
Сегодня генеративные модели ИИ решают самые разные задачи: от обобщения текста, вопросов и ответов до создания изображений и видео. Для улучшения качества вывода используются такие подходы, как n-короткое обучение, оперативное проектирование, поисковая дополненная генерация (RAG) и точная настройка. Точная настройка позволяет вам настроить эти генеративные модели ИИ для повышения производительности при выполнении задач, специфичных для вашей предметной области.
Благодаря Amazon SageMaker теперь вы можете запустить задание обучения SageMaker, просто аннотируя свой код Python с помощью декоратора @remote. SageMaker Python SDK автоматически преобразует существующую рабочую среду и любой связанный с ней код обработки данных и наборы данных в задание обучения SageMaker, которое выполняется на платформе обучения. Преимущество этого подхода состоит в том, что код пишется более естественным, объектно-ориентированным способом, и при этом по-прежнему используются возможности SageMaker для запуска обучающих заданий в удаленном кластере с минимальными изменениями.
В этой статье мы покажем, как настроить Сокол-7Б Базовые модели (FM) с использованием декоратора @remote из SageMaker Python SDK. Он также использует Точная настройка параметров Hugging Face (PEFT) и методы квантования с помощью биты и байты для поддержки тонкой настройки. Код, представленный в этом блоге, также можно использовать для тонкой настройки других FM, таких как Лама-2 13б.
Полноточные представления этой модели могут с трудом уместиться в памяти на одном или даже нескольких Графические процессоры (GPU) — или, возможно, даже понадобится экземпляр большего размера. Следовательно, чтобы точно настроить эту модель без увеличения затрат, мы используем метод, известный как Квантованные LLM с адаптерами низкого ранга (QLoRA). QLoRA — это эффективный подход к тонкой настройке, который снижает использование памяти LLM, сохраняя при этом очень хорошую производительность.
Преимущества использования декоратора @remote
Прежде чем идти дальше, давайте разберемся, как удаленный декоратор повышает производительность разработчиков при работе с SageMaker:
- Декоратор @remote запускает задание обучения напрямую, используя собственный код Python, без явного вызова оценщиков SageMaker и входных каналов SageMaker.
- Низкий барьер для входа в модели обучения разработчиков на SageMaker.
- Нет необходимости переключаться Интегрированные среды разработки (IDE). Продолжайте писать код в выбранной вами IDE и запускайте учебные задания SageMaker.
- Нет необходимости изучать контейнеры. Продолжайте предоставлять зависимости в
requirements.txtи передайте это удаленному декоратору.
Предварительные условия
Требуется учетная запись AWS с ролью AWS Identity and Access Management (AWS IAM), которая имеет разрешения на управление ресурсами, созданными в рамках решения. Подробную информацию см. в разделе Создание учетной записи AWS.
В этом посте мы используем Amazon SageMaker Studio с Data Science 3.0 изображение и ml.t3.medium экземпляр быстрого запуска. Однако вы можете использовать любую интегрированную среду разработки (IDE) по вашему выбору. Вам просто нужно правильно настроить учетные данные интерфейса командной строки AWS (AWS CLI). Дополнительную информацию см. в разделе Настройка интерфейса командной строки AWS.
Для доводки Falcon-7B, ml.g5.12xlarge экземпляр используется в этом посте. Убедитесь, что в аккаунте AWS достаточно места для этого экземпляра.
Вам нужно клонировать это Репозиторий на Гитхабе для репликации решения, продемонстрированного в этом посте.
Обзор решения
- Установите необходимые условия для тонкой настройки модели Falcon-7B.
- Настройка конфигураций удаленного декоратора
- Предварительная обработка набора данных, содержащего часто задаваемые вопросы по сервисам AWS
- Тонкая настройка Falcon-7B на сервисах AWS: часто задаваемые вопросы
- Протестируйте модели точной настройки, ответив на примеры вопросов, связанных с сервисами AWS.
1. Установить необходимые условия для тонкой настройки модели Falcon-7B.
Запустите блокнот falcon-7b-qlora-remote-decorator_qa.ipynb в SageMaker Studio, выбрав Iмаг как Data Science и Ядро как Python 3. Установите все необходимые библиотеки, упомянутые в requirements.txt. Некоторые библиотеки необходимо устанавливать на самом экземпляре ноутбука. Выполните другие операции, необходимые для обработки набора данных и запуска задания обучения SageMaker.
2. Настройка конфигураций удаленного декоратора
Создайте файл конфигурации, в котором указаны все конфигурации, связанные с заданием обучения Amazon SageMaker. Этот файл читается декоратором @remote во время выполнения задания обучения. Этот файл содержит такие настройки, как зависимости, обучающий образ, экземпляр и роль выполнения, которая будет использоваться для учебного задания. Подробную информацию обо всех настройках, поддерживаемых файлом конфигурации, см. Настройка и использование значений по умолчанию с помощью SageMaker Python SDK.
