
Это гостевой пост Хосе Бенитеса, основателя и директора AI, и Маттиаса Пончона, руководителя отдела инфраструктуры Intuitivo.
Intuitivo, пионер инноваций в сфере розничной торговли, совершает революцию в сфере шоппинга благодаря своей облачной системе обработки транзакций на базе искусственного интеллекта и машинного обучения (AI/ML). Эта революционная технология позволяет нам одновременно управлять миллионами автономных точек продаж (A-POP), меняя способ совершения покупок клиентами. Наше решение превосходит традиционные торговые автоматы и их альтернативы, предлагая экономическое преимущество благодаря десятикратно более низкой стоимости, простоте настройки и эксплуатации, не требующей обслуживания. Наши инновационные новые A-POP (или торговые автоматы) обеспечивают повышение качества обслуживания клиентов при в десять раз меньших затрат благодаря преимуществам в производительности и стоимости, которые обеспечивает AWS Inferentia. Inferentia позволила нам запускать модели компьютерного зрения You Only Look Once (YOLO) в пять раз быстрее, чем наше предыдущее решение, и обеспечивает бесперебойный процесс совершения покупок в режиме реального времени для наших клиентов. Кроме того, Inferentia также помогла нам сократить расходы на 95 процентов по сравнению с нашим предыдущим решением. В этом посте мы рассмотрим наш вариант использования, проблемы и краткий обзор нашего решения с использованием Inferentia.
Меняющаяся ситуация в розничной торговле и потребность в A-POP
Розничная торговля быстро развивается, и потребители ожидают того же простого в использовании и удобного опыта, к которому они привыкли при совершении покупок в цифровом формате. Чтобы эффективно преодолеть разрыв между цифровым и физическим миром и удовлетворить меняющиеся потребности и ожидания клиентов, необходим преобразующий подход. В Intuitivo мы верим, что будущее розничной торговли заключается в создании высоко персонализированных автономных точек продаж на базе искусственного интеллекта и компьютерного зрения (A-POP). Эта технологическая инновация делает продукты доступными для покупателей. Он не только дает покупателям любимые товары под рукой, но и предлагает им беспрепятственный процесс совершения покупок, лишенный длинных очередей или сложных систем обработки транзакций. Мы рады возглавить эту захватывающую новую эру в розничной торговле.
Благодаря нашей передовой технологии ритейлеры могут быстро и эффективно развернуть тысячи точек A-POP. Масштабирование всегда было сложной задачей для ритейлеров, главным образом из-за сложностей логистики и обслуживания, связанных с расширением традиционных торговых автоматов или других решений. Однако наше решение на основе камеры, которое устраняет необходимость в датчиках веса, RFID или других дорогостоящих датчиках, не требует обслуживания и значительно дешевле. Это позволяет ритейлерам эффективно создавать тысячи точек A-POP, предоставляя клиентам непревзойденный опыт покупок, а также предлагая ритейлерам экономичное и масштабируемое решение.

Использование облачного вывода для идентификации продукта в реальном времени
При разработке системы распознавания продуктов и оплаты с помощью камеры мы столкнулись с решением, следует ли это делать на периферии или в облаке. Рассмотрев несколько архитектур, мы разработали систему, которая загружает видео транзакций в облако для обработки.
Наши конечные пользователи начинают транзакцию со сканирования QR-кода A-POP, который вызывает разблокировку A-POP, а затем клиенты берут то, что хотят, и уходят. Предварительно обработанные видео этих транзакций загружаются в облако. Наш конвейер транзакций на базе искусственного интеллекта автоматически обрабатывает эти видео и взимает соответствующую плату со счета клиента.
На следующей диаграмме показана архитектура нашего решения.
