

Сегодняшние роботы часто статичны и изолированы от людей в структурированных средах — вы можете вспомнить роботов-манипуляторов, используемых Amazon для сбора и упаковки товаров на складах. Но истинный потенциал робототехники заключается в том, что мобильные роботы работают вместе с людьми в грязных условиях, таких как наши дома и больницы — для этого требуются навыки навигации.
Представьте, что вы бросаете робота в совершенно невидимый дом и просите его найти предмет, скажем, туалет. Люди могут сделать это без особых усилий: когда мы ищем стакан воды в доме друга, который мы посещаем впервые, мы можем легко найти кухню, не заходя в спальни или кладовые. Но научить роботов такому пространственному здравому смыслу сложно.
Для решения этой проблемы было предложено множество политик визуальной навигации, основанных на обучении. Но выученные правила визуальной навигации в основном оценивались в моделировании. Насколько хорошо разные классы методов работают на роботе?
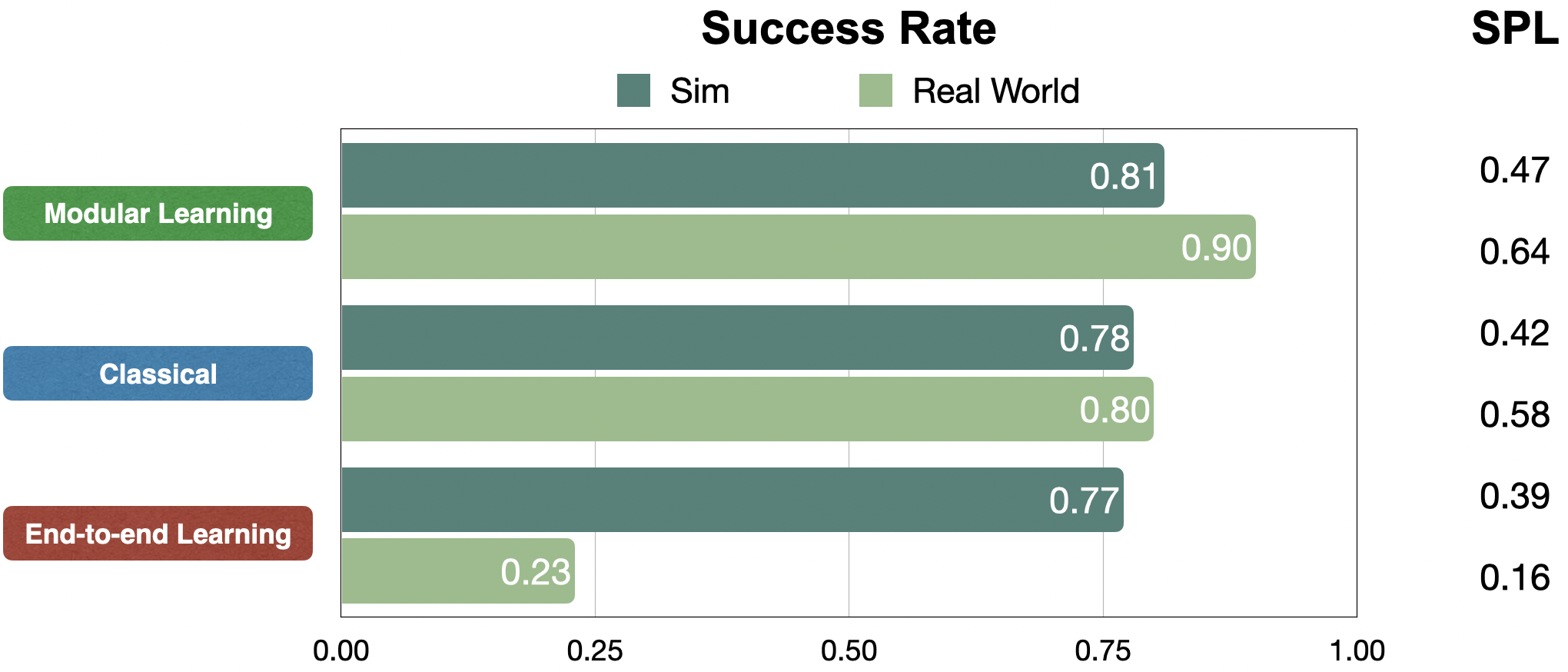
Мы представляем крупномасштабное эмпирическое исследование методов семантической визуальной навигации, сравнивая репрезентативные методы классических, модульных и сквозных подходов к обучению в шести домах без предварительного опыта, карт или инструментов. Мы обнаружили, что модульное обучение хорошо работает в реальном мире, достигая 90% успеха. Напротив, в сквозном обучении этого не происходит, поскольку показатель успеха снижается с 77% симуляции до 23% в реальном мире из-за большого разрыва между областью изображения между симуляцией и реальностью.
Навигация по цели объекта
Мы реализуем семантическую навигацию с помощью задачи навигации «Цель объекта», где робот начинает работу в совершенно невидимой среде, и его просят найти экземпляр категории объектов, скажем, туалет. Робот имеет доступ только к камере RGB и глубины от первого лица и датчику позы.
