Это совместный пост с Инбар Наор. Первоначально опубликовано на Engineering.taboola.com.
Теперь, когда мы знаем какие типы неопределенности существуют и научился их моделироватьмы можем начать говорить о том, как использовать их в нашем приложении.
В этом посте мы представим проблему разведки-эксплуатации и покажем, как неопределенность может помочь в ее решении. Мы сосредоточимся на исследованиях в рекомендательных системах, но ту же идею можно применить во многих приложениях обучения с подкреплением — самоуправляемых автомобилях, роботах и т. д.
Цель рекомендательной системы — рекомендовать элементы, которые пользователи могут счесть релевантными. В Taboola релевантность выражается кликом: мы показываем виджет с рекомендациями по контенту, и пользователи выбирают, хотят ли они нажать на один из элементов.
Вероятность того, что пользователь нажмет на элемент, называется Рейтинг кликов
(CTR). Если бы мы знали CTR всех элементов, проблема того, какие элементы рекомендовать, была бы простой: просто рекомендуем элементы с самым высоким CTR.
Проблема в том, что мы не знаем, что такое CTR. У нас есть модель, которая его оценивает, но она явно не идеальна. Некоторыми из причин несовершенства являются типы неопределенности, присущие рекомендательным системам, которые мы обсуждали в первый пост из серии.

Итак, теперь мы сталкиваемся со сложной ситуацией, с которой мы все знакомы из нашей повседневной жизни: представьте, что вы только что вошли в магазин мороженого. Теперь вам предстоит ответственное решение — из примерно 30 вкусов вам нужно выбрать только один!
Вы можете использовать две стратегии: либо использовать свой любимый вкус, который, как вы уже знаете, является лучшим; или исследуйте новые вкусы, которые вы никогда не пробовали раньше, и, возможно, найдите новый лучший вкус.
Эти две стратегии — использование и исследование — также можно использовать при рекомендации контента. Мы можем либо использовать элементы с высоким CTR с высокой степенью уверенности — возможно, потому, что эти элементы были показаны тысячам раз похожим пользователям; или мы можем исследовать новые элементы, которые мы не показывали многим пользователям в прошлом. Включение исследования в вашу стратегию рекомендаций имеет решающее значение — без этого новые элементы не имеют шансов по сравнению со старыми, более знакомыми.
Самый простой подход к исследованию-эксплуатации, который вы можете реализовать, — это ϵ-жадный алгоритм, в котором вы случайным образом выделяете ϵ процентов трафика для изучения новых элементов. Остальной трафик зарезервирован для эксплуатации.
Несмотря на то, что этот метод не является оптимальным, его легко понять. Он может служить надежной основой для более сложных подходов. Так как же нам разумнее искать хорошие вещи?

искать хорошие вещи с умом
Более продвинутый подход — Верхняя доверительная граница (UCB) — использует неопределенность. Каждый элемент связан с его ожидаемым CTR и доверительной границей этого CTR. Граница достоверности показывает, насколько мы не уверены в CTR элемента. Стандартный алгоритм UCB отслеживает ожидаемый CTR и доверительный интервал, используя только эмпирическую информацию: для каждого элемента мы отслеживаем эмпирический CTR (какой процент похожих пользователей щелкнул по нему), а доверительный интервал рассчитывается, исходя из предположения биномиальное распределение.
Возьмем, к примеру, простой шоколадный вкус, который вы всегда заказываете. Вы знаете, что это хорошо — вы даете ему 8 звезд из 10. Сегодня прибыл новый вкус. У вас нет эмпирической информации об этом, а значит, это может быть от 1 до 10 звезд. Используя этот доверительный интервал, если вы хотите исследовать, вы бы выбрали новый аромат, поскольку есть шанс, что он будет ароматом 10 звезд.
Именно эта стратегия и представляет собой UCB — вы выбираете элемент с наивысшим значением верхней границы достоверности — в нашем случае доверительная граница оценки CTR. Мотивация этой стратегии заключается в том, что со временем эмпирический CTR будет стремиться к истинному CTR, а граница достоверности уменьшится до 0. По прошествии достаточного количества времени мы все изучим.
Еще одним популярным подходом является Томпсон Сэмплинг метод. В этом подходе мы используем полное расчетное распределение CTR элемента, а не только доверительную границу. Для каждого элемента мы выбираем CTR из его распределения.
Эти подходы могут хорошо работать, когда количество доступных элементов фиксировано. К сожалению, в Taboola каждый день в систему поступают тысячи новых элементов, а другие устаревают. К тому времени, когда мы получим разумную доверительную границу для элемента, он может покинуть систему. Наши усилия были бы напрасны. Это похоже на кругосветное путешествие, каждый день посещая новый город с огромным количеством вкусов мороженого для изучения. Ужас!
