
ИТ-директора и другие технологические лидеры пришли к пониманию того, что сценарии использования генеративного искусственного интеллекта (GenAI) требуют тщательного мониторинга: этим приложениям присущи риски, а сильные возможности наблюдения помогают их смягчить. Они также поняли, что те же показатели точности обработки данных, которые обычно используются для сценариев прогнозного использования, хотя и полезны, но не полностью достаточны для LLMOps.
Когда дело доходит до мониторинга результатов LLM, правильность ответов остается важной, но теперь организациям также необходимо беспокоиться о показателях, связанных с токсичностью, читаемостью, утечками личной информации (PII), неполнотой информации и, что наиболее важно, затратами на LLM. Хотя все эти показатели являются новыми и важны для конкретных случаев использования, количественная оценка неизвестных затрат на LLM обычно является тем, что встает в первую очередь в обсуждениях с нашими клиентами.
В этой статье описывается обобщенный подход к определению и мониторингу пользовательских показателей производительности для конкретных случаев использования генеративного ИИ для развертываний, которые отслеживаются с помощью DataRobot AI Production.
Помните, что модели не обязательно создавать с помощью DataRobot, чтобы использовать обширные функции управления и мониторинга. Также помните, что DataRobot предлагает множество готовых показателей развертывания в категориях «Работоспособность сервисов», «Дрейф данных», «Точность» и «Справедливость». Настоящая дискуссия идет о добавление собственных пользовательских метрик в отслеживаемое развертывание.
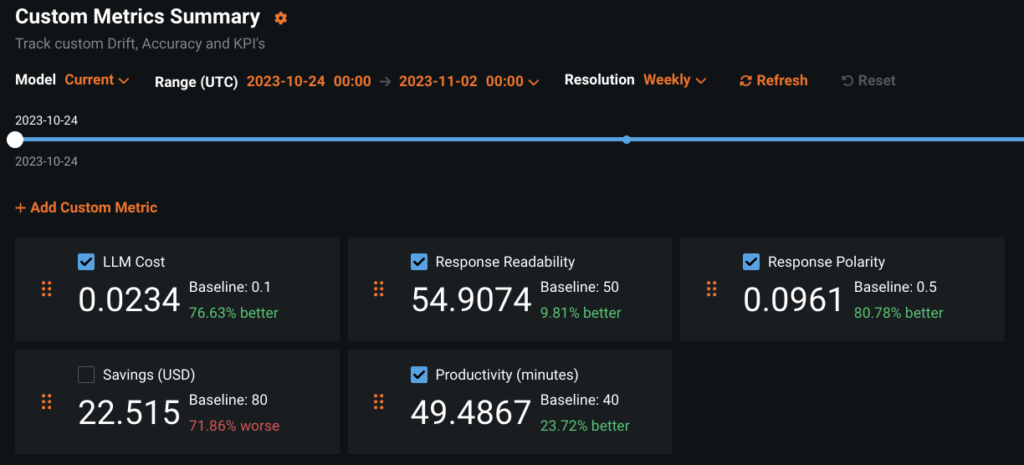
Чтобы проиллюстрировать эту функцию, мы используем пример логистической отрасли опубликованный на Github сообщества DataRobot, который вы можете воспроизвести самостоятельно с помощью лицензии DataRobot или бесплатной пробной учетной записи. Если вы решите получить практический опыт, посмотрите видео ниже и ознакомьтесь с документация по специальным метрикам.
Мониторинг показателей для сценариев использования генеративного ИИ
Хотя DataRobot предлагает вам гибкость в определении любой пользовательской метрики, приведенная ниже структура поможет вам сузить ваши метрики до управляемого набора, который по-прежнему обеспечивает широкую видимость. Если вы определите один или два показателя в каждой из категорий ниже, вы сможете отслеживать затраты, опыт конечных пользователей, неправильное поведение LLM и создание ценности. Давайте углубимся в каждый из них более подробно.
Общая стоимость владения
Метрики в этой категории отслеживают расходы на эксплуатацию генеративного решения искусственного интеллекта. В случае LLM с самостоятельным размещением это будут прямые затраты на вычисления. При использовании LLM, размещенных на внешнем сервере, это будет зависеть от стоимости каждого вызова API.
Определение индивидуального показателя затрат для внешнего LLM потребует знания модели ценообразования. На момент написания этой статьи Страница цен на Azure OpenAI цена за использование GPT-3.5-Turbo 4K указана как 0,0015 доллара США за 1000 токенов в подсказке плюс 0,002 доллара США за 1000 токенов в ответе. Следующее get_gpt_3_5_cost функция вычисляет цену за прогноз при использовании этих жестко запрограммированных цен и количества токенов для подсказки и ответа, рассчитанных с помощью Тиктокен.