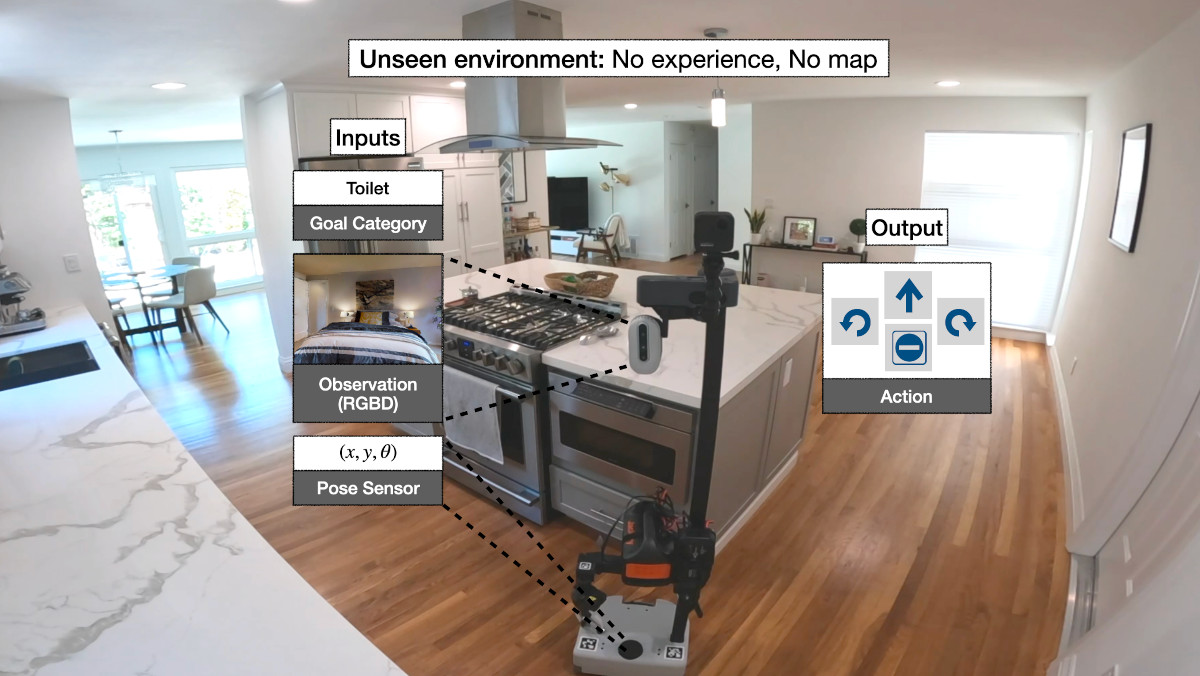
Эта задача является сложной. Это требует не только понимания пространственной сцены для различения свободного пространства и препятствий и понимания семантической сцены для обнаружения объектов, но также требует изучения априорных семантических исследований. Например, если человек хочет найти туалет в этой сцене, большинство из нас выберет коридор, потому что он, скорее всего, приведет к туалету. Обучение такого рода здравому смыслу или семантическим априорным данным автономного агента является сложной задачей. Исследуя сцену в поисках нужного объекта, робот также должен запоминать исследованные и неизведанные области.

Методы
Так как же нам обучить автономных агентов, способных эффективно ориентироваться, решая все эти проблемы? Классический подход к этой проблеме строит геометрическую карту с использованием датчиков глубины, исследует окружающую среду с помощью эвристики, такой как исследование границы, которая исследует ближайшую неизведанную область, и использует аналитический планировщик для достижения целей исследования и целевого объекта, как только он появится. понимание. Подход сквозного обучения предсказывает действия непосредственно на основе необработанных наблюдений с помощью глубокой нейронной сети, состоящей из визуальных кодировщиков для кадров изображения, за которыми следует рекуррентный слой для памяти. Модульный подход к обучению строит семантическую карту путем проецирования прогнозируемой семантической сегментации с использованием глубины, прогнозирует цель исследования с помощью целенаправленной семантической политики в зависимости от семантической карты и целевого объекта и достигает ее с помощью планировщика.