Нам нужен подход, который может оценить CTR нового товара, не показывая его ни разу. Нам нужен какой-нибудь журнал кулинарных критиков, который проведет нас через буфет рекомендаций по содержанию.
Рассмотрим новый тип вкуса шоколада, который только что появился. Поскольку вы знаете, что любите шоколад, вы вполне можете предположить, что вам понравится и новый вкус. В ванильном подходе UCB (нет, это не название аромата) вы не сможете его вывести — вы полагаетесь только на эмпирическую информацию.
В следующем посте мы подробно расскажем о том, как мы используем нейронную сеть для оценки CTR нового товара, а также уровня неопределенности. Используя эту неопределенность, мы можем применить подход UCB для изучения новых элементов. В отличие от ванильного UCB, который опирается на эмпирические данные, здесь мы можем использовать оценку модели, чтобы не показывать товары с низким CTR. Мы можем поставить на тех лошадей, которые, по нашему мнению, выиграют.
🐎
Как мы можем узнать, насколько хорошо мы изучаем новые предметы? Нам нужна некоторая метрика пропускной способности разведки. В Taboola у нас есть инфраструктура A/B-тестирования, поддерживающая множество моделей, работающих на разных долях трафика.
Вернемся к мороженому! Допустим, вы привели своих друзей, чтобы помочь вам изучить различные вкусы. Очевидно, что если один из ваших друзей случайным образом выбирает вкус, у него будет лучшая производительность исследования, но не самая умная. Другой друг, который заказывает вкус, который другие сочли вкусным, получает больше всего удовольствия, но не вносит никакого вклада в усилия по исследованию.
В Taboola мы измеряем производительность исследования следующим образом: для каждого элемента, который был показан достаточное количество раз и в достаточном количестве различных контекстов (например, на разных веб-сайтах), мы объявляем, что этот элемент пересек фазу исследования. Далее мы анализируем, какие модели способствовали этому успеху. Чтобы подсчитать, модель должна показать этот предмет достаточное количество раз.
С этой точки зрения пропускная способность модели определяется как количество элементов, в которые она внесла свой вклад.
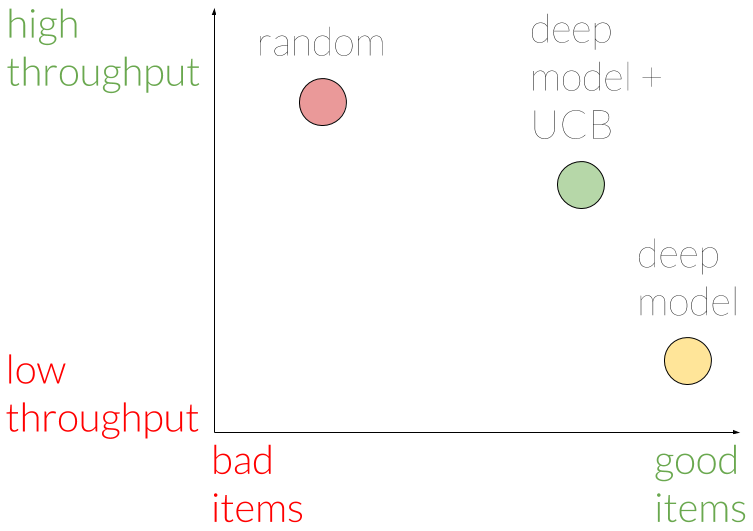
Используя эту метрику, мы смогли утверждать, что показ элементов в случайном порядке действительно обеспечивает наилучшую пропускную способность, но с тенденцией к некачественным элементам. Модель, не использующая подход UCB, показывает хорошие элементы, но имеет худшую пропускную способность. Модель с UCB находится где-то посередине с точки зрения пропускной способности и показывает лишь немного худшие элементы по сравнению с моделью без UCB.
Следовательно, мы заключаем, что наша модель UCB имеет хороший компромисс между изучением новых предметов и выбором хороших предметов. Мы считаем, что этот компромисс оправдан в долгосрочной перспективе.
Проблема разведки-эксплуатации является захватывающей задачей для многих компаний, работающих в области рекомендательных систем. Мы надеемся, что наши достижения помогут другим в их стремлении предоставлять лучший сервис своим пользователям. Мы считаем, что это маленький шаг в большом путешествии, которое еще предстоит совершить, и мы заинтригованы мыслью о том, какую форму примет эта область в последующие годы.
В следующем посте серии мы подробно расскажем о модели, которую мы использовали для оценки CTR и неопределенности, так что следите за обновлениями.
Это третий пост из серии статей, которые мы представляем на семинаре конференции KDD в этом году: сети с высокой плотностью и неопределенность в рекомендательных системах.
Первый пост можно найти
здесь.
Второй пост можно найти
здесь.