
Несколько дней назад OpenAI анонсировала нового преемника своей языковой модели (LM) — ГПТ-3. На данный момент это самая большая обученная модель со 175 миллиардами параметров. Хотя обучение этой большой модели имеет свои достоинства, чтение большой части из 72 страниц может быть утомительным. В этом сообщении в блоге я выделю части, которые я нахожу интересными для людей, знакомых с LM, которые просто хотят знать (большинство) важные моменты этой работы.
«Разнообразие задач, которые модель может выполнять в условиях нулевого выстрела, предполагает, что модели с высокой пропускной способностью, обученные максимизировать вероятность достаточно разнообразного текстового корпуса, начинают учиться выполнять удивительное количество задач без необходимости явного надзор”
Это отрывок из сопроводительная бумага ГПТ-2. GPT-3 делает еще один шаг в этом направлении.
В частности, авторы указывают на недостатки тонкой настройки с использованием наборов данных для конкретных задач.
-
Получить эти наборы данных сложно.
-
Тонкая настройка позволяет модели использовать ложные корреляции, которые приводят к плохой производительности вне распределения.
-
Краткой инструкции на естественном языке обычно достаточно, чтобы люди поняли поставленную задачу. Эта адаптивность является желаемым свойством систем НЛП.
Путь, который выбрали авторы, — это «обучение в контексте» — подача модели спецификации задачи (подсказки) и/или нескольких демонстраций задачи в качестве префикса, направляющая ее к подпространству в скрытом пространстве, которое придерживается Перевод, например, будет выглядеть так: «Вопрос: Какой {язык} перевод {предложения} А: {перевод}».