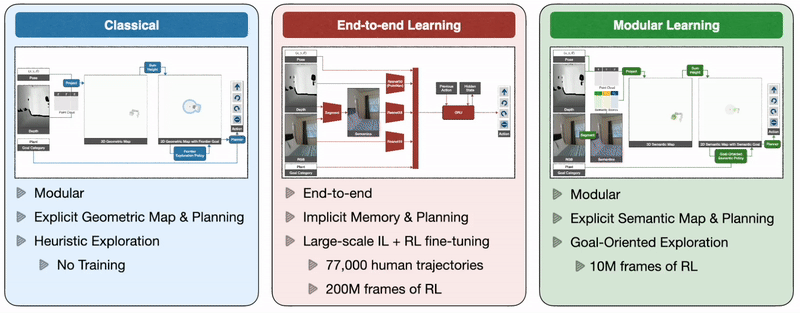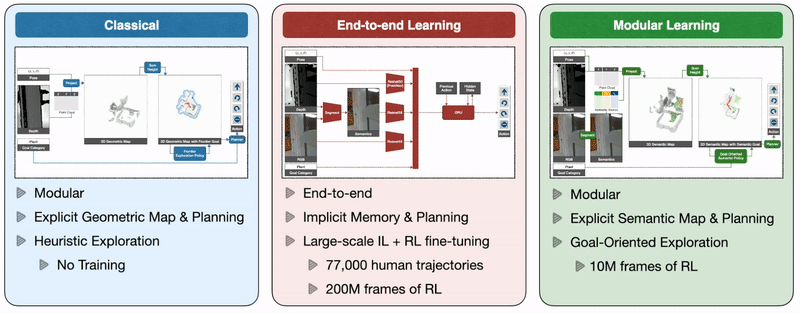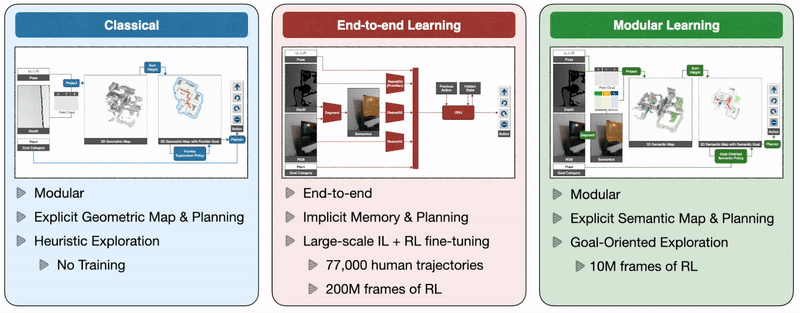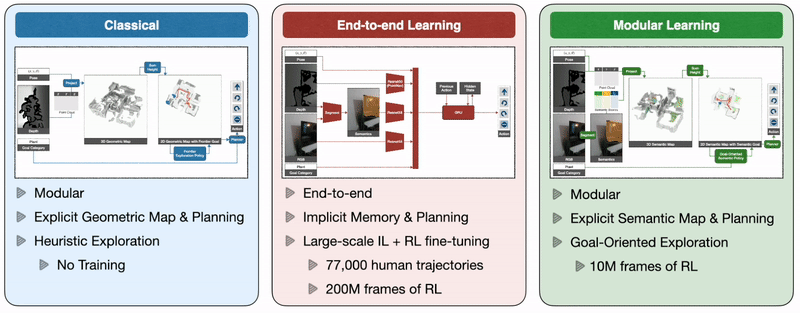
Крупномасштабная эмпирическая оценка в реальном мире
Хотя за последние несколько лет было предложено множество подходов к навигации по объектам, усвоенные правила навигации в основном оценивались в моделировании, что открывает поле для риска исследований только на симуляторах, которые не обобщаются на реальный мир. Мы решаем эту проблему посредством широкомасштабной эмпирической оценки репрезентативных классических, сквозных и модульных подходов к обучению в 6 невидимых домах и 6 категориях целевых объектов.

Полученные результаты
Мы сравниваем подходы с точки зрения показателя успеха в рамках ограниченного бюджета в 200 действий робота и успеха, взвешенного по длине пути (SPL), показателю эффективности пути. В моделировании все подходы работают примерно с вероятностью успеха около 80%. Но в реальном мире модульное обучение и классические подходы очень хорошо переносятся: показатели успеха выросли с 81% до 90% и с 78% до 80% соответственно. Несмотря на то, что сквозное обучение не переносится, показатель успеха снизился с 77% до 23%.
