В наша недавняя статья мы исследуем, как многоагентное глубокое обучение с подкреплением может служить моделью сложных социальных взаимодействий, таких как формирование социальных норм. Этот новый класс моделей может обеспечить путь к созданию более богатых и подробных симуляций мира.
Люди ультра социальные виды. По сравнению с другими млекопитающими мы больше выигрываем от сотрудничества, но мы также больше зависим от него и сталкиваемся с более серьезными проблемами сотрудничества. Сегодня человечество сталкивается с многочисленными проблемами сотрудничества, включая предотвращение конфликтов из-за ресурсов, обеспечение доступа каждого к чистому воздуху и питьевой воде, искоренение крайней нищеты и борьбу с изменением климата. Многие из проблем сотрудничества, с которыми мы сталкиваемся, трудно решить, потому что они связаны со сложными сетями социальных и биофизических взаимодействий, называемых социально-экологические системы. Однако люди могут коллективно научиться преодолевать проблемы сотрудничества, с которыми мы сталкиваемся. Мы достигаем этого благодаря постоянно развивающейся культуре, включая нормы и институты, которые организуют наше взаимодействие с окружающей средой и друг с другом.
Однако нормы и институты иногда не решают проблемы сотрудничества. Например, люди могут чрезмерно эксплуатировать такие ресурсы, как леса и рыболовство, что приводит к их краху. В таких случаях лица, определяющие политику, могут издавать законы для изменения институциональных правил или разработки других вмешательства, чтобы попытаться изменить нормы в надежде на положительные изменения. Но политические вмешательства не всегда работают так, как предполагалось. Это связано с тем, что реальные социально-экологические системы значительно более сложный чем модели, которые мы обычно используем, чтобы попытаться предсказать последствия политик-кандидатов.
Модели, основанные на теории игр, часто применяются для изучения культурной эволюции. В большинстве этих моделей ключевые взаимодействия агентов друг с другом выражаются в «матрице выплат». В игре с двумя участниками и двумя действиями A и B матрица выигрышей определяет значение четырех возможных исходов: (1) мы оба выбираем A, (2) мы оба выбираем B, (3) я выбираю A, а вы выбираете B и (4) я выбираю B, а вы выбираете A. Самый известный пример — «дилемма заключенного», в которой действия интерпретируются как «сотрудничать» и «предать». Рациональные агенты, которые действуют в соответствии со своими близорукими интересами, обречены на отступничество в дилемме заключенного, даже если возможен лучший исход взаимного сотрудничества.
Теоретико-игровые модели нашли очень широкое применение. Исследователи в различных областях использовали их для изучения широкого круга различных явлений, включая экономику и эволюцию человеческой культуры. Однако теория игр — это не нейтральный инструмент, а скорее язык моделирования, основанный на глубоком мнении. Он налагает строгое требование, чтобы все в конечном итоге обналичивалось с точки зрения матрицы выплат (или эквивалентного представления). Это означает, что разработчик модели должен знать или быть готовым предположить все о том, как эффекты отдельных действий объединяются для создания стимулов. Иногда это уместно, и теоретико-игровой подход добился многих заметных успехов, например, в моделировании поведение олигополистических фирм и международные отношения эпохи холодной войны. Однако основная слабость теории игр как языка моделирования проявляется в ситуациях, когда разработчик моделей не полностью понимает, как выбор людей комбинируется для получения выигрыша. К сожалению, это чаще всего происходит с социально-экологическими системами, потому что их социальная и экологическая части взаимодействуют сложным образом, который мы не до конца понимаем.
Работа, которую мы представляем здесь, является одним из примеров в рамках исследовательской программы, которая пытается создать альтернативную структуру моделирования, отличную от теории игр, для использования в изучении социально-экологических систем. Наш подход формально можно рассматривать как разновидность агентное моделирование. Однако его отличительной чертой является включение алгоритмических элементов искусственного интеллекта, особенно многоагентного глубокого обучения с подкреплением.
