаться, искать и извлекать, манипулировать объектами и выполнять многие другие действия в режиме реального времени.
Эта компиляция показывает поведение агентов при выполнении задач, поставленных участниками-людьми:

Обучение в «игровом домике»
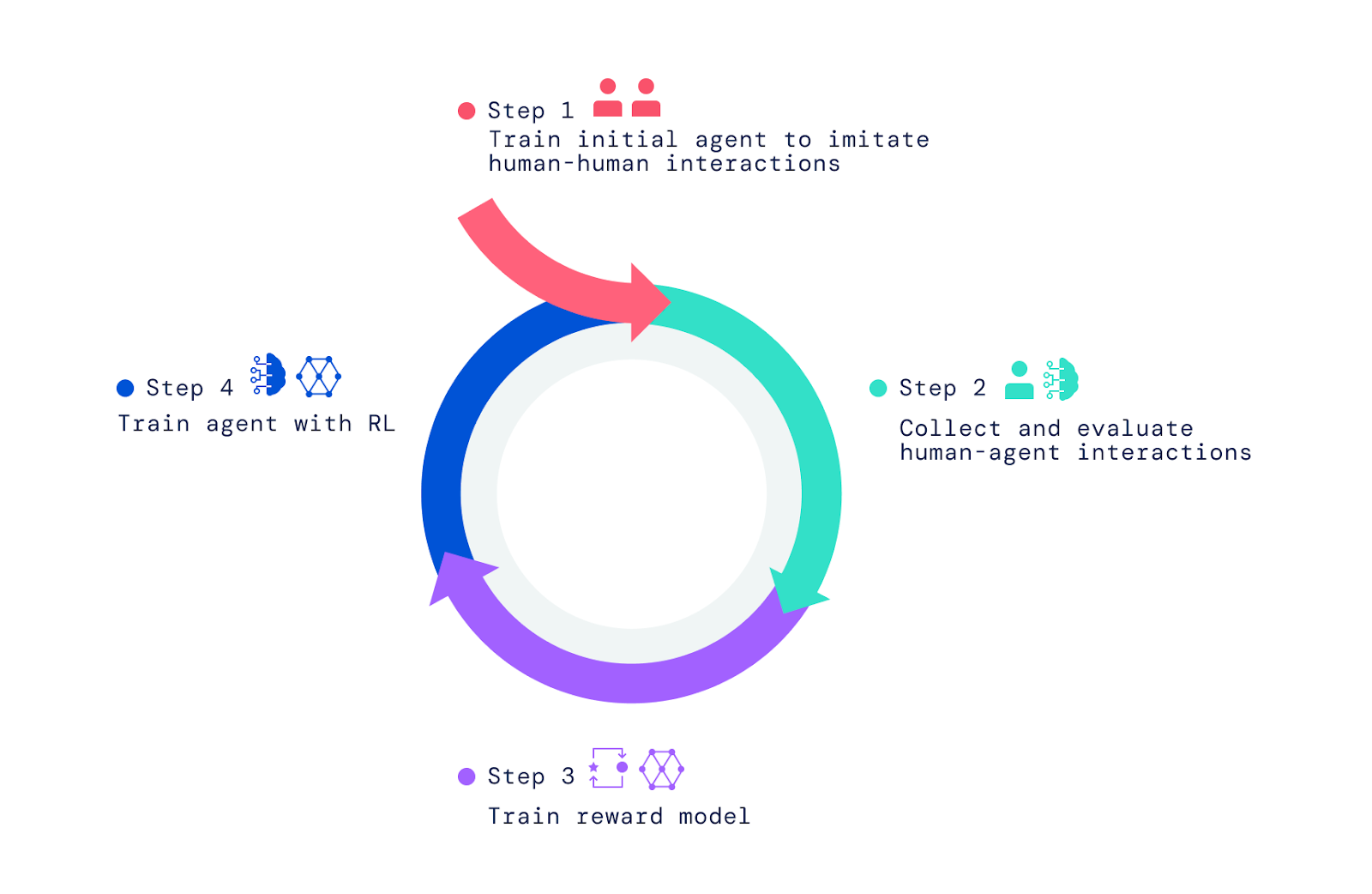
Наша структура начинается с взаимодействия людей с другими людьми в мире видеоигр. Используя имитационное обучение, мы наделили агентов широким, но не уточненным набором моделей поведения. Это «предварительное поведение» имеет решающее значение для обеспечения взаимодействий, которые могут быть оценены людьми. Без этой начальной фазы имитации агенты совершенно случайны, и с ними практически невозможно взаимодействовать. Дальнейшее человеческое суждение о поведении агента и оптимизация этих суждений с помощью обучения с подкреплением (RL) дает лучших агентов, которых затем можно снова улучшить.