Не обязательно использовать config.yaml файл для работы с декоратором @remote. Это просто более простой способ передать все конфигурации декоратору @remote. Благодаря этому параметры, связанные с SageMaker и AWS, остаются вне кода, позволяя единовременно настроить файл конфигурации, используемый всеми членами команды. Все конфигурации также можно было бы указать непосредственно в аргументах декоратора, но это снижает читаемость и удобство сопровождения изменений в долгосрочной перспективе. Кроме того, файл конфигурации может быть создан администратором и доступен всем пользователям в среде.
Предварительная обработка набора данных, содержащего часто задаваемые вопросы по сервисам AWS
Следующим шагом является загрузка и предварительная обработка набора данных, чтобы подготовить его к обучению. Сначала давайте посмотрим на набор данных:
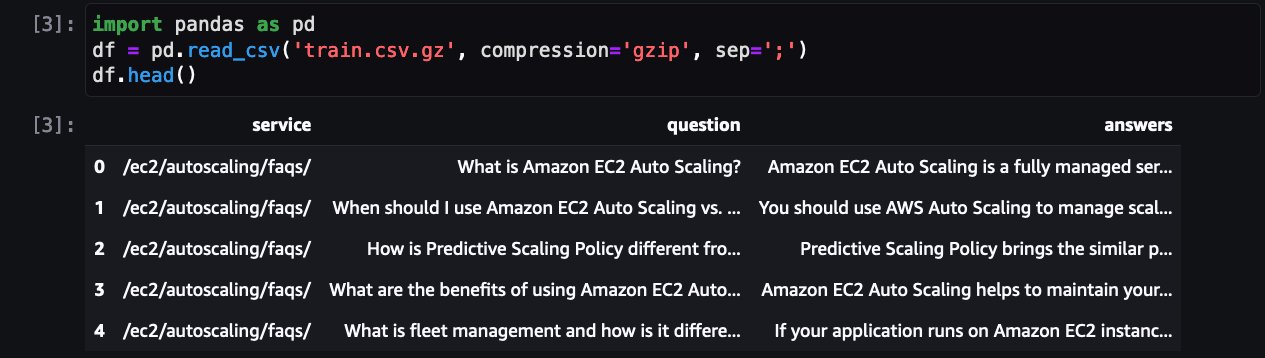
Здесь показаны часто задаваемые вопросы для одного из сервисов AWS. Помимо QLoRA, bitsanbytes используется для преобразования в 4-битную точность для квантования замороженного LLM в 4-битный и присоединения ЛоРА адаптеры на нем.
Создайте шаблон подсказки, чтобы преобразовать каждый образец часто задаваемых вопросов в формат подсказки:
Следующим шагом является преобразование входных данных (текста) в идентификаторы токенов. Это делается с помощью Токенизатор Трансформеров Обнимающего Лица.
Теперь просто используйте prompt_template функция для преобразования всех часто задаваемых вопросов в формат подсказок и настройки наборов обучающих и тестовых данных.

4. Точная настройка Falcon-7B на сервисах AWS. Часто задаваемые вопросы
Теперь вы можете подготовить сценарий обучения и определить функцию обучения. train_fn и поместите декоратор @remote в функцию.
Функция обучения выполняет следующие действия:
- токенизирует и разбивает набор данных
- настраивать
BitsAndBytesConfigкоторый указывает, что модель должна быть загружена в 4-битном формате, но при этом вычисления должны быть преобразованы вbfloat16. - Загрузите модель
- Найдите целевые модули и обновите необходимые матрицы с помощью служебного метода.
find_all_linear_names - Создавать ЛоРА конфигурации, которые определяют ранжирование матриц обновления (
s), коэффициент масштабирования (lora_alpha), модули для применения матриц обновления LoRA (target_modules), вероятность выпадения слоев Лоры(lora_dropout),task_typeи т. д. - Начните обучение и оценку
И вызвать train_fn()
Задание по настройке будет выполняться в обучающем кластере Amazon SageMaker. Подождите, пока работа по настройке завершится.
5. Проверьте модели точной настройки на примерах вопросов, связанных с сервисами AWS.
Теперь пришло время провести несколько тестов модели. Сначала загрузим модель:
Теперь загрузите образец вопроса из набора обучающих данных, чтобы увидеть исходный ответ, а затем задайте тот же вопрос из настроенной модели, чтобы увидеть ответ в сравнении.
