Итак, вы только что закончили разработку своей замечательной архитектуры нейронной сети. Он имеет невероятное количество 300 полностью связанных слоев, чередующихся с 200 слоями.
сверточные слои
с 20 каналами в каждом, где результат подается как семя славного
двунаправленный
сложенный
ЛСТМ с щепоткой
внимание. После обучения вы получаете точность 99,99% и готовы к отправке в производство.
Но потом вы понимаете, что производственные ограничения не позволят вам провести вывод, используя этого зверя. Вам нужно, чтобы вывод был сделан менее чем за 200 миллисекунд.
Другими словами, нужно отсечь половину слоев, отказаться от использования сверток, и не будем заморачиваться с затратным LSTM…
Если бы вы только могли сделать эту удивительную модель быстрее!

Здесь, в Taboola, мы сделали это. Ну, не совсем… Поясню.
Одна из наших моделей должна предсказывать CTR (Click Through Rate) элемента, или другими словами — вероятность того, что пользователю понравится рекомендация статьи и он кликнет по ней.
Модель имеет несколько модальностей в качестве входных данных, каждая из которых проходит различное преобразование. Некоторые из них:
- категориальные признаки: это
встроенный
в плотное представление - изображение: пиксели проходят через сверточные и полносвязные слои
- текст: после токенизации текст проходит через LSTM, за которым следует внимание к себе
Эти обработанные модальности затем проходят через полностью связанные слои, чтобы изучить взаимодействие между модальностями, и, наконец, они проходят через
МДН
слой.
Как вы понимаете, эта модель медленная.
Мы решили настаивать на предсказательной силе модели, а не урезать компоненты, и придумали инженерное решение.
Давайте сосредоточимся на имиджевой составляющей. Результатом этого компонента является изученное представление изображения. Другими словами, при наличии изображения компонент изображения выводит вложение.
Модель детерминирована, поэтому одно и то же изображение будет иметь одинаковое вложение. Это дорого, поэтому мы можем кэшировать его. Позвольте мне подробно рассказать о том, как мы это реализовали.
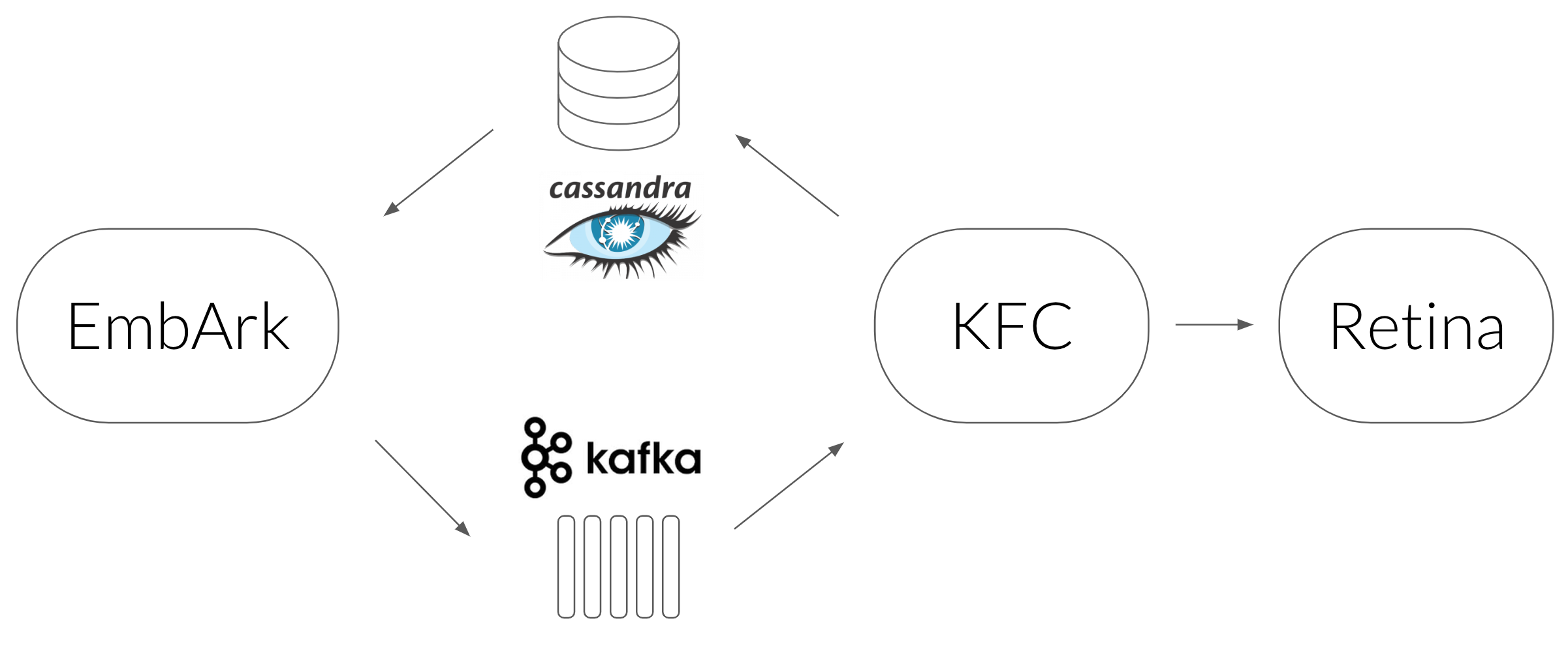
- Мы использовали Кассандра база данных в качестве кеша, который сопоставляет URL-адрес изображения с его внедрением.
