
Несмотря на, казалось бы, неудержимое внедрение программ LLM во всех отраслях, они являются одним из компонентов более широкой технологической экосистемы, которая питает новую волну искусственного интеллекта. Многие сценарии использования диалогового ИИ требуют, чтобы LLM, такие как Llama 2, Flan T5 и Bloom, отвечали на запросы пользователей. Эти модели полагаются на параметрические знания для ответа на вопросы. Модель изучает эти знания во время обучения и кодирует их в параметры модели. Чтобы обновить эти знания, нам необходимо переобучить LLM, что требует много времени и денег.
К счастью, мы также можем использовать исходные знания для информирования наших студентов LLM. Исходные знания — это информация, подаваемая в LLM через подсказку ввода. Одним из популярных подходов к предоставлению исходных знаний является поисковая дополненная генерация (RAG). Используя RAG, мы получаем соответствующую информацию из внешнего источника данных и передаем эту информацию в LLM.
В этом сообщении блога мы рассмотрим, как развертывать LLM, такие как Llama-2, с помощью Amazon Sagemaker JumpStart и поддерживать актуальность наших LLM с помощью соответствующей информации с помощью поисковой дополненной генерации (RAG) с использованием базы данных векторов Pinecone, чтобы предотвратить галлюцинации искусственного интеллекта. .
Поисковая дополненная генерация (RAG) в Amazon SageMaker
Pinecone будет обрабатывать компонент поиска RAG, но вам нужны еще два важных компонента: где-то для запуска вывода LLM и где-то для запуска модели внедрения.
Amazon SageMaker Studio — интегрированная среда разработки (IDE), предоставляющая единый веб-визуальный интерфейс, с помощью которого вы можете получить доступ к специально созданным инструментам для выполнения всех задач машинного обучения (ML). Он предоставляет SageMaker JumpStart, который представляет собой центр моделей, где пользователи могут находить, просматривать и запускать конкретную модель в своей учетной записи SageMaker. Он предоставляет предварительно обученные, общедоступные и собственные модели для широкого спектра типов задач, включая базовые модели.
Amazon SageMaker Studio предоставляет идеальную среду для разработки конвейеров LLM с поддержкой RAG. Сначала с помощью консоли AWS перейдите в Amazon SageMaker, создайте домен SageMaker Studio и откройте блокнот Jupyter Studio.
Предварительные условия
Выполните следующие необходимые шаги:
- Настройте Amazon SageMaker Studio.
- Подключение к домену Amazon SageMaker.
- Подпишитесь на бесплатную базу данных векторов сосновых шишек.
- Необходимые библиотеки: SageMaker Python SDK, клиент Pinecone.
Пошаговое руководство по решению
Используя блокнот SageMaker Studio, нам сначала необходимо установить необходимые библиотеки:
Развертывание LLM
В этом посте мы обсуждаем два подхода к развертыванию LLM. Первый – через HuggingFaceModel объект. Вы можете использовать это при развертывании LLM (и внедрении моделей) непосредственно из концентратора моделей Hugging Face.
Например, вы можете создать развертываемую конфигурацию для гугл/флан-t5-xl модель, как показано на следующем снимке экрана:
При развертывании моделей непосредственно из Hugging Face инициализируйте my_model_configuration со следующим:
- Ан
envconfig сообщает нам, какую модель мы хотим использовать и для какой задачи. - Наше исполнение SageMaker
roleдает нам разрешения на развертывание нашей модели. - Ан
image_uri— это конфигурация образа, специально предназначенная для развертывания LLM из Hugging Face.
Альтернативно, в SageMaker есть набор моделей, напрямую совместимых с более простыми моделями. JumpStartModel объект. Эта модель поддерживает многие популярные LLM, такие как Llama 2, и ее можно инициализировать, как показано на следующем снимке экрана:
Для обеих версий my_modelразверните их, как показано на следующем снимке экрана:
Имея инициализированную конечную точку LLM, вы можете начать выполнение запросов. Формат наших запросов может различаться (особенно между разговорными и недиалоговыми LLM), но процесс в целом один и тот же. Для модели «Обнимающее лицо» выполните следующие действия:
Решение вы можете найти в Репозиторий GitHub.
