
ОПЕНАЙ
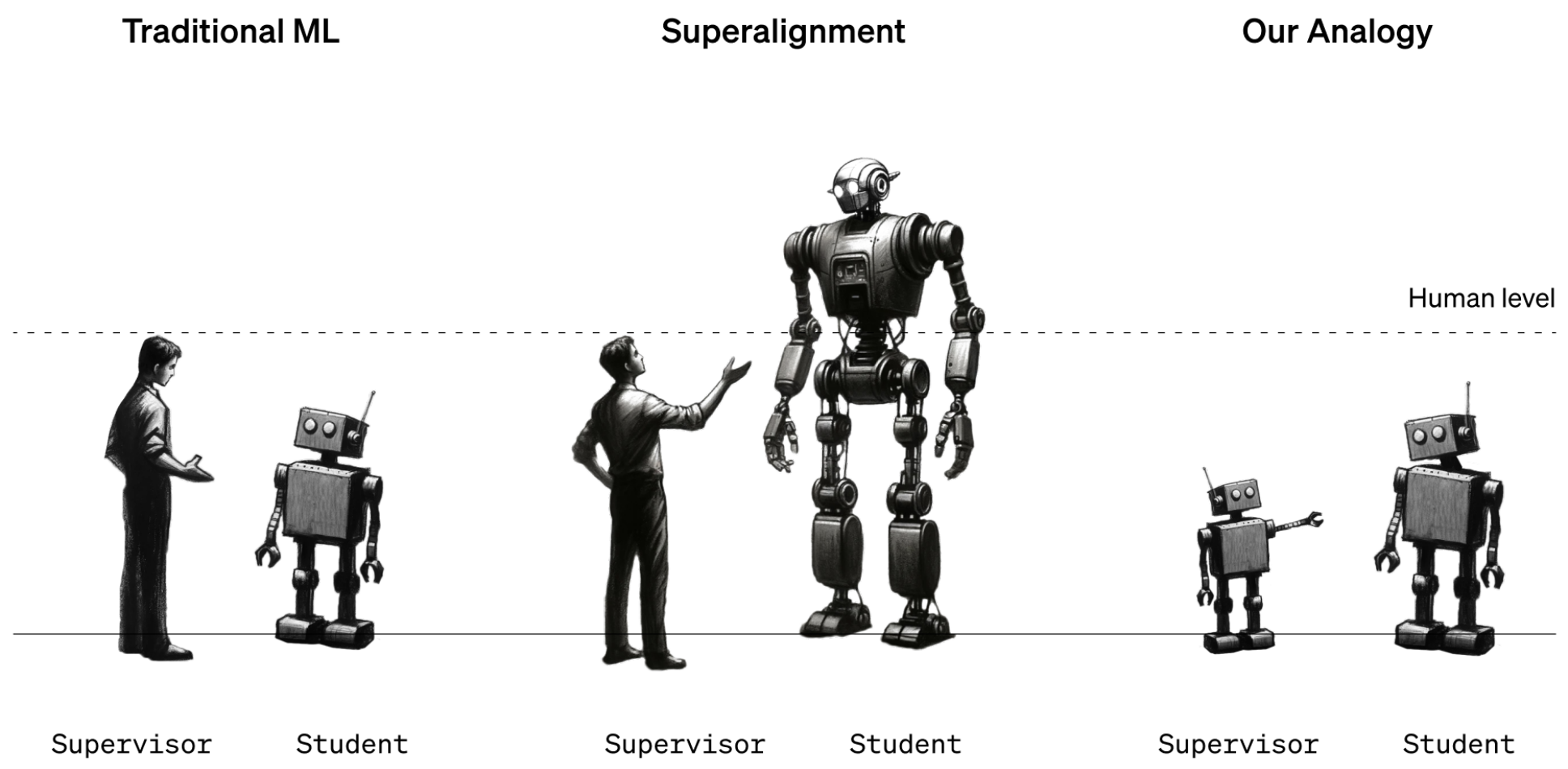
Исследователи отмечают, что проблему сложно изучать, поскольку сверхчеловеческих машин не существует. Поэтому они использовали дублеров. Вместо того, чтобы смотреть на то, как люди могут управлять сверхчеловеческими машинами, они смотрели на то, как GPT-2, модель, выпущенная OpenAI пять лет назад, может контролировать GPT-4, последнюю и самую мощную модель OpenAI. «Если вам удастся это сделать, это может стать доказательством того, что вы можете использовать аналогичные методы, чтобы заставить людей контролировать сверхчеловеческие модели», — говорит Коллин Бернс, другой исследователь из группы сверхвыравнивания.
Команда взяла GPT-2 и обучила его выполнять несколько различных задач, включая набор шахматных головоломок и 22 распространенных теста обработки естественного языка, которые оценивают умозаключения, анализ настроений и так далее. Они использовали ответы GPT-2 на эти тесты и головоломки, чтобы обучить GPT-4 выполнять те же задачи. Это как если бы третьеклассник научил 12-классника выполнять задание. Хитрость заключалась в том, чтобы сделать это так, чтобы GPT-4 не сильно пострадал в производительности.
Результаты были неоднозначными. Команда измерила разницу в производительности между GPT-4, обученным на лучших догадках GPT-2, и GPT-4, обученным правильным ответам. Они обнаружили, что GPT-4, обученный GPT-2, справляется с языковыми задачами на 20–70% лучше, чем GPT-2, но хуже справляется с шахматными головоломками.
Тот факт, что GPT-4 вообще превзошел своего учителя, впечатляет, говорит член команды Павел Измайлов: «Это действительно неожиданный и положительный результат». Но это далеко не то, что могло бы сделать само по себе, говорит он. Они приходят к выводу, что этот подход многообещающий, но требует дополнительной работы.
«Это интересная идея», — говорит Тило Хагендорф, исследователь искусственного интеллекта из Штутгартского университета в Германии, который занимается вопросами выравнивания. Но он считает, что GPT-2 может быть слишком глупым, чтобы быть хорошим учителем. «GPT-2 имеет тенденцию давать бессмысленные ответы на любую задачу, которая немного сложна или требует рассуждения», — говорит он. Хагендорфф хотел бы знать, что произойдет, если вместо этого использовать GPT-3.
Он также отмечает, что этот подход не учитывает гипотетический сценарий Суцкевера, в котором сверхинтеллект скрывает свое истинное поведение и притворяется, что он согласен, хотя на самом деле это не так. «Будущие сверхчеловеческие модели, скорее всего, будут обладать новыми способностями, неизвестными исследователям», — говорит Хагендорфф. «Как в таких случаях может работать выравнивание?»
Но указать на недостатки легко, говорит он. Он рад видеть, что OpenAI переходит от предположений к экспериментам: «Я аплодирую OpenAI за их усилия».
OpenAI теперь хочет привлечь других к своему делу. Наряду с этим обновлением исследования компания объявила новый денежный горшок на 10 миллионов долларов которые он планирует использовать для финансирования людей, работающих над сверхвыравниванием. Он предложит гранты в размере до 2 миллионов долларов университетским лабораториям, некоммерческим организациям и отдельным исследователям, а также годовые стипендии в размере 150 000 долларов США для аспирантов. «Мы очень воодушевлены этим», — говорит Ашенбреннер. «Мы действительно думаем, что новые исследователи могут внести большой вклад».