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
def get_gpt_token_count(text):
return len(encoding.encode(text))
def get_gpt_3_5_cost(
prompt, response, prompt_token_cost=0.0015 / 1000, response_token_cost=0.002 / 1000
):
return (
get_gpt_token_count(prompt) * prompt_token_cost
+ get_gpt_token_count(response) * response_token_cost
)Пользовательский опыт
Метрики в этой категории отслеживают качество ответов с точки зрения предполагаемого конечного пользователя. Качество будет варьироваться в зависимости от варианта использования и пользователя. Возможно, вам понадобится чат-бот для исследователя-помощника юриста, который будет давать длинные ответы, официально написанные и содержащие множество деталей. Однако чат-бот, отвечающий на основные вопросы об освещении приборной панели вашего автомобиля, должен отвечать прямо, не используя незнакомых автомобильных терминов.
Двумя основными показателями пользовательского опыта являются длина ответа и читаемость. Выше вы уже видели, как фиксировать длину сгенерированного ответа и как она связана со стоимостью. Существует множество вариантов показателей читаемости. Все они основаны на некоторых сочетаниях средней длины слова, среднего количества слогов в словах и средней длины предложения. Флеш-Кинкейд — один из таких показателей читаемости, получивший широкое распространение. По шкале от 0 до 100 более высокие баллы означают, что текст легче читать. Вот простой способ рассчитать читаемость генеративного ответа с помощью пакета textstat.
import textstat
def get_response_readability(response):
return textstat.flesch_reading_ease(response)Показатели безопасности и нормативные требования
Эта категория содержит метрики для мониторинга решений генеративного искусственного интеллекта на предмет контента, который может быть оскорбительным (безопасность) или нарушать закон (нормативные требования). Правильные показатели для представления этой категории будут сильно различаться в зависимости от варианта использования и правил, применимых к вашей отрасли или вашему местоположению.
Важно отметить, что метрики в этой категории применяются к запросам, отправляемым пользователями, и ответам, генерируемым большими языковыми моделями. Возможно, вы захотите отслеживать подсказки на предмет оскорбительных и токсичных высказываний, явной предвзятости, хаков с подсказками или утечек личных данных. Возможно, вы также захотите отслеживать генеративные реакции на предмет токсичности и предвзятости, а также галлюцинаций и полярности.
Мониторинг полярности ответа полезен для обеспечения того, чтобы решение не создавало текст с постоянным негативным прогнозом. В связанном примере, в котором рассматриваются упреждающие электронные письма для информирования клиентов о статусе доставки, полярность сгенерированного электронного письма проверяется, прежде чем оно будет показано конечному пользователю. Если электронное письмо крайне негативное, оно заменяется сообщением, в котором клиенту предлагается обратиться в службу поддержки клиентов для получения обновленной информации о доставке. Вот один из способов определить метрику полярности с помощью пакета TextBlob.
import numpy as np
from textblob import TextBlob
def get_response_polarity(response):
blob = TextBlob(response)
return np.mean((sentence.sentiment.polarity for sentence in blob.sentences))Ценность бизнеса
ИТ-директора находятся под растущим давлением необходимости продемонстрировать очевидную ценность для бизнеса генеративных решений искусственного интеллекта. В идеальном мире рентабельность инвестиций и способ ее расчета являются факторами, принимаемыми во внимание при утверждении создаваемого варианта использования. Но в нынешней спешке экспериментировать с генеративным ИИ это не всегда так. Добавление показателей ценности бизнеса к решению GenAI, созданному для проверки концепции, может помочь обеспечить долгосрочное финансирование для него и для следующего варианта использования.
Генеративный искусственный интеллект 101 для руководителей: ускоренный видеокурс
Мы не можем разработать за вас стратегию генеративного ИИ, но мы можем направить вас в правильном направлении.
Метрики в этой категории полностью зависят от варианта использования. Чтобы проиллюстрировать это, рассмотрим, как измерить бизнес-ценность примера использования, связанного с упреждающими уведомлениями клиентов о статусе их поставок.
Один из способов измерить ценность — рассмотреть среднюю скорость набора текста агента службы поддержки, который в отсутствие генеративного решения напечатал бы специальное электронное письмо с нуля. Игнорируя время, необходимое для изучения статуса груза клиента, и просто определяя время набора текста со скоростью 150 слов в минуту и 20 долларами в час, можно рассчитать следующим образом.
def get_productivity(response):
return get_gpt_token_count(response) * 20 / (150 * 60)Скорее всего, реальный эффект для бизнеса будет заключаться в уменьшении количества обращений в контакт-центр и повышении удовлетворенности клиентов. Предположим, что в этом бизнесе количество звонков снизилось на 30% с момента внедрения решения генеративного искусственного интеллекта. В этом случае реальную экономию, связанную с каждым заранее отправленным электронным письмом, можно рассчитать следующим образом.
def get_savings(CONTAINER_NUMBER):
prob = 0.3
email_cost = $0.05
call_cost = $4.00
return prob * (call_cost - email_cost)Создание и отправка пользовательских показателей в DataRobot
Создать специальную метрику
Если у вас есть определения и имена для ваших пользовательских метрик, добавить их в развертывание очень просто. Вы можете добавить метрики на вкладку «Пользовательские метрики» развертывания с помощью кнопки +Добавить специальную метрику в пользовательском интерфейсе или с помощью кода. Для обоих маршрутов вам необходимо будет предоставить информацию, показанную в диалоговом окне ниже.