Сгенерированный ответ, который мы здесь получаем, не имеет особого смысла — это галлюцинация.
Обеспечение дополнительного контекста для LLM
Лама 2 пытается ответить на наш вопрос, основываясь исключительно на внутренних параметрических знаниях. Очевидно, что параметры модели не хранят информацию о том, какие экземпляры мы можем использовать с помощью управляемого выборочного обучения в SageMaker.
Чтобы правильно ответить на этот вопрос, мы должны использовать исходные знания. То есть дополнительную информацию мы даем LLM через подсказку. Давайте добавим эту информацию непосредственно в качестве дополнительного контекста для модели.
Теперь мы видим правильный ответ на вопрос; это было легко! Однако пользователь вряд ли будет вставлять контексты в свои подсказки, он уже будет знать ответ на свой вопрос.
Вместо того, чтобы вручную вставлять один контекст, автоматически идентифицируйте соответствующую информацию из более обширной базы данных. Для этого вам понадобится поисковая дополненная генерация.
Поисковая расширенная генерация
С помощью поисковой расширенной генерации вы можете кодировать базу данных с информацией в векторное пространство, где близость между векторами представляет их релевантность/семантическое сходство. Используя это векторное пространство в качестве базы знаний, вы можете преобразовать новый пользовательский запрос, закодировать его в то же векторное пространство и получить наиболее релевантные ранее проиндексированные записи.
После получения этих соответствующих записей выберите несколько из них и включите их в приглашение LLM в качестве дополнительного контекста, предоставив LLM весьма актуальные исходные знания. Это двухэтапный процесс, в котором:
- Индексирование заполняет векторный индекс информацией из набора данных.
- Извлечение происходит во время запроса, и именно здесь мы извлекаем соответствующую информацию из векторного индекса.
Оба шага требуют модели внедрения для перевода нашего удобочитаемого простого текста в семантическое векторное пространство. Используйте высокоэффективный преобразователь предложений MiniLM от Hugging Face, как показано на следующем снимке экрана. Эта модель не является LLM и поэтому не инициализируется так же, как наша модель Llama 2.
в hub_config, укажите идентификатор модели, как показано на снимке экрана выше, но для этой задачи используйте извлечение признаков, поскольку мы генерируем векторные внедрения, а не текст, как наш LLM. После этого инициализируйте конфигурацию модели с помощью HuggingFaceModel как и раньше, но на этот раз без образа LLM и с некоторыми параметрами версии.
Вы можете снова развернуть модель с помощью deployиспользуя меньший (только для процессора) экземпляр ml.t2.large. Модель MiniLM крошечная, поэтому ей не требуется много памяти и графический процессор, поскольку она может быстро создавать встраивания даже на центральном процессоре. При желании вы можете запустить модель быстрее на графическом процессоре.
Для создания вложений используйте predict и передать список контекстов для кодирования через метод inputs ключ, как показано:
Передаются два входных контекста, возвращающие два вектора контекста, как показано:
len(out)
2
Размерность вложения модели MiniLM равна 384 что означает, что каждый вектор, встраивающий выходные данные MiniLM, должен иметь размерность 384. Однако, посмотрев на длину наших вложений, вы увидите следующее:
len(out(0)), len(out(1))
(8, 8)
Два списка содержат по восемь пунктов каждый. MiniLM сначала обрабатывает текст на этапе токенизации. Эта токенизация преобразует наш удобочитаемый простой текст в список идентификаторов токенов, читаемых моделью. В выходных функциях модели вы можете увидеть внедрения на уровне токена. одно из этих вложений показывает ожидаемую размерность 384 как показано:
len(out(0)(0))
384
Преобразуйте эти внедрения на уровне токена во внедрения на уровне документа, используя средние значения для каждого векторного измерения, как показано на следующем рисунке.