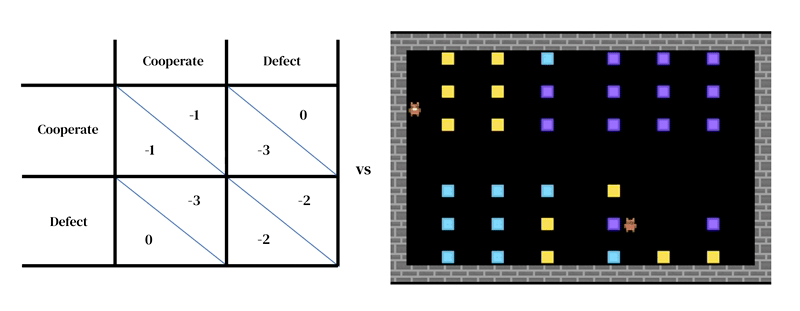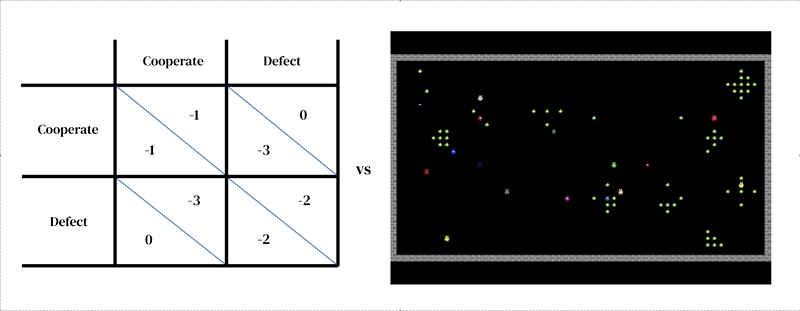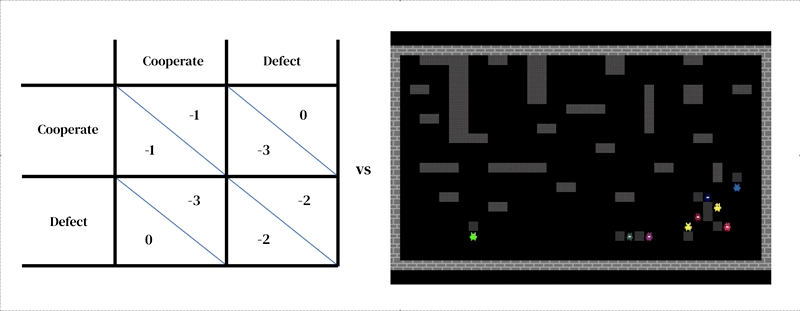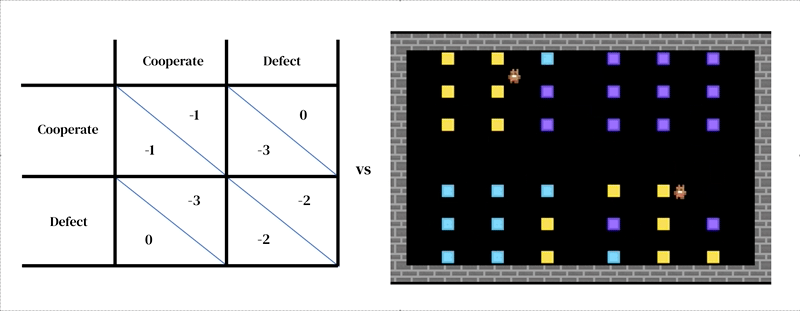
Основная идея этого подхода заключается в том, что каждая модель состоит из двух взаимосвязанных частей: (1) богатой динамической модели среды и (2) модели индивидуального принятия решений.