Это основано на предположении, что модель развивает широкий набор навыков и способностей распознавания образов во время обучения, а затем использует эти способности во время вывода, чтобы быстро адаптироваться или распознавать желаемую задачу.
Общеизвестно, что низкий уровень недоумения коррелирует с производительностью в последующих задачах, поэтому можно надеяться, что более крупные модели обеспечат лучшие возможности в контексте. И действительно, это так, как видно на следующем рисунке, где тестируется простая задача, требующая от модели удаления случайных символов из слова:
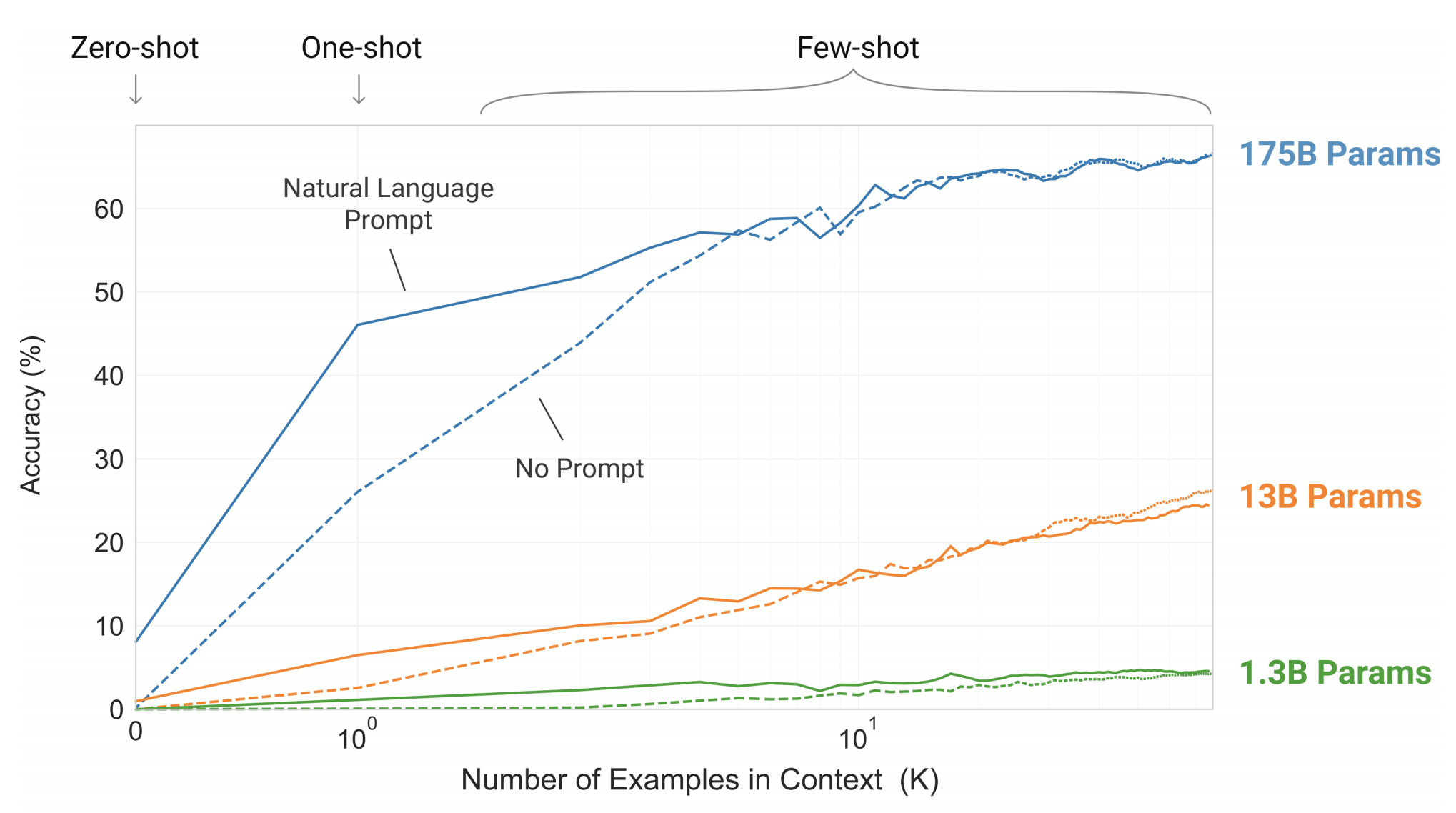
Количество контекстных примеров варьируется от 10 до 100, поскольку обычно это разрешено при размере контекста модели, равном 2048. Подсказка (спецификация задачи) играет важную роль, когда количество примеров невелико.
Авторы протестировали множество известных бенчмарков, но сначала давайте посмотрим на спецификацию модели.
GPT-3 состоит из архитектуры на основе Transformers, аналогичной GPT-2, включая описанные здесь модифицированную инициализацию, предварительную нормализацию и обратимую токенизацию, за исключением того, что он использует чередующиеся плотные и локально распределенные разреженные паттерны внимания в слоях. трансформатора, аналогичного разреженному трансформатору.
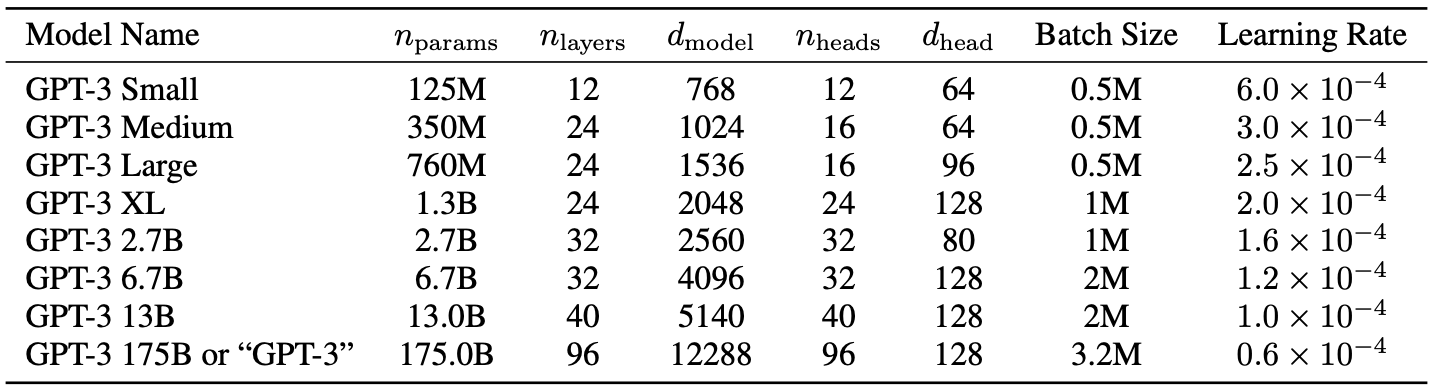
Авторы обучили модели нескольких размеров, варьирующиеся от 125 миллионов до 175 миллиардов параметров, чтобы измерить корреляцию между размером модели и производительностью тестов.