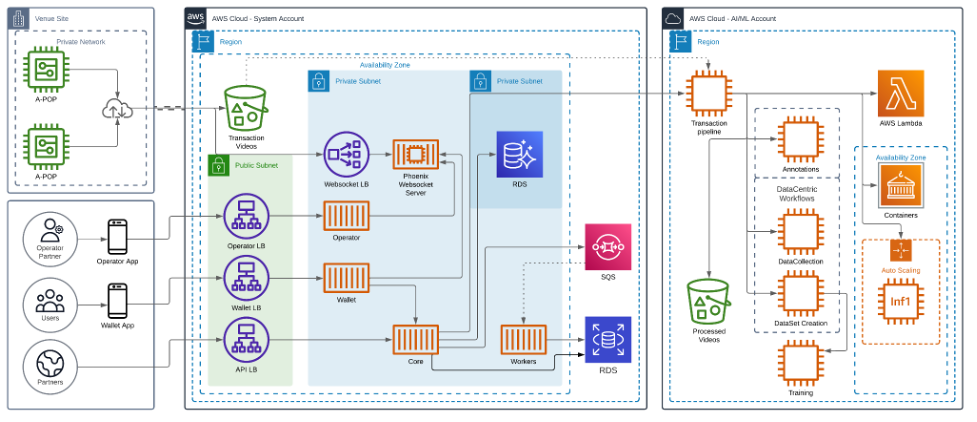
Откройте возможности высокопроизводительного и экономичного вывода с помощью AWS Inferentia
Поскольку ритейлеры стремятся масштабировать свою деятельность, стоимость A-POP становится важным фактором. В то же время первостепенное значение имеет обеспечение бесперебойного процесса совершения покупок в режиме реального времени для конечных пользователей. Наша исследовательская группа в области искусственного интеллекта и машинного обучения сосредоточена на выявлении лучших моделей компьютерного зрения (CV) для нашей системы. Теперь перед нами стояла задача: как одновременно оптимизировать операции искусственного интеллекта и машинного обучения с точки зрения производительности и затрат.
Мы развертываем наши модели на экземплярах Amazon EC2 Inf1 на базе Inferentia, первой микросхемы машинного обучения Amazon, предназначенной для ускорения рабочих нагрузок вывода при глубоком обучении. Было показано, что Inferentia значительно снижает затраты на умозаключения. Мы использовали AWS Neuron SDK — набор программных инструментов, используемых с Inferentia, — для компиляции и оптимизации наших моделей для развертывания на инстансах EC2 Inf1.
Следующий фрагмент кода показывает, как скомпилировать модель YOLO с помощью Neuron. Код прекрасно работает с PyTorch, а такие функции, как torch.jit.trace() и Neuron.trace(), записывают операции модели на примере входных данных во время прямого прохода для построения статического IR-графика.
Мы перенесли наши ресурсоемкие модели в Inf1. Используя AWS Inferentia, мы добились пропускной способности и производительности, соответствующих потребностям нашего бизнеса. Внедрение экземпляров Inf1 на базе Inferentia в жизненный цикл MLOps стало ключом к достижению замечательных результатов:
- Улучшение производительности: Наши большие модели компьютерного зрения теперь работают в пять раз быстрее, достигая более 120 кадров в секунду (FPS), что позволяет нашим клиентам совершать покупки в режиме реального времени. Более того, возможность обработки с такой частотой кадров не только увеличивает скорость транзакций, но и позволяет нам вводить больше информации в наши модели. Такое увеличение объема вводимых данных значительно повышает точность обнаружения продуктов в наших моделях, что еще больше повышает общую эффективность наших торговых систем.
- Экономия затрат: Мы сократили затраты на выводы. Это значительно улучшило архитектуру, поддерживающую наши A-POP.