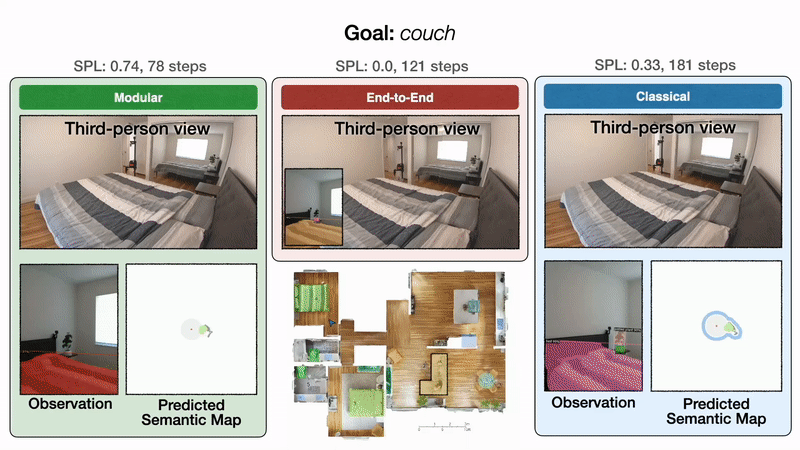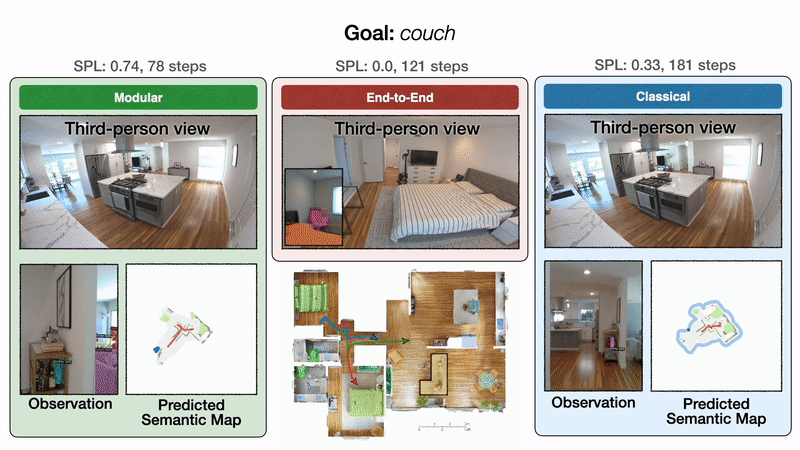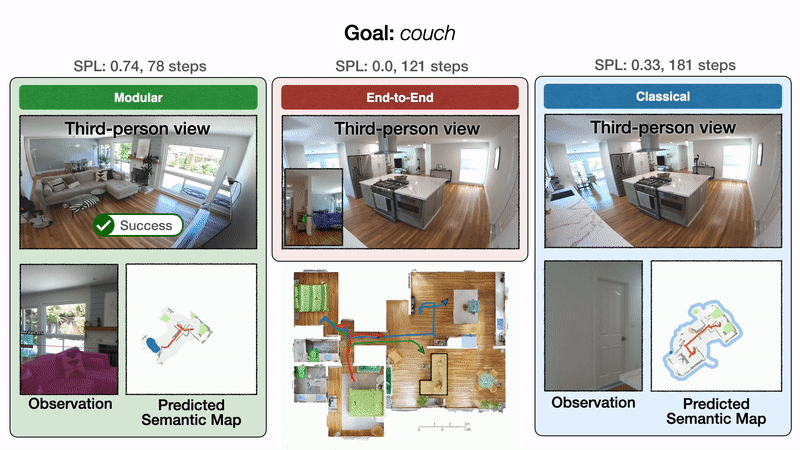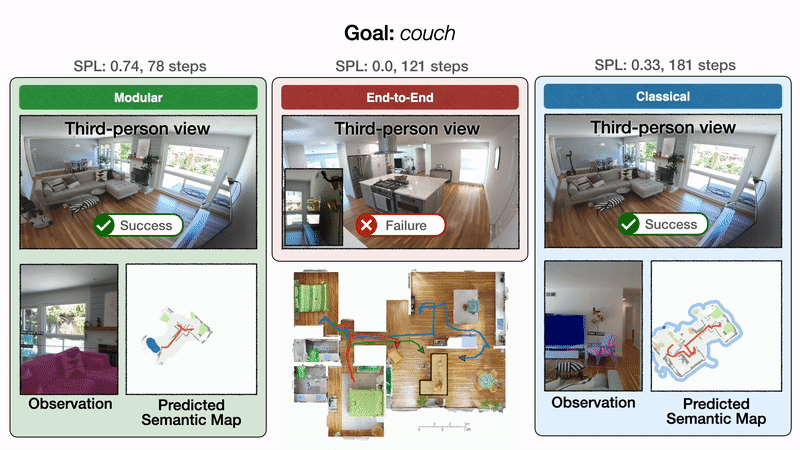
Мы проиллюстрируем эти результаты качественно одной репрезентативной траекторией. Все подходы начинаются в спальне и направлены на поиск дивана. Слева модульное обучение сначала успешно достигает цели дивана. В середине сквозное обучение терпит неудачу после слишком большого количества столкновений. Справа классическая политика, наконец, достигает цели дивана после обхода кухни.
Результат 1: модульное обучение надежно
Мы обнаружили, что модульное обучение очень надежно на роботе с вероятностью успеха 90%. Здесь мы видим, как он эффективно находит растение в первом доме, стул во втором доме и туалет в третьем.