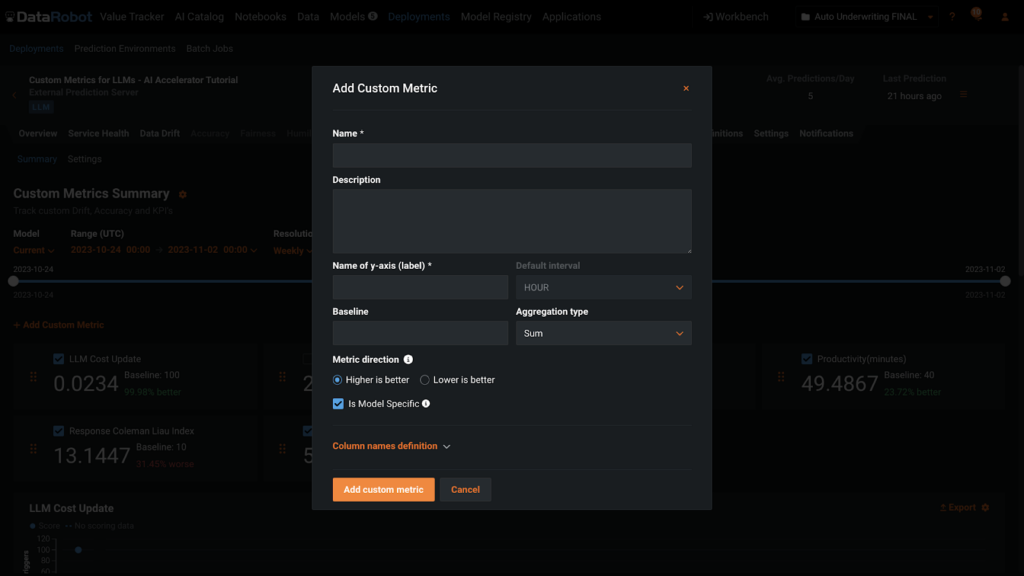
Отправить специальный показатель
Существует несколько вариантов отправки пользовательских метрик в развертывание, которые подробно описаны в разделе сопроводительная документация. В зависимости от того, как вы определяете метрики, вы можете узнать значения сразу или может возникнуть задержка, и вам придется связать их с развертыванием позднее.
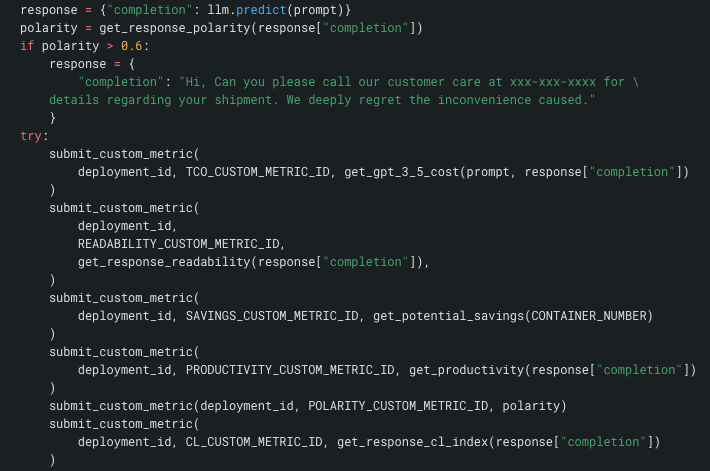
Лучше всего объединить отправку данных о показателях с прогнозом LLM, чтобы не пропустить какую-либо информацию. На этом снимке экрана ниже, который представляет собой отрывок из более крупной функции, вы видите llm.predict() в первом ряду. Далее вы увидите проверку полярности и логику переопределения. Наконец, вы увидите отправку метрик в развертывание.
Другими словами, пользователь не может использовать это генеративное решение без записи показателей. Каждый звонок в LLM и его ответ полностью отслеживаются.
DataRobot для генеративного искусственного интеллекта
Мы надеемся, что это глубокое погружение в метрики генеративного ИИ поможет вам лучше понять, как использовать платформу DataRobot AI для управления и управления вариантами использования генеративного ИИ. Хотя эта статья сосредоточена исключительно на мониторинге показателей, платформа DataRobot AI может помочь вам упростить весь жизненный цикл искусственного интеллекта — безопасно и надежно создавать, эксплуатировать и управлять генеративными решениями искусственного интеллекта корпоративного уровня.
Наслаждайтесь свободой работы со всеми лучшими инструментами и методами в облачных средах и в одном месте. Разрушайте разрозненность и предотвращайте появление новых с помощью единого последовательного опыта. Развертывайте и поддерживайте безопасные, высококачественные генеративные приложения и решения искусственного интеллекта в производстве.