Параллельный вывод данных стал проще с помощью AWS Neuron SDK
Чтобы повысить производительность наших рабочих нагрузок вывода и добиться максимальной производительности от Inferentia, мы хотели использовать все доступные нейронные ядра в ускорителе Inferentia. Достичь такой производительности было легко с помощью встроенных инструментов и API из Neuron SDK. Мы использовали torch.neuron.DataParallel() API. В настоящее время мы используем inf1.2xlarge, в котором есть один ускоритель Inferentia и четыре ускорителя Neuron. Итак, мы используем torch.neuron.DataParallel() чтобы полностью использовать оборудование Inferentia и использовать все доступные нейронные ядра. Эта функция Python реализует параллелизм данных на уровне модуля в моделях, созданных с помощью PyTorch Neuron API. Параллелизм данных — это форма распараллеливания между несколькими устройствами или ядрами (NeuronCores от Inferentia), называемыми узлами. Каждый узел содержит одну и ту же модель и параметры, но данные распределены по разным узлам. Распределяя данные по нескольким узлам, параллелизм данных сокращает общее время обработки входных данных большого размера по сравнению с последовательной обработкой. Параллелизм данных лучше всего работает для моделей в чувствительных к задержкам приложениях, которым предъявляются требования к большому размеру пакета.
Заглядывая в будущее: ускорение трансформации розничной торговли с помощью базовых моделей и масштабируемого развертывания
Заглядывая в будущее, влияние фундаментальных моделей на розничную торговлю невозможно переоценить. Модели фундамента могут существенно изменить маркировку продукции. Способность быстро и точно идентифицировать и классифицировать различные продукты имеет решающее значение в быстро меняющейся розничной среде. Благодаря современным моделям на основе трансформаторов мы можем развернуть большее разнообразие моделей для удовлетворения большего количества наших потребностей в области искусственного интеллекта и машинного обучения с более высокой точностью, улучшая удобство работы для пользователей и не тратя время и деньги на обучение моделей с нуля. Используя возможности базовых моделей, мы можем ускорить процесс маркировки, позволяя ритейлерам быстрее и эффективнее масштабировать свои решения A-POP.
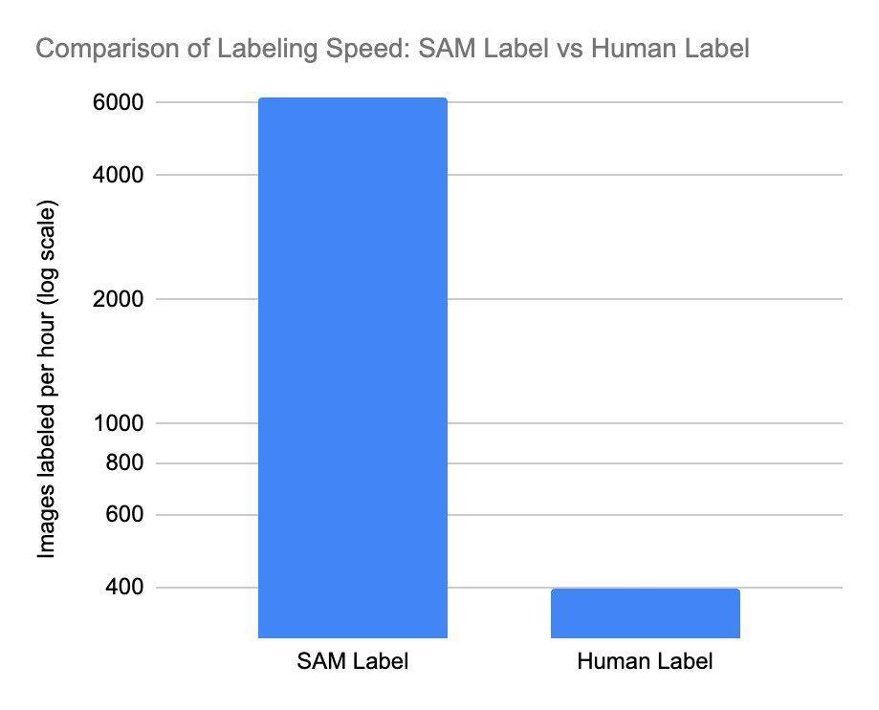
Мы начали реализацию Сегментируйте любую модель (SAM), базовую модель преобразователя зрения, которая может сегментировать любой объект на любом изображении (подробнее мы обсудим это в другом сообщении блога). SAM позволяет нам ускорить процесс маркировки с беспрецедентной скоростью. SAM очень эффективен: он способен обрабатывать примерно в 62 раза больше изображений, чем человек может вручную создать ограничивающие рамки за тот же период времени. Результаты SAM используются для обучения модели, которая обнаруживает маски сегментации в транзакциях, открывая окно возможностей для обработки миллионов изображений в геометрической прогрессии. Это значительно сокращает время и стоимость обучения моделям планограмм продуктов.