Результат 2: модульное обучение исследует эффективнее, чем классическое
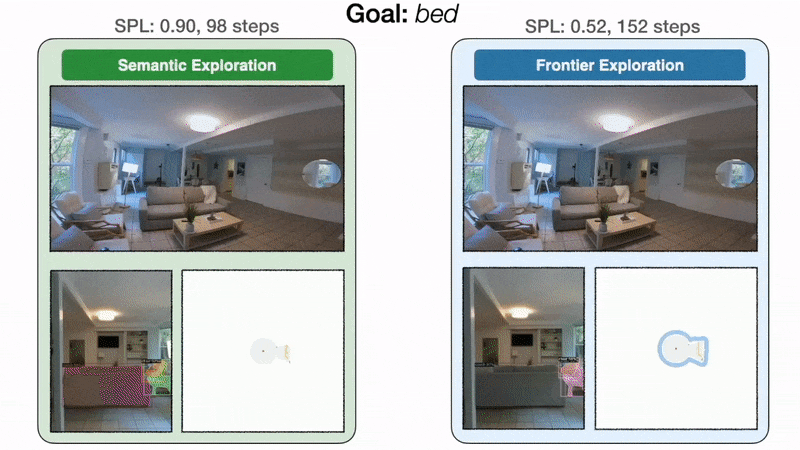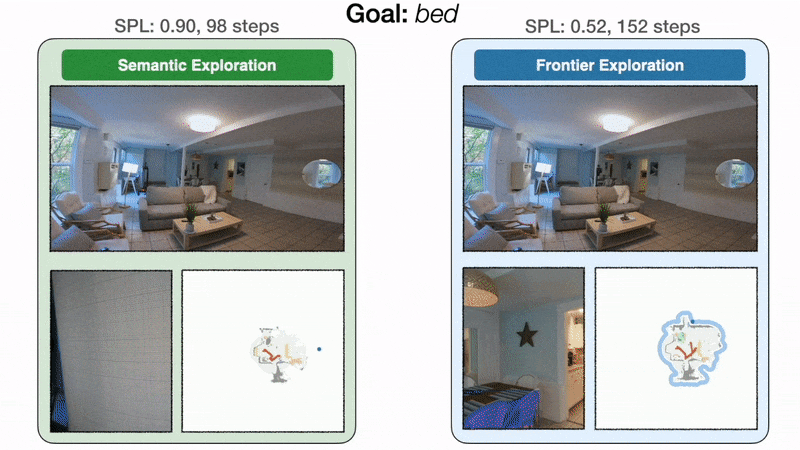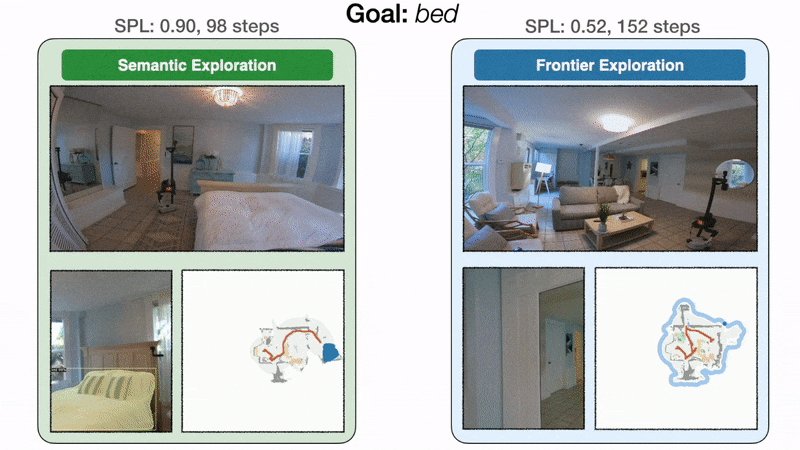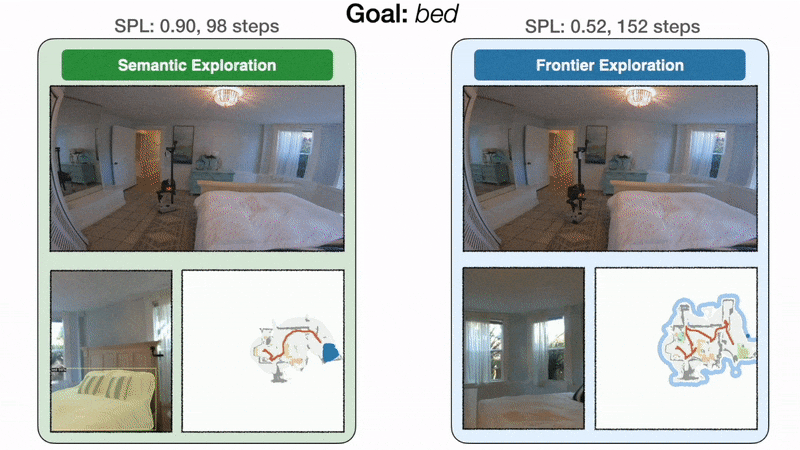
Модульное обучение на 10 % повышает реальный уровень успеха по сравнению с классическим подходом. Слева политика целенаправленного семантического исследования направляется непосредственно к спальне и находит кровать за 98 шагов с уровнем звукового давления 0,90. Справа, поскольку исследование границы не зависит от цели кровати, политика делает обход через кухню и прихожую, прежде чем, наконец, достичь кровати за 152 шага с SPL 0,52. При ограниченном бюджете времени неэффективное исследование может привести к неудаче.
Результат 3: сквозное обучение не переносится
В то время как классические и модульные подходы к обучению хорошо работают на роботе, сквозное обучение не работает с коэффициентом успеха всего 23%. Политика часто сталкивается, повторно посещает одни и те же места и даже не останавливается перед целевыми объектами, когда они находятся в поле зрения.

Анализ
Вывод 1: почему модульная передача работает, а сквозная нет?