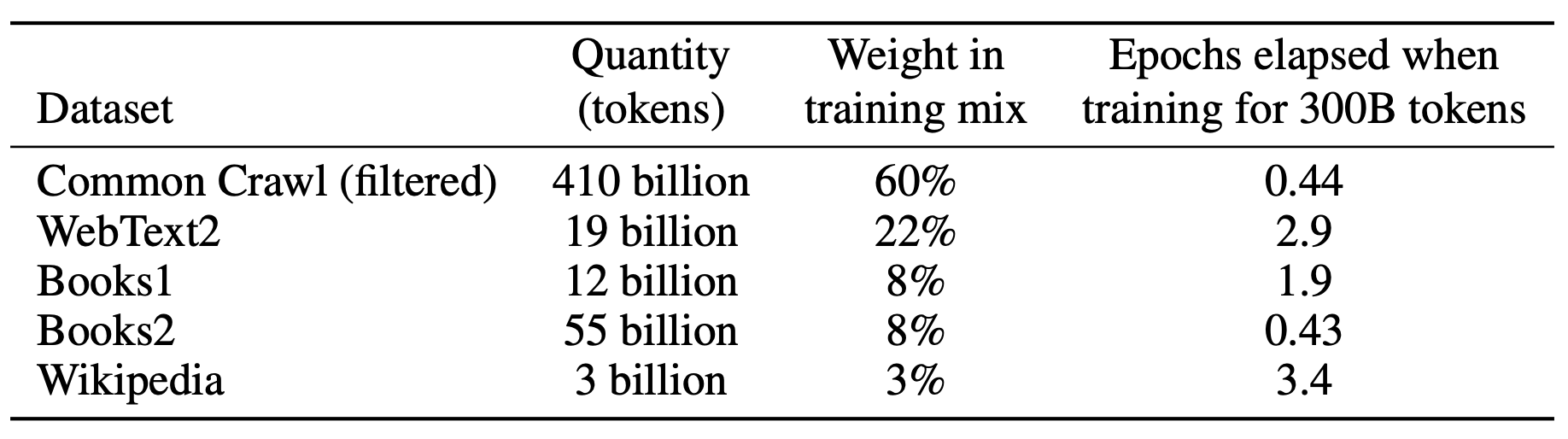
Авторы предприняли три шага для улучшения среднего качества наборов данных:
-
Они загрузили и отфильтровали версию CommonCrawl на основе сходства с рядом высококачественных справочных корпусов.
-
Они выполнили нечеткую дедупликацию, чтобы предотвратить избыточность и сохранить целостность отложенного проверочного набора.
-
Они добавили в тренировочный микс известные высококачественные корпуса.