Наши исследовательские группы по продуктам и искусственному интеллекту и машинному обучению рады быть в авангарде этой трансформации. Продолжающееся партнерство с AWS и использование Inferentia в нашей инфраструктуре гарантируют, что мы сможем экономически эффективно развернуть эти базовые модели. Как первые пользователи, мы работаем с новыми экземплярами на базе AWS Inferentia 2. Экземпляры Inf2 созданы для современного генеративного искусственного интеллекта и ускорения вывода моделей больших языков (LLM), обеспечивая более высокую производительность и более низкие затраты. Inf2 позволит нам предоставить ритейлерам возможность использовать преимущества технологий, основанных на искусственном интеллекте, не тратя при этом значительные средства, что в конечном итоге сделает розничную торговлю более инновационной, эффективной и клиентоориентированной.
Продолжая мигрировать все больше моделей в Inferentia и Inferentia2, включая базовые модели на основе преобразователей, мы уверены, что наш альянс с AWS позволит нам расти и внедрять инновации вместе с нашим надежным поставщиком облачных услуг. Вместе мы изменим будущее розничной торговли, сделав ее умнее, быстрее и лучше приспособленной к постоянно меняющимся потребностям потребителей.
Заключение
В этом техническом обзоре мы рассказали о нашем пути трансформации с использованием AWS Inferentia для инновационной системы обработки транзакций AI/ML. Это партнерство привело к пятикратному увеличению скорости обработки и ошеломляющему снижению затрат на логические выводы на 95 процентов по сравнению с нашим предыдущим решением. Он изменил нынешний подход к розничной торговле, упрощая процесс совершения покупок в режиме реального времени.
Если вы хотите узнать больше о том, как Inferentia может помочь вам сэкономить затраты и одновременно оптимизировать производительность ваших приложений вывода, посетите страницы продуктов с инстансами Amazon EC2 Inf1 и инстансами Amazon EC2 Inf2. AWS предоставляет различные примеры кода и ресурсы для начала работы с Neuron SDK, которые вы можете найти на странице Хранилище образцов нейронов.
Об авторах
Матиас Пончон является руководителем отдела инфраструктуры в Intuitivo. Он специализируется на разработке безопасных и надежных приложений. Обширный опыт работы в компаниях FinTech и Blockchain в сочетании со стратегическим мышлением помогает ему разрабатывать инновационные решения. У него есть глубокая приверженность к совершенству, поэтому он постоянно предлагает надежные решения, раздвигающие границы возможного.
Хосе Бенитес — основатель и директор подразделения искусственного интеллекта в Intuitivo, специализирующийся на разработке и внедрении приложений компьютерного зрения. Он возглавляет талантливую команду машинного обучения, создавая среду инноваций, творчества и передовых технологий. В 2022 году Хосе был признан «Новатором до 35 лет» по версии журнала MIT Technology Review, что является свидетельством его новаторского вклада в эту область. Эта преданность делу выходит за рамки похвал и проявляется в каждом проекте, за который он берется, демонстрируя неустанную приверженность совершенству и инновациям.
Дивакар Бансал — старший специалист AWS, занимающийся развитием бизнеса и выводом на рынок услуг ускоренных вычислений на базе искусственного интеллекта и машинного обучения. Ранее Дивакар руководил определением продуктов, развитием глобального бизнеса и маркетингом технологических продуктов для Интернета вещей, периферийных вычислений и автономного вождения, уделяя особое внимание внедрению искусственного интеллекта и машинного обучения в эти области.