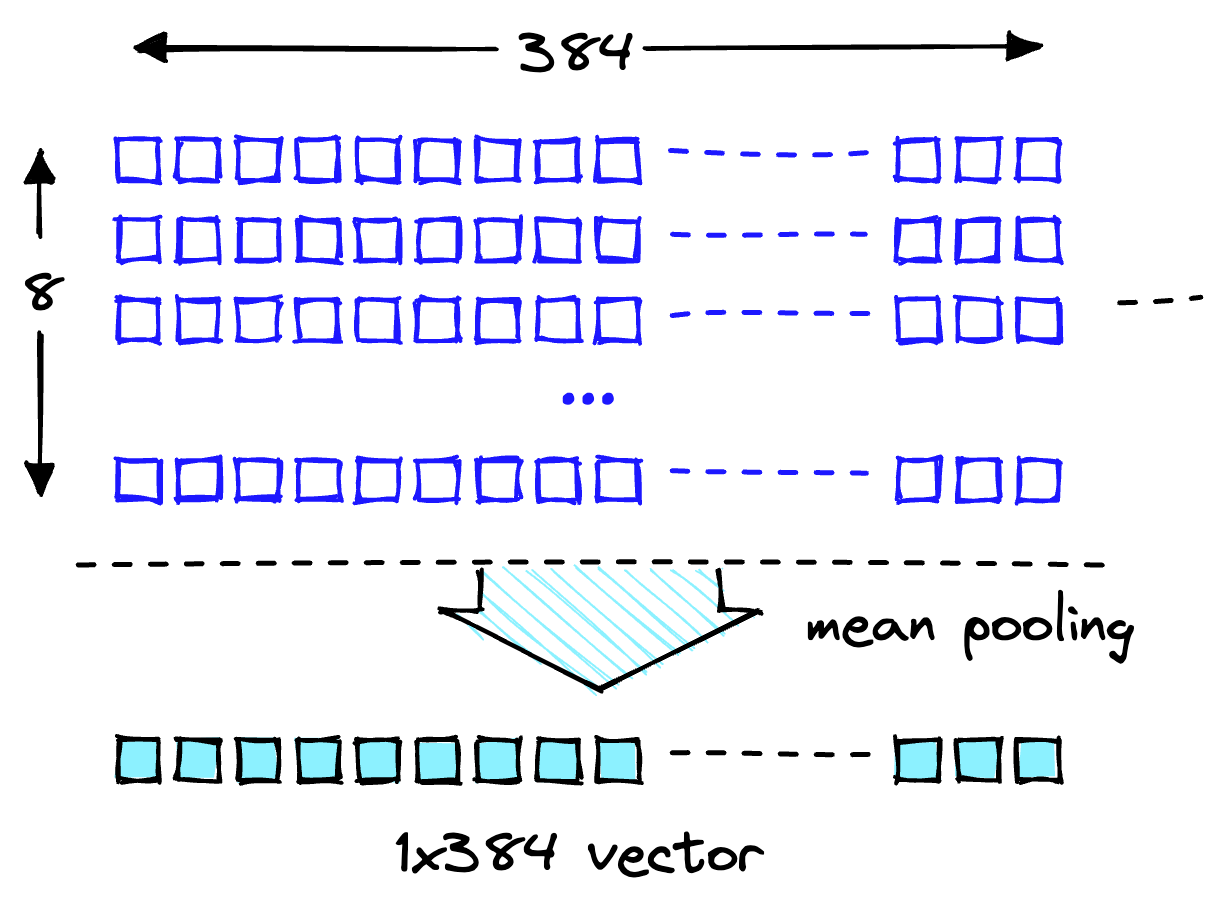
Операция среднего объединения для получения одного 384-мерного вектора.