Первый принимает форму разработанного исследователем симулятора: интерактивная программа, которая принимает текущее состояние среды и действия агентов и выводит следующее состояние среды, а также наблюдения за всеми агентами и их мгновенные вознаграждения. Модель индивидуального принятия решений также обусловлена состоянием окружающей среды. Это агент которая учится на своем прошлом опыте методом проб и ошибок. Агент взаимодействует с окружающей средой, получая наблюдения и производя действия. Каждый агент выбирает действия в соответствии со своей поведенческой политикой, отображением наблюдений в действия. Агенты учатся, изменяя свою политику, чтобы улучшить ее в любом желаемом измерении, обычно для получения большего вознаграждения. Политика хранится в нейронной сети. Агенты узнают «с нуля», на собственном опыте, как устроен мир и что они могут сделать, чтобы заработать больше вознаграждений. Они достигают этого, настраивая свои сетевые веса таким образом, чтобы пиксели, которые они получают в качестве наблюдений, постепенно трансформировались в компетентные действия. Несколько агентов обучения могут обитать в одной и той же среде друг с другом. В этом случае агенты становятся взаимозависимыми, поскольку их действия влияют друг на друга.
Как и другие подходы к моделированию на основе агентов, многоагентное глубокое обучение с подкреплением позволяет легко определять модели, пересекающие уровни анализа, которые было бы трудно рассматривать с помощью теории игр. Например, действия могут быть гораздо ближе к низкоуровневым двигательным примитивам (например, «идти вперед»; «повернуть направо»), чем к высокоуровневым стратегическим решениям теории игр (например, «сотрудничать»). Это важная функция, необходимая для захвата ситуаций, когда агенты должны практиковаться, чтобы научиться эффективно реализовать свой стратегический выбор. например в одном изучать, агенты научились сотрудничать, по очереди очищая реку. Это решение было возможно только потому, что среда имела пространственное и временное измерения, в которых агенты имели большую свободу в том, как они структурируют свое поведение по отношению друг к другу. Интересно, что в то время как окружающая среда допускала множество различных решений (таких как территориальность), агенты сошлись на том же поочередном решении, что и игроки-люди.
В нашем последнем исследовании мы применили этот тип модели к открытому вопросу в исследованиях культурной эволюции: как объяснить существование ложных и произвольных социальных норм, которые, по-видимому, не имеют немедленных материальных последствий за их нарушение, помимо тех, которые навязываются обществом. Например, в некоторых обществах мужчины должны носить брюки, а не юбки; во многих есть слова или жесты рук, которые не следует употреблять в вежливой компании; и в большинстве есть правила о том, как укладывать волосы или что носить на голове. Мы называем эти социальные нормы «глупыми правилами». Важно отметить, что в нашей структуре нужно учиться как обеспечению соблюдения социальных норм, так и их соблюдению. Наличие социальной среды, включающей «глупое правило», означает, что агенты имеют больше возможностей узнать о соблюдении норм в целом. Эта дополнительная практика позволяет им более эффективно применять важные правила. В целом, «глупое правило» может принести пользу населению – неожиданный результат. Такой результат возможен только потому, что наша симуляция направлена на обучение: обеспечение соблюдения правил и их соблюдение — это сложные навыки, для развития которых требуется тренировка.
Мы находим этот результат по глупым правилам таким захватывающим отчасти потому, что он демонстрирует полезность мультиагентного глубокого обучения с подкреплением в моделировании культурной эволюции. Культура способствует успеху или провалу политического вмешательства в социально-экологические системы. Например, укрепление социальных норм в отношении вторичной переработки является частью решение к некоторым экологическим проблемам. Следуя этой траектории, более богатые модели могут привести к более глубокому пониманию того, как разрабатывать меры для социально-экологических систем. Если моделирование станет достаточно реалистичным, можно будет даже проверить влияние вмешательств, например, направленных на разработать налоговый кодекс, который способствует продуктивности и справедливости.
Этот подход предоставляет исследователям инструменты для определения подробных моделей интересующих их явлений. Конечно, как и у всех исследовательских методологий, у нее есть свои сильные и слабые стороны. Мы надеемся узнать больше о том, когда этот стиль моделирования может быть плодотворно применен в будущем. Хотя для моделирования не существует панацеи, мы считаем, что есть веские причины обращаться к многоагентному глубокому обучению с подкреплением при построении моделей социальных явлений, особенно когда они связаны с обучением.