Почему модульное обучение так хорошо переносится, а сквозное обучение — нет? Чтобы ответить на этот вопрос, мы реконструировали один реальный дом в симуляции и провели эксперименты с идентичными эпизодами в симуляции и реальности.

Политика семантического исследования модульного подхода к обучению использует семантическую карту в качестве входных данных, в то время как сквозная политика напрямую работает с кадрами RGB-D. Пространство семантической карты инвариантно между симом и реальностью, в то время как пространство изображения демонстрирует большой разрыв домена. В этом примере этот пробел приводит к модели сегментации, обученной на изображениях реального мира, чтобы предсказать ложное срабатывание кровати на кухне.
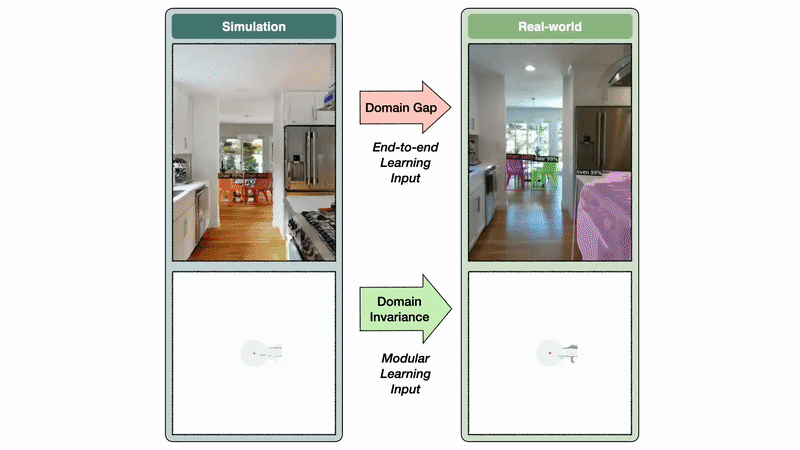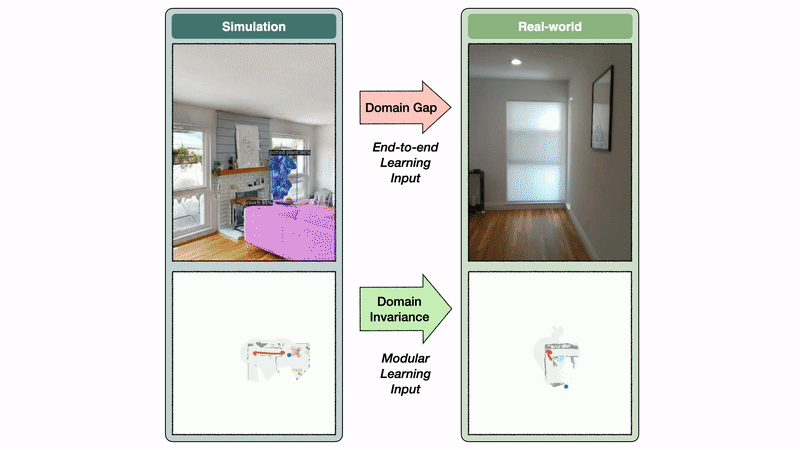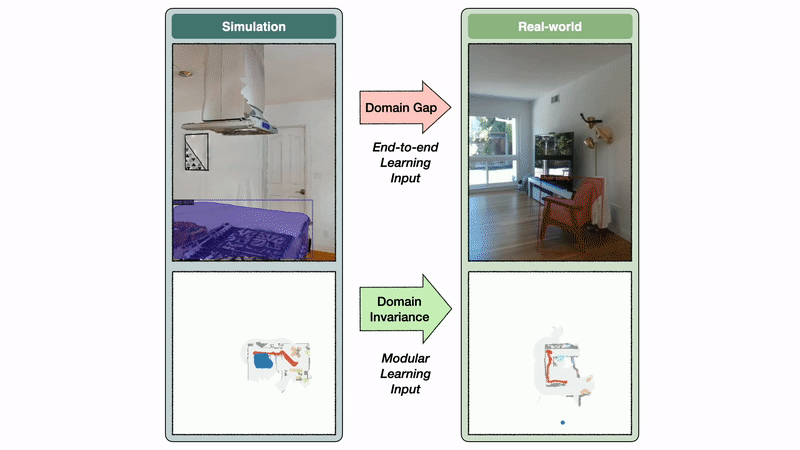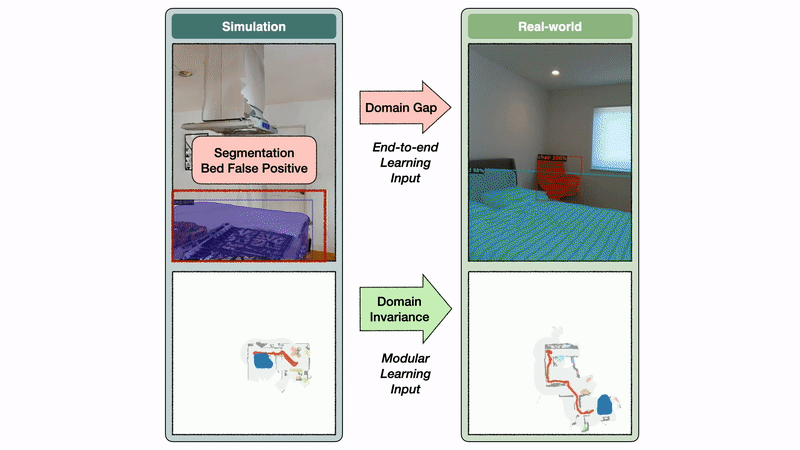
Инвариантность домена семантической карты позволяет модульному подходу к обучению хорошо переноситься из симуляции в реальность. Напротив, разрыв домена изображения вызывает значительное падение производительности при переносе модели сегментации, обученной в реальном мире, в симуляцию и наоборот. Если семантическая сегментация плохо переносится из симуляции в реальность, разумно ожидать, что политика сквозной семантической навигации, обученная на сим-изображениях, будет плохо переноситься в изображения реального мира.