- Служба, которая запрашивает Cassandra, называется EmbArk (Embedding Archive,
опечатка конечно). Это gRPC сервер, который получает URL-адрес изображения от клиента и извлекает вложение из Cassandra. При отсутствии кеша EmbArk отправляет асинхронный запрос на встраивание этого изображения. Почему асинхронный? Потому что нам нужно, чтобы EmbArk отвечал с результатом как можно быстрее. Поскольку он не может дождаться встраивания изображения, он возвращает специальное вложение OOV (Out Of Vocabulary). - Асинхронный механизм, который мы выбрали для использования, Кафка — потоковая платформа, используемая в качестве очереди сообщений.
- Следующим звеном является KFC (Kafka Frontend Client) — потребитель Kafka, который мы реализовали для синхронной передачи сообщений службе встраивания и сохранения полученных вложений в Cassandra.
- Служба встраивания называется Retina. Он получает URL-адрес изображения от KFC, загружает его, предварительно обрабатывает и оценивает сверточные слои, чтобы получить окончательное встраивание.
- Балансировка нагрузки всех компонентов выполняется с помощью
Линкерд. - EmbArk, KFC, Retina и Linkerd бегут внутрь Докери они организованы Кочевник. Это позволяет нам легко масштабировать каждый компонент по своему усмотрению.
Эта архитектура изначально использовалась для изображений. Доказав его ценность, мы решили использовать его и для других компонентов, таких как текст.
EmbArk оказался хорошим решением для передача обучения слишком. Допустим, мы считаем, что содержание изображения дает хороший сигнал для прогнозирования CTR. Таким образом, модель, обученная классифицировать объект на изображении, например
Зарождение
было бы ценно для наших нужд. Мы можем загрузить Inception в Retina, сказать модели, которую мы собираемся обучать, что мы хотим использовать встраивание Inception, вот и все.
Улучшилось не только время вывода, но и процесс обучения. Это возможно только тогда, когда мы не хотим тренироваться от начала до конца, поскольку градиенты не могут распространяться обратно через EmbArk.
Поэтому всякий раз, когда вы используете модель в производстве, вы должны использовать EmbArk, верно? Ну не всегда…

Здесь есть три довольно строгих предположения.
1. Встраивание OOV для новых входных данных не имеет большого значения
Нам не мешает то, что когда мы впервые видим изображение, у нас не будет его встраивания.
В нашей производственной системе это нормально, так как CTR оценивается несколько раз для одного и того же товара в течение короткого периода времени. Мы создаем списки элементов, которые мы хотим рекомендовать, каждые несколько минут, поэтому, даже если элемент не попадет в список из-за неоптимального прогноза CTR, он попадет в следующий цикл.
2. Скорость новых входов низкая
Это правда, что в Taboola мы постоянно получаем много новых предметов. Но относительно количества выводов, которые нам нужно выполнить для уже известных элементов, не так уж много.
3. Вложения не меняются часто
Поскольку вложения кэшируются, мы рассчитываем на то, что они не изменятся со временем. Если они это сделают, нам нужно будет выполнить аннулирование кеша и пересчитать вложения с помощью Retina. Если бы это происходило часто, мы бы потеряли преимущество архитектуры. Для таких случаев, как зарождение или языковое моделирование, это допущение остается в силе, поскольку семантика со временем существенно не меняется.
Иногда использование современных моделей может быть проблематичным из-за их вычислительных требований. Благодаря кэшированию промежуточных результатов (встраиваниям) мы смогли преодолеть эту проблему и по-прежнему наслаждаться современными результатами.
Это решение подходит не всем, но если три вышеупомянутых допущения верны для вашего приложения, вы можете рассмотреть возможность использования аналогичной архитектуры.
Используя парадигму микросервисов, другие команды в компании смогли использовать EmbArk для нужд, отличных от предсказания CTR. Например, одна команда использовала EmbArk для встраивания изображений и текста для обнаружения дубликатов в разных элементах. Но я оставлю эту историю для другого поста…
Первоначально опубликовано мной на
Engineering.taboola.com.