С двумя 384-мерными векторными вложениями, по одному на каждый входной текст. Чтобы облегчить нам жизнь, оберните процесс кодирования в одну функцию, как показано на следующем снимке экрана:
Загрузка набора данных
Загрузите часто задаваемые вопросы по Amazon SageMaker в качестве базы знаний, чтобы получить данные, содержащие столбцы с вопросами и ответами.
Загрузите часто задаваемые вопросы по Amazon SageMaker
При выполнении поиска ищите только ответы, чтобы можно было удалить столбец «Вопрос». Подробности смотрите в блокноте.
Наш набор данных и конвейер для внедрения готовы. Теперь все, что нам нужно, это где-то хранить эти вложения.
Индексирование
База данных векторов Pinecone хранит векторные вложения и эффективно выполняет их поиск в любом масштабе. Для создания базы данных вам понадобится бесплатный ключ API от Pinecone.
После подключения к векторной базе данных «Сосновая шишка» создайте единый векторный индекс (аналог таблицы в традиционных БД). Назовите индекс retrieval-augmentation-aws и выровнять индекс dimension и metric параметры с теми, которые требуются для модели внедрения (в данном случае MiniLM).
Чтобы начать вставку данных, выполните следующую команду:
Вы можете начать запрос индекса с вопроса, заданного ранее в этой статье.
Вывод выше показывает, что мы возвращаем соответствующие контексты, которые помогут нам ответить на наш вопрос. С тех пор, как мы top_k = 1, index.query вернул верхний результат вместе с метаданными, которые читают Managed Spot Training can be used with all instances supported in Amazon.
Дополнение подсказки
Используйте полученные контексты, чтобы дополнить подсказку и определить максимальный объем контекста для подачи в LLM. Использовать 1000 количество символов ограничено, чтобы итеративно добавлять каждый возвращаемый контекст в приглашение, пока вы не превысите длину содержимого.
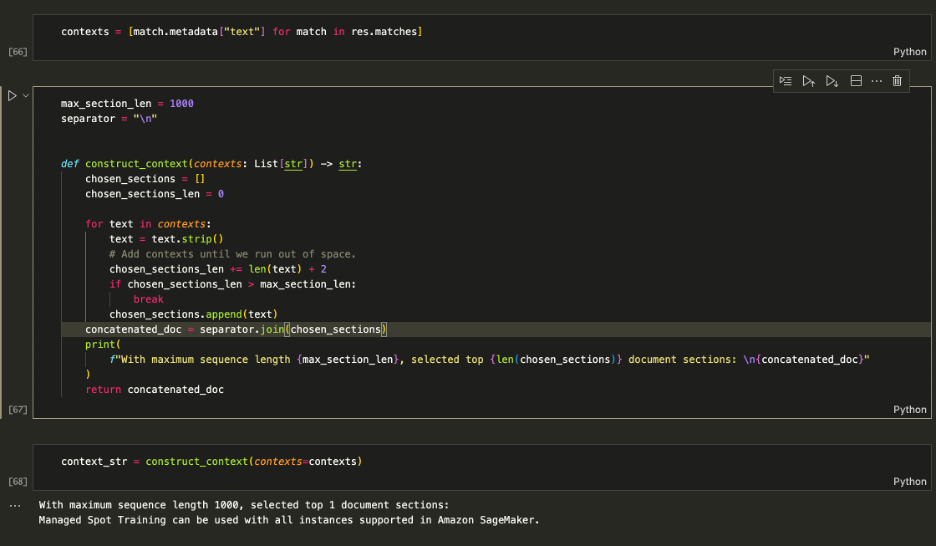
Дополнение подсказки
Накормить context_str в приглашение LLM, как показано на следующем снимке экрана:
(Input): Which instances can I use with Managed Spot Training in SageMaker? (Output): Based on the context provided, you can use Managed Spot Training with all instances supported in Amazon SageMaker. Therefore, the answer is: All instances supported in Amazon SageMaker.
Логика работает, поэтому оберните ее в одну функцию, чтобы все было чисто.
