
Андре Хе, Вивек Майерс
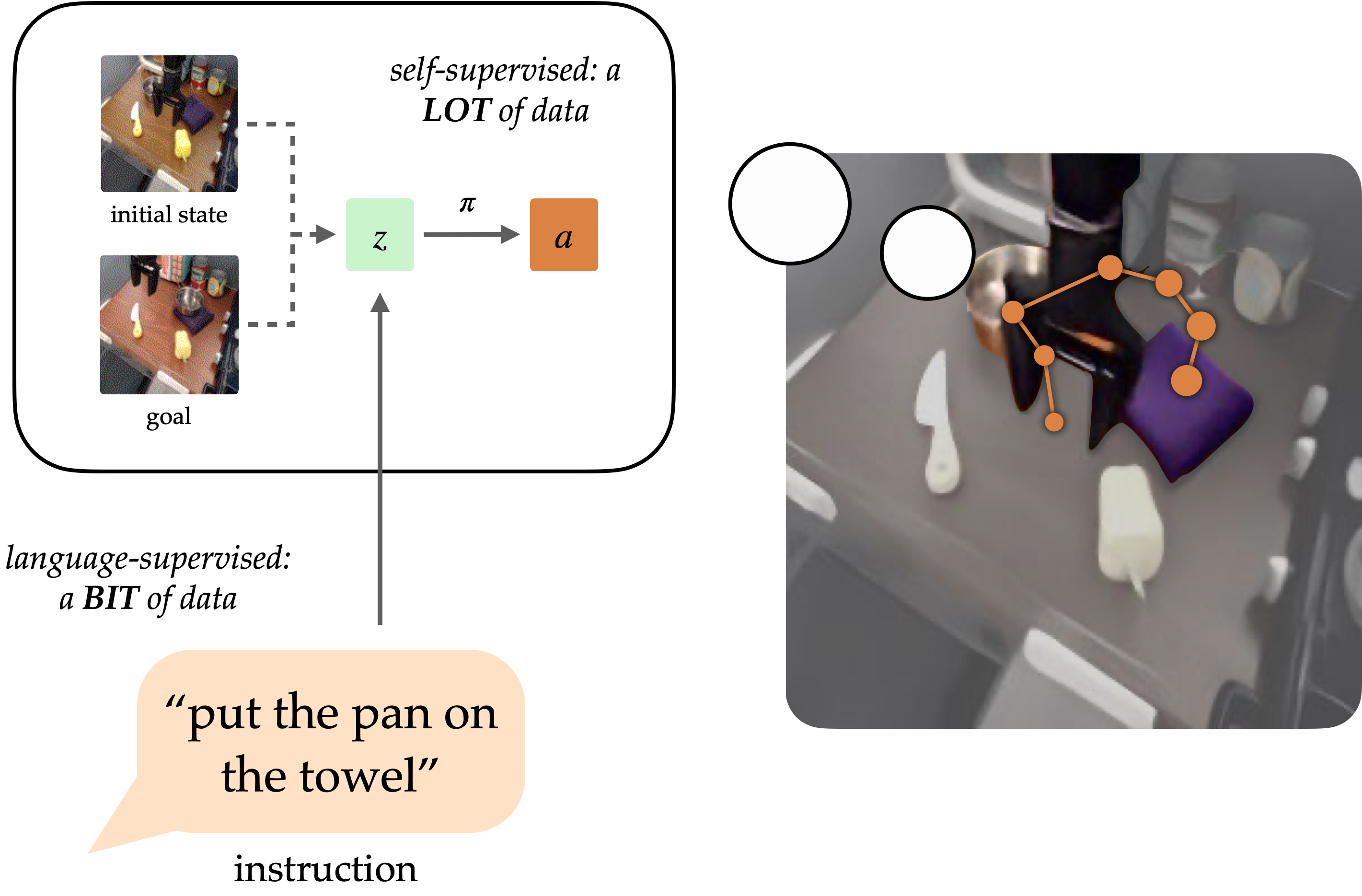