Вот пример вопроса из обучающего набора и оригинальный ответ:
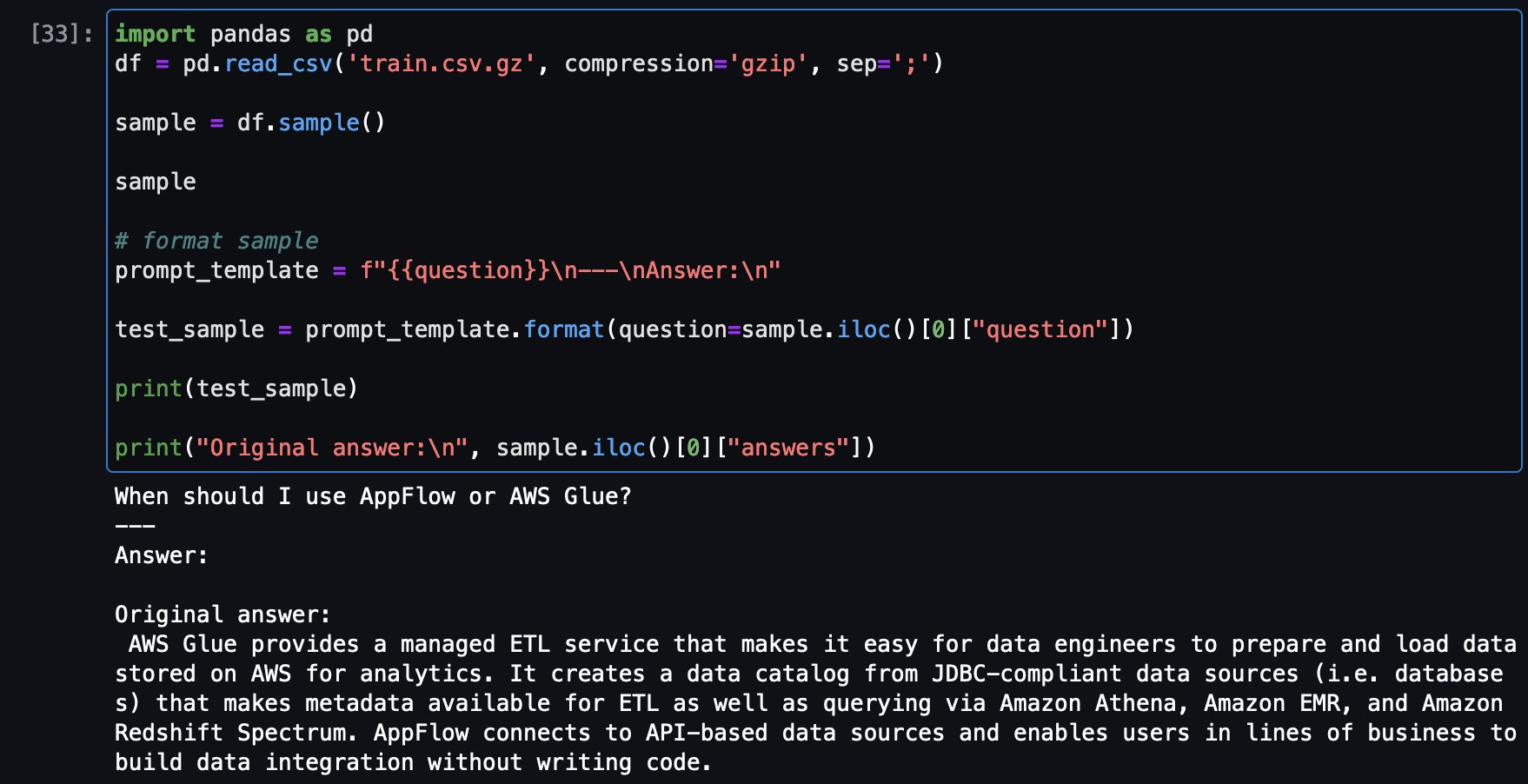
Теперь тот же вопрос задается и по поводу настроенной модели Falcon-7B:
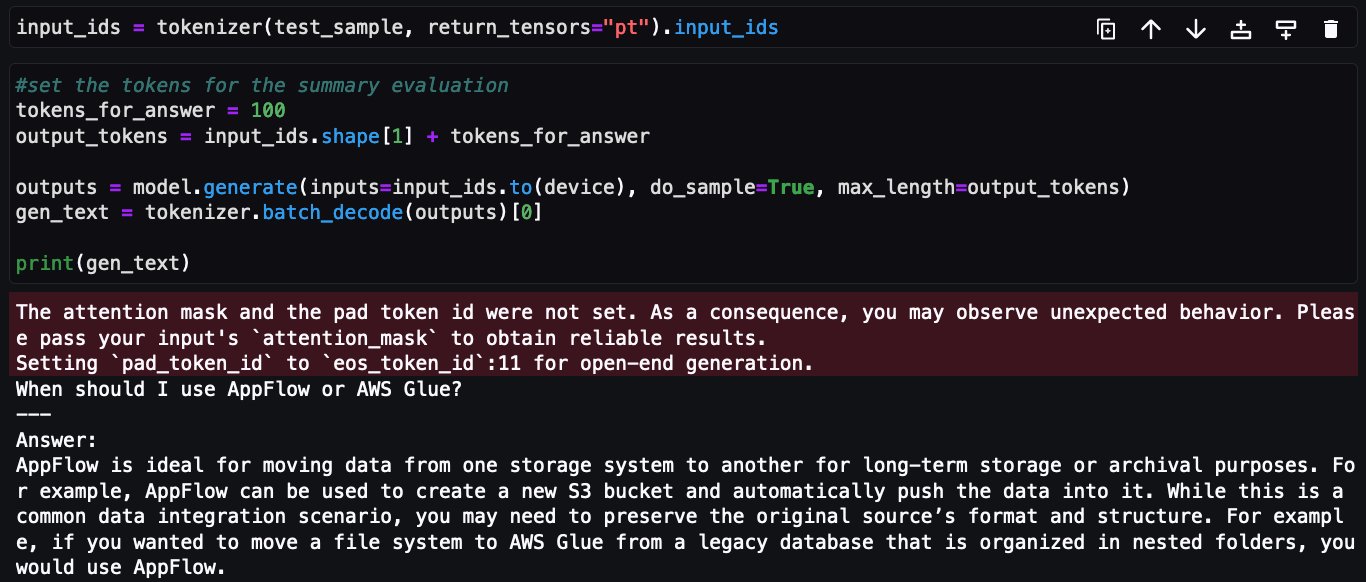
На этом завершается реализация тонкой настройки Falcon-7B в наборе часто задаваемых вопросов по сервисам AWS с использованием декоратора @remote из Amazon SageMaker Python SDK.
Убираться
Выполните следующие шаги, чтобы очистить ресурсы:
- Завершите работу экземпляров Amazon SageMaker Studio, чтобы избежать дополнительных затрат.
- Очистите каталог Amazon Elastic File System (Amazon EFS), очистив каталог кэша Hugging Face:
Заключение
В этом посте мы показали вам, как эффективно использовать возможности декоратора @remote для точной настройки модели Falcon-7B с использованием QLoRA, Hugging Face PEFT с bitsandbtyes без внесения существенных изменений в учебный блокнот и использовал возможности Amazon SageMaker для запуска обучающих заданий в удаленном кластере.
Весь код, показанный в этом посте для точной настройки Falcon-7B, доступен в Репозиторий GitHub. В репозитории также есть блокнот, показывающий, как точно настроить Llama-13B.
В качестве следующего шага мы рекомендуем вам ознакомиться с функциональностью декоратора @remote и API Python SDK и используйте его в выбранной вами среде и IDE. Дополнительные примеры доступны в разделе amazon-sagemaker-примеры репозиторий, чтобы вы могли быстро начать работу. Вы также можете просмотреть следующие публикации:
Об авторах