Сначала мы построили простой мир видеоигры, основанный на концепции детского «игрового домика». Эта среда обеспечивала безопасную среду для взаимодействия людей и агентов и упрощала быстрый сбор больших объемов данных об этих взаимодействиях. В доме было множество комнат, мебели и предметов, настроенных по-новому для каждого взаимодействия. Также мы создали интерфейс для взаимодействия.
И у человека, и у агента есть аватар в игре, который позволяет им перемещаться в окружающей среде и манипулировать ею. Они также могут общаться друг с другом в режиме реального времени и совместно выполнять действия, такие как перенос предметов и передача их друг другу, строительство башни из блоков или совместная уборка комнаты. Участники-люди устанавливают контекст для взаимодействия, перемещаясь по миру, устанавливая цели и задавая вопросы агентам. В общей сложности проект собрал более 25 лет взаимодействия в реальном времени между агентами и сотнями (людей) участников.
Наблюдение за формирующимся поведением
Агенты, которых мы обучили, способны выполнять огромное количество задач, некоторые из которых не предполагались создавшими их исследователями. Например, мы обнаружили, что эти агенты могут выстраивать ряды объектов, используя два чередующихся цвета, или извлекать из дома объект, похожий на другой объект, который держит пользователь.
Эти сюрпризы возникают потому, что язык позволяет решать почти бесконечный набор задач и вопросов посредством композиции простых значений. Кроме того, как исследователи, мы не уточняем детали поведения агентов. Вместо этого сотни людей, которые участвуют во взаимодействии, придумали задачи и вопросы в ходе этих взаимодействий.
Создание основы для создания этих агентов
Чтобы создать наших агентов ИИ, мы применили три шага. Мы начали с обучения агентов имитации основных элементов простых человеческих взаимодействий, в которых один человек просит другого что-то сделать или ответить на вопрос. Мы называем эту фазу созданием поведенческого априора, который позволяет агентам иметь значимые взаимодействия с человеком с высокой частотой. Без этой имитационной фазы агенты просто двигаются беспорядочно и говорят чепуху. С ними почти невозможно взаимодействовать каким-либо разумным образом, а давать им обратную связь еще труднее. Этот этап был рассмотрен в двух наших предыдущих статьях, Имитация интерактивного интеллектаи Создание мультимодальных интерактивных агентов с имитацией и обучением с самоконтролемв котором изучалось создание агентов на основе имитации.
Выход за рамки имитационного обучения
Хотя имитационное обучение приводит к интересным взаимодействиям, оно рассматривает каждый момент взаимодействия как одинаково важный. Чтобы научиться эффективному, целенаправленному поведению, агент должен преследовать цель и овладеть определенными движениями и решениями в ключевые моменты. Например, агенты, основанные на имитации, не могут надежно срезать путь или выполнять задачи с большей ловкостью, чем средний игрок-человек.
Здесь мы показываем агента, основанного на имитационном обучении, и агента, основанного на RL, которые следуют одной и той же инструкции человека:
Чтобы наделить наших агентов целеустремленностью, превосходящей возможности имитации, мы полагались на RL, который использует метод проб и ошибок в сочетании с мерой производительности для итеративного улучшения. Когда наши агенты пробовали разные действия, те из них, которые повышали производительность, усиливались, а те, которые снижали производительность, наказывались.
В таких играх, как Atari, Dota, Go и StarCraft, оценка является показателем производительности, который необходимо улучшить. Вместо того, чтобы использовать оценку, мы попросили людей оценить ситуацию и предоставить обратную связь, что помогло нашим агентам учиться образец вознаграждения.
Обучение модели вознаграждения и оптимизация агентов
Чтобы обучить модель вознаграждения, мы попросили людей оценить, наблюдали ли они события, свидетельствующие о заметном прогрессе в достижении текущей поставленной цели, или о заметных ошибках или ошибках. Затем мы установили соответствие между этими положительными и отрицательными событиями и положительными и отрицательными предпочтениями. Поскольку они происходят во времени, мы называем эти суждения «межвременными». Мы обучили нейронную сеть предсказывать эти предпочтения человека и получили в результате модель вознаграждения (или полезности/оценки), отражающую обратную связь человека.
Как только мы обучили модель вознаграждения с использованием человеческих предпочтений, мы использовали ее для оптимизации агентов. Мы поместили наших агентов в симулятор и попросили их отвечать на вопросы и следовать инструкциям. Когда они действовали и говорили в окружающей среде, наша обученная модель вознаграждения оценивала их поведение, и мы использовали алгоритм RL для оптимизации производительности агентов.