Теперь вы можете задавать вопросы, подобные показанным ниже:
Очистить
Чтобы избежать нежелательных расходов, удалите модель и конечную точку.
Заключение
В этом посте мы познакомили вас с RAG и LLM с открытым доступом на SageMaker. Мы также показали, как развертывать модели Amazon SageMaker Jumpstart с помощью Llama 2, LLM Hugging Face с помощью Flan T5 и встраивать модели с помощью MiniLM.
Мы реализовали полный комплексный конвейер RAG, используя наши модели открытого доступа и векторный индекс сосновой шишки. Используя это, мы показали, как свести к минимуму галлюцинации, поддерживать знания LLM в актуальном состоянии и, в конечном итоге, повысить удобство работы пользователей и повысить доверие к нашим системам.
Чтобы запустить этот пример самостоятельно, клонируйте этот репозиторий GitHub и выполните предыдущие шаги, используя Блокнот для ответов на вопросы на GitHub.
Об авторах
 Ведант-джайн — старший специалист по искусственному интеллекту и машинному обучению, работающий над стратегическими инициативами в области генеративного искусственного интеллекта. До прихода в AWS Ведант занимал должности специалиста по ML/Data Science в различных компаниях, таких как Databricks, Hortonworks (теперь Cloudera) и JP Morgan Chase. Помимо своей работы, Ведант увлекается созданием музыки, скалолазанием, использованием науки для полноценной жизни и изучением кухонь всего мира.
Ведант-джайн — старший специалист по искусственному интеллекту и машинному обучению, работающий над стратегическими инициативами в области генеративного искусственного интеллекта. До прихода в AWS Ведант занимал должности специалиста по ML/Data Science в различных компаниях, таких как Databricks, Hortonworks (теперь Cloudera) и JP Morgan Chase. Помимо своей работы, Ведант увлекается созданием музыки, скалолазанием, использованием науки для полноценной жизни и изучением кухонь всего мира.
 Джеймс Бриггс — штатный юрист-разработчик в компании Pinecone, специализирующийся на векторном поиске и искусственном интеллекте и машинном обучении. Он помогает разработчикам и предприятиям разрабатывать собственные решения GenAI посредством онлайн-обучения. До прихода в Pinecone Джеймс работал над искусственным интеллектом для небольших технологических стартапов и крупных финансовых корпораций. Помимо работы, Джеймс любит путешествовать и искать новые приключения, от серфинга и подводного плавания до тайского бокса и BJJ.
Джеймс Бриггс — штатный юрист-разработчик в компании Pinecone, специализирующийся на векторном поиске и искусственном интеллекте и машинном обучении. Он помогает разработчикам и предприятиям разрабатывать собственные решения GenAI посредством онлайн-обучения. До прихода в Pinecone Джеймс работал над искусственным интеллектом для небольших технологических стартапов и крупных финансовых корпораций. Помимо работы, Джеймс любит путешествовать и искать новые приключения, от серфинга и подводного плавания до тайского бокса и BJJ.
 Синь Хуан — старший научный сотрудник Amazon SageMaker JumpStart и встроенных алгоритмов Amazon SageMaker. Он занимается разработкой масштабируемых алгоритмов машинного обучения. Его исследовательские интересы лежат в области обработки естественного языка, объяснимого глубокого обучения табличных данных и надежного анализа непараметрической пространственно-временной кластеризации. Он опубликовал множество статей на конференциях ACL, ICDM, KDD и Королевском статистическом обществе: серия A.
Синь Хуан — старший научный сотрудник Amazon SageMaker JumpStart и встроенных алгоритмов Amazon SageMaker. Он занимается разработкой масштабируемых алгоритмов машинного обучения. Его исследовательские интересы лежат в области обработки естественного языка, объяснимого глубокого обучения табличных данных и надежного анализа непараметрической пространственно-временной кластеризации. Он опубликовал множество статей на конференциях ACL, ICDM, KDD и Королевском статистическом обществе: серия A.