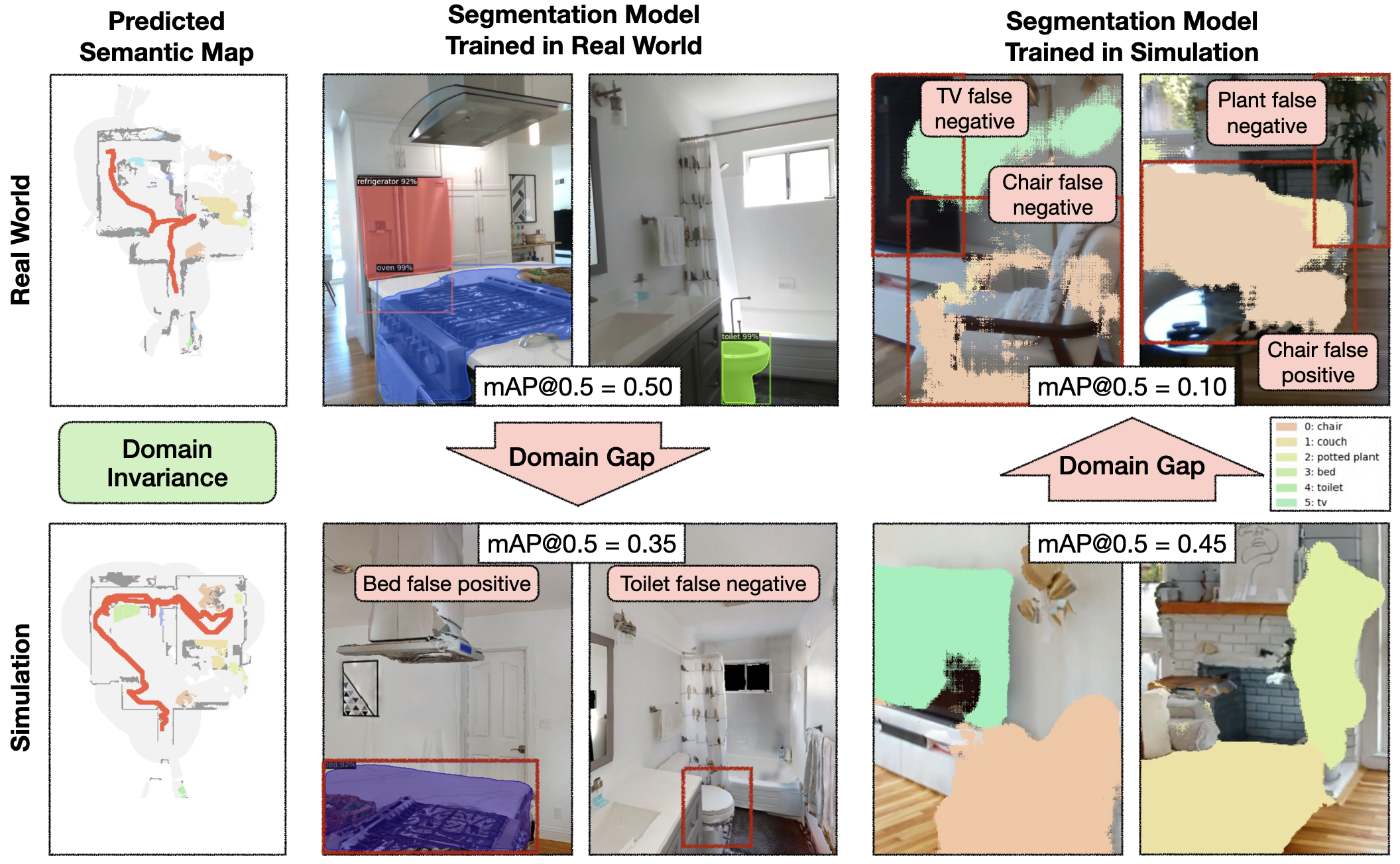
Инсайт 2: симуляционный и реальный разрыв в режимах ошибок для модульного обучения
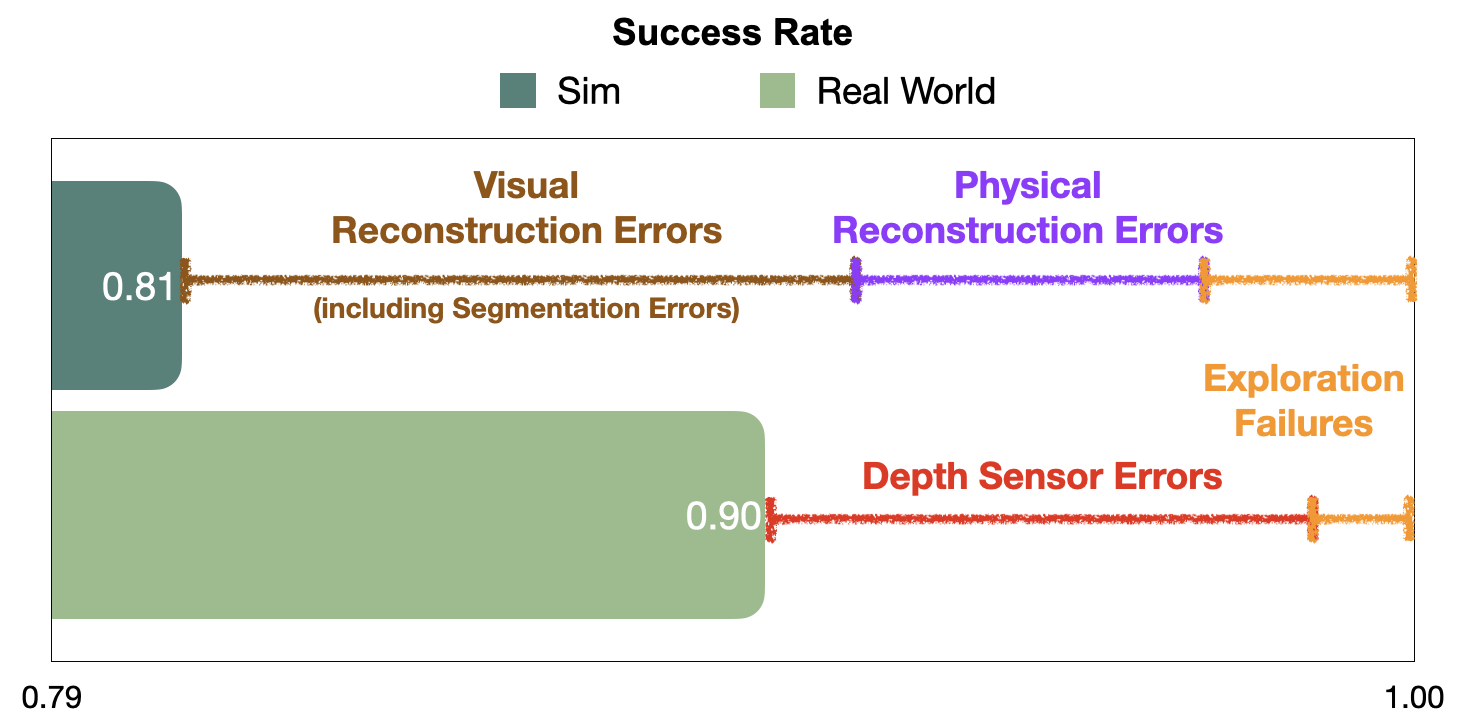
Удивительно, но модульное обучение в реальности работает даже лучше, чем моделирование. Детальный анализ показывает, что многие сбои модульной политики обучения, возникающие в симуляции, связаны с ошибками реконструкции, которых в действительности не происходит. Ошибки визуальной реконструкции составляют 10% от общего числа 19% неудачных эпизодов, а ошибки физической реконструкции — еще 5%. Напротив, сбои в реальном мире происходят преимущественно из-за ошибок датчика глубины, в то время как большинство тестов семантической навигации в моделировании предполагают идеальное определение глубины. Помимо объяснения разрыва в производительности между симуляцией и реальностью для модульного обучения, этот разрыв в режимах ошибок вызывает беспокойство, поскольку он ограничивает полезность моделирования для диагностики узких мест и дальнейшего улучшения политик. Мы показываем репрезентативные примеры каждого режима ошибки и предлагаем конкретные шаги, чтобы закрыть этот пробел в документе.
Выводы
Для практиков:
- Модульное обучение может надежно перемещаться по объектам с 90%-ным успехом.
Для исследователей:
- Модели, основанные на изображениях RGB, трудно перенести из симуляции в реальность => использовать модульность и абстракцию в политиках.
- Отключите режимы симуляции и реальных ошибок => оцените семантическую навигацию на реальных роботах.
Дополнительные материалы о робототехнике и машинном обучении см. мой блог.

Теофиль Жерве — аспирант кафедры машинного обучения Университета Карнеги-Меллон.
Теофиль Жерве — аспирант кафедры машинного обучения Университета Карнеги-Меллон.