Так откуда же берутся инструкции и вопросы? Для этого мы исследовали два подхода. Во-первых, мы переработали задачи и вопросы, заданные в нашем наборе данных о людях. Во-вторых, мы обучили агентов подражать тому, как люди ставят задачи и задают вопросы, как показано в этом видео, где два агента, один из которых обучен подражать людям, ставящим задачи и задающим вопросы (синий), а другой обучен следовать инструкциям и отвечать на вопросы (желтый). , взаимодействуют друг с другом:
Оценка и итерация для дальнейшего улучшения агентов
Мы использовали различные независимые механизмы для оценки наших агентов, от написанных вручную тестов до нового механизма автономной оценки людьми открытых задач, созданных людьми, разработанного в нашей предыдущей работе «Оценка мультимодальных интерактивных агентов». Важно отметить, что мы попросили людей взаимодействовать с нашими агентами в режиме реального времени и оценивать их работу. Наши агенты, обученные с помощью RL, работали намного лучше, чем те, которые были обучены только с помощью имитационного обучения.
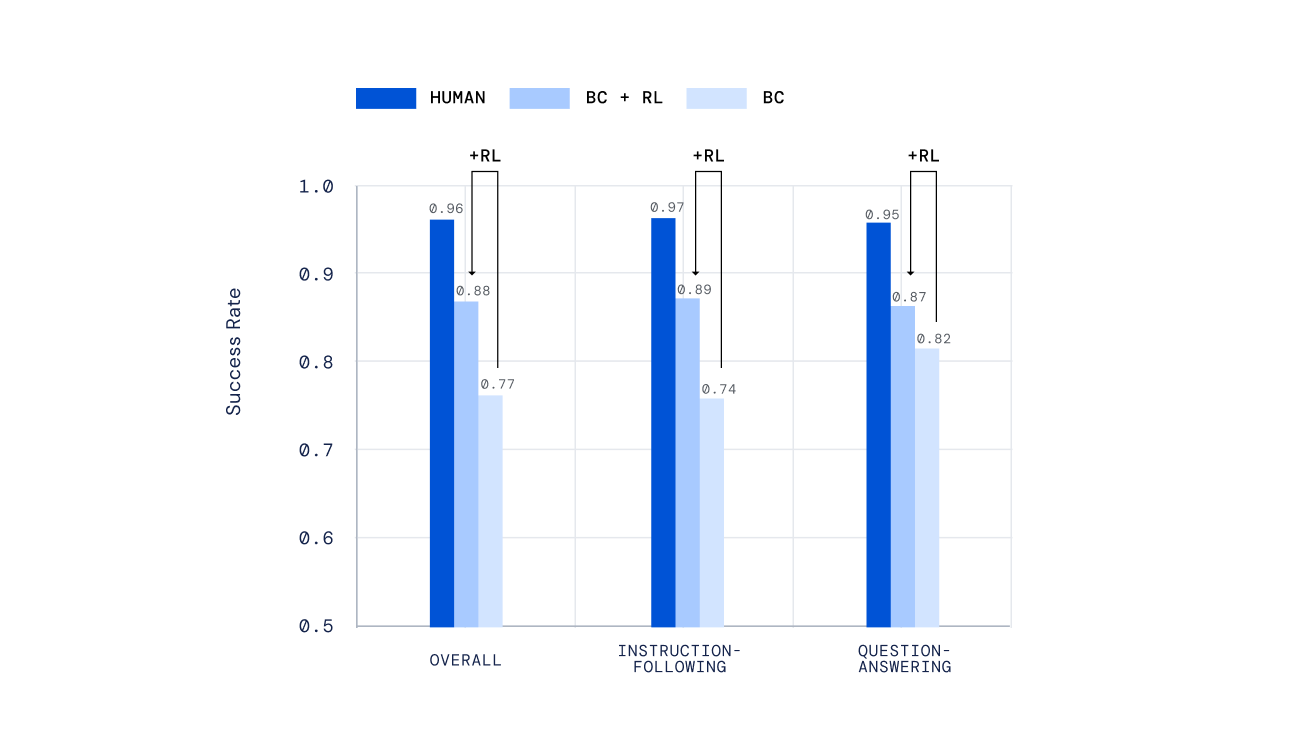
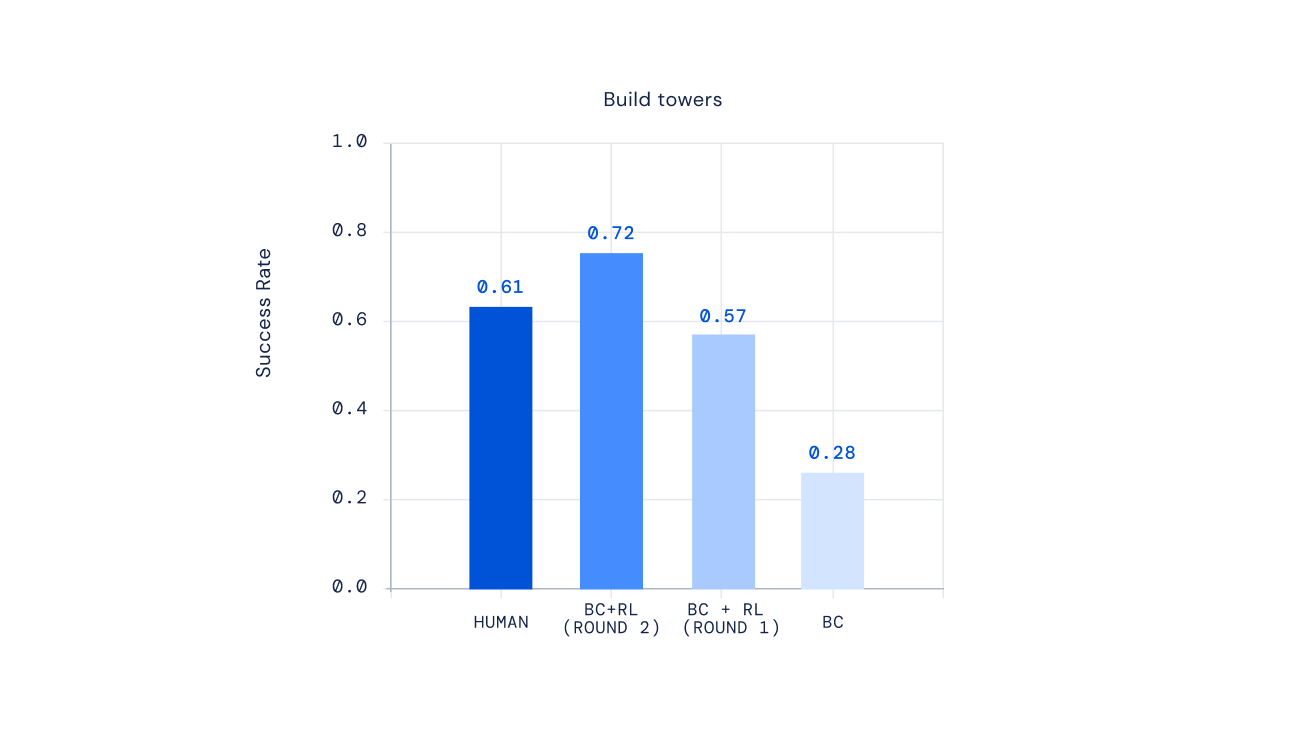
Наконец, недавние эксперименты показывают, что мы можем итерировать процесс RL для многократного улучшения поведения агента. После обучения агента с помощью RL мы попросили людей взаимодействовать с этим новым агентом, аннотировать его поведение, обновить нашу модель вознаграждения, а затем выполнить еще одну итерацию RL. Результатом такого подхода стали более компетентные агенты. Для некоторых типов сложных инструкций мы могли бы даже создать агентов, которые в среднем превосходили игроков-людей.
Будущее обучения ИИ ситуативным человеческим предпочтениям
Идея обучения ИИ с использованием человеческих предпочтений в качестве вознаграждения существует уже давно. В глубоком обучении с подкреплением на основе человеческих предпочтений исследователи впервые применили недавние подходы к согласованию агентов на основе нейронных сетей с человеческими предпочтениями. Недавняя работа по разработке пошаговых диалоговых агентов исследовала аналогичные идеи для помощники по обучению с RL от человека обратной связи. Наше исследование адаптировало и расширило эти идеи для создания гибких ИИ, которые могут освоить широкий спектр многомодальных, воплощенных взаимодействий с людьми в реальном времени.
Мы надеемся, что наша структура может когда-нибудь привести к созданию игровых ИИ, способных реагировать на наши естественные смыслы, а не полагаться на разработанные вручную планы поведения. Наша структура также может быть полезна для создания цифровых и роботизированных помощников, с которыми люди будут взаимодействовать каждый день. Мы с нетерпением ждем изучения возможности применения элементов этой структуры для создания действительно полезного безопасного ИИ.
Хотите узнать больше? Проверить наша последняя статья. Отзывы и комментарии приветствуются.