На следующем рисунке мы видим, что сила закона LM по-прежнему выполняется:
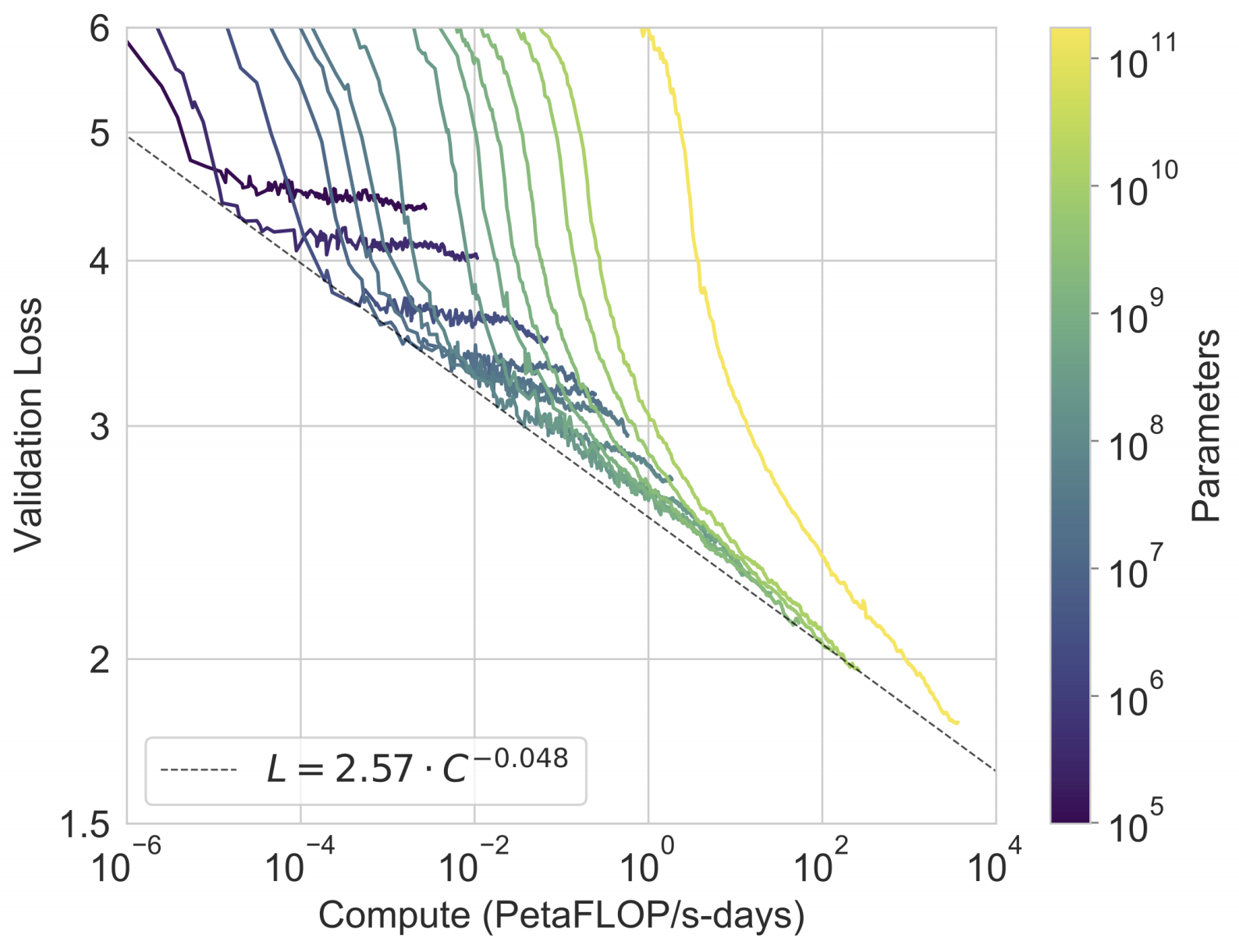
Чтобы проверить, коррелирует ли потеря предварительно обученной проверки с производительностью последующей задачи, авторы оценили исчерпывающий список известных эталонных показателей НЛП, предоставив K примеров из обучающего набора в контексте для оценки примера из тестового набора. В статье подробно описаны все бенчмарки, но здесь я решил описать только небольшую выборку:
Языковое моделирование
Несмотря на то, что PTB вынужден пропустить многие наборы данных, связанные с затруднениями при языковом моделировании, из-за сдерживания в обучающих данных, он избегает этой проблемы из-за того, что он предшествует современному Интернету, а GPT-3 устанавливает новую SOTA.