 Бруно Пистоне — специалист по архитектуре решений AI/ML в AWS, базирующийся в Милане. Он работает с крупными клиентами, помогая им глубоко понять их технические потребности и разрабатывать решения в области искусственного интеллекта и машинного обучения, которые максимально эффективно используют облако AWS и стек машинного обучения Amazon. Его опыт включает комплексное машинное обучение, индустриализацию машинного обучения и генеративный искусственный интеллект. Ему нравится проводить время со своими друзьями и исследовать новые места, а также путешествовать по новым направлениям.
Бруно Пистоне — специалист по архитектуре решений AI/ML в AWS, базирующийся в Милане. Он работает с крупными клиентами, помогая им глубоко понять их технические потребности и разрабатывать решения в области искусственного интеллекта и машинного обучения, которые максимально эффективно используют облако AWS и стек машинного обучения Amazon. Его опыт включает комплексное машинное обучение, индустриализацию машинного обучения и генеративный искусственный интеллект. Ему нравится проводить время со своими друзьями и исследовать новые места, а также путешествовать по новым направлениям.
 Викеш Пандей — специалист по архитектуре решений в области машинного обучения в AWS, помогающий клиентам из финансовой отрасли разрабатывать и создавать решения на основе генеративного искусственного интеллекта и машинного обучения. Помимо работы Викеш любит пробовать разные кухни и заниматься спортом на свежем воздухе.
Викеш Пандей — специалист по архитектуре решений в области машинного обучения в AWS, помогающий клиентам из финансовой отрасли разрабатывать и создавать решения на основе генеративного искусственного интеллекта и машинного обучения. Помимо работы Викеш любит пробовать разные кухни и заниматься спортом на свежем воздухе.