ЛАМБАДА
В этой задаче модель должна предсказать последнее слово заданного предложения. Недавно было высказано предположение, что дальнейшее масштабирование LM приводит к уменьшению отдачи от этого сложного эталона. И все же GPT-3 добился 76% точности при нулевой настройке — выигрыш на 8% по сравнению с предыдущей SOTA.
В настройке с несколькими кадрами задача может быть оформлена как задача закрытия (заполнение пробелов), что упрощает для модели понимание того, что требуется только одно слово. Это дает точность 86,4%.
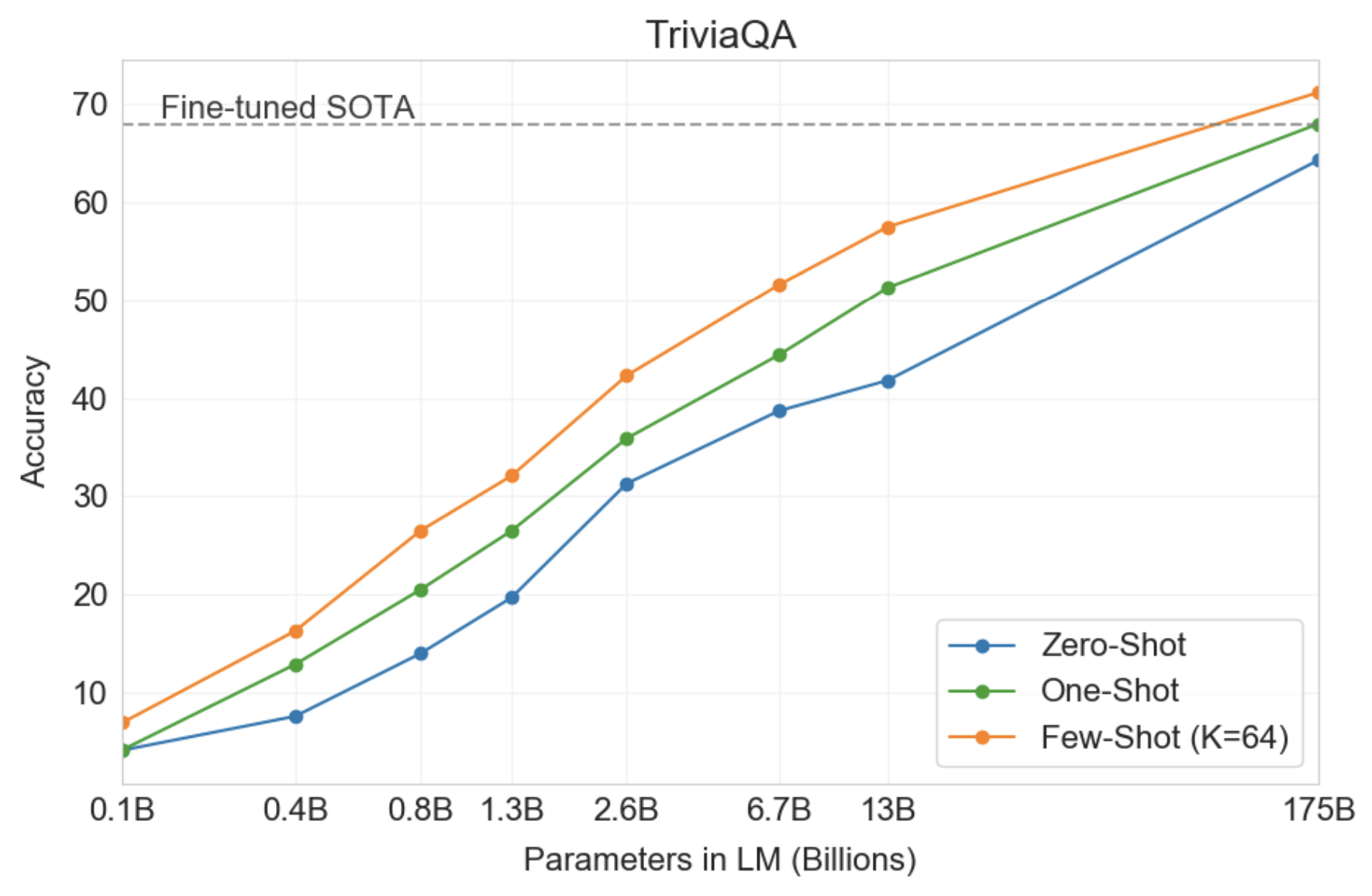
Ответ на вопрос о закрытой книге
В этой задаче GPT-3 превосходит SOTA, которая не только точно настраивает задачу, но также использует компонент поиска информации для извлечения фрагментов текстов, которые могут содержать ответ. Это говорит о том, что LM продолжают поглощать знания по мере увеличения их возможностей.
Супер клей
GPT-3 оказывается слабым в некоторых задачах, требующих сравнения двух предложений, включая определение того, используется ли слово одинаково в двух предложениях, является ли одно предложение парафразом другого или одно предложение подразумевает другое.
Генерация новостных статей
Авторы попросили людей-оценщиков различать новостные статьи, созданные человеком и машиной. По мере увеличения размера модели участники получали более низкие оценки точности, несмотря на увеличение затрат времени на каждую новостную статью. Это подтверждает вывод о том, что более крупные модели генерируют новостные статьи, которые труднее различить.
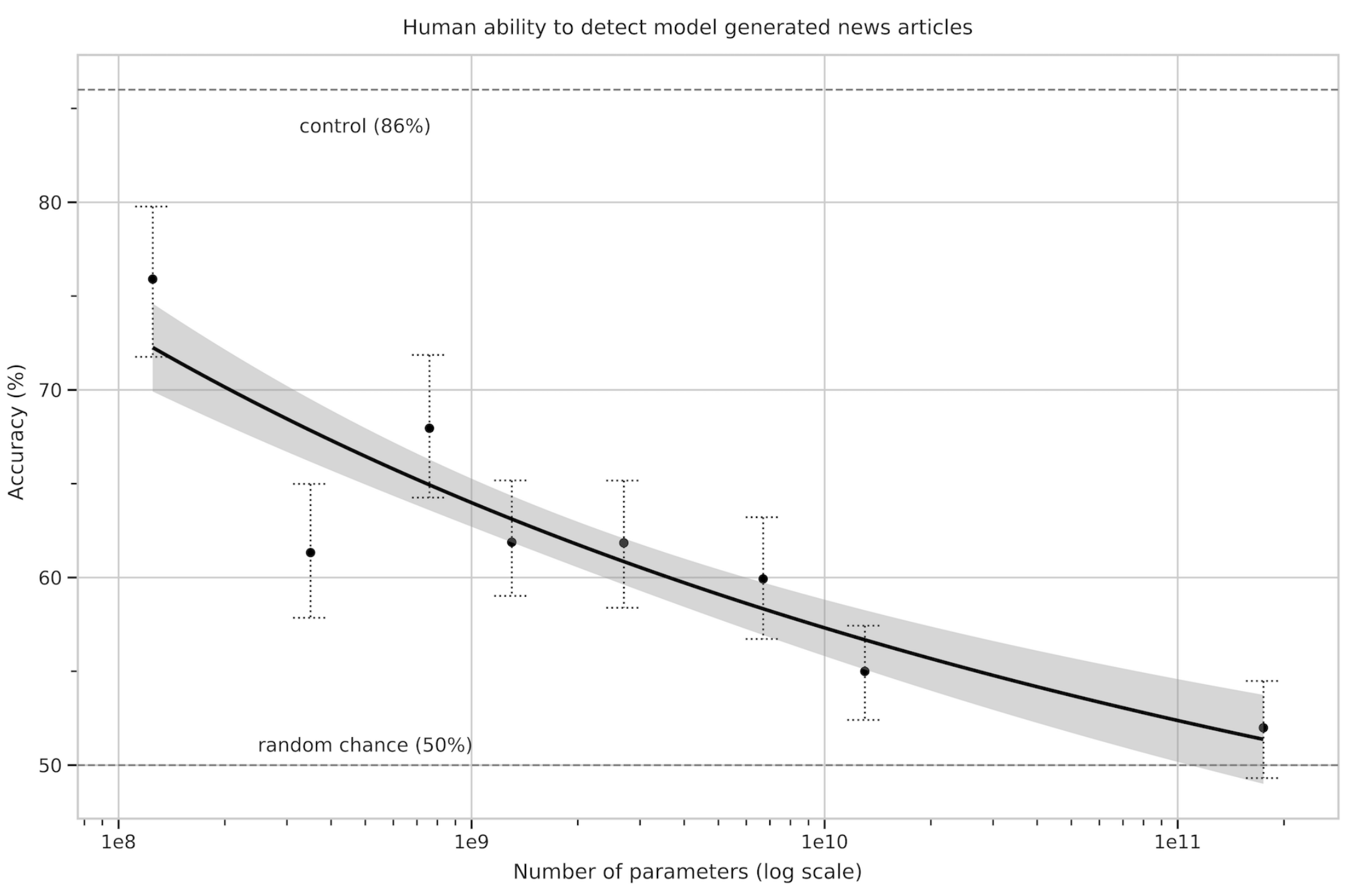
Точное обнаружение загрязнения тестов из наборов данных в масштабе Интернета — это новая область исследований, в которой нет устоявшихся передовых практик. По мере увеличения емкости модели возрастает риск запоминания. В целом авторы удалили документы, пересекающиеся с тестовым набором. Однако из-за ошибки в этом процессе остались остатки. Они пытались оценить ущерб, и похоже, что модель ничего не запоминает, и (большинство) результатов достоверны.
(Мое собственное замечание: возможно, пришло время для более тщательного тестирования в области машинного обучения в целом, как это принято в других областях.)
Хотя качественно GPT-3 лучше своего предшественника, его способность к синтезу текста по-прежнему имеет слабые места, знакомые нам по другим LM, такие как повторения, потеря связности на достаточно длинных пассажах и противоречия.
Кроме того, в некоторых задачах ГПТ-3 с треском провалилась. Это может быть связано с выбором использования авторегрессионного LM вместо включения двунаправленной информации (аналогично Берту). В то время как обучение в контексте более просто с авторегрессивными LM, известно, что двунаправленные модели лучше справляются с последующими задачами после тонкой настройки. В конце концов, обучение двунаправленной модели в масштабе GPT-3 и/или попытка заставить двунаправленные модели работать с помощью обучения за несколько шагов является многообещающим направлением для будущих исследований.
Более фундаментальное ограничение заключается в том, что авторегрессионные (и двунаправленные) модели могут в конечном итоге выйти (или уже могут выйти) за пределы цели предварительного обучения. Улучшение задачи, например, понимание того, что наиболее важно предсказать (например, объекты), может принести пользу модели. Заземление модели в других областях опыта, таких как видео или физическое взаимодействие в реальном мире, также может сдвинуть с места.
Свидетельством того, что задача предварительного обучения не является оптимальной, является эффективность выборки: GPT-3 видит во время предварительного обучения гораздо больше текста, чем человек видит за всю свою жизнь. Повышение эффективности выборки перед обучением является важным направлением будущей работы и может быть связано с изучением физического мира для предоставления дополнительной информации или с улучшением алгоритмов.
Более того, в случае с самоконтролируемыми целями спецификация задач зависит от включения желаемой задачи в проблему прогнозирования, тогда как, в конечном счете, полезные языковые системы (например, виртуальные помощники) лучше рассматривать как выполнение целенаправленных действий, а не просто прогнозирование.
Другим ограничением или, по крайней мере, неопределенностью, связанной с обучением за несколько попыток в GPT-3, является двусмысленность в отношении того, действительно ли обучение за несколько попыток изучает новые задачи «с нуля» во время вывода или оно просто распознает и идентифицирует задачи, которые он изучил. во время обучения.
И последнее, но не менее важное: размер модели несет в себе практические неудобства. Дистилляция, которую еще не пробовали в таких масштабах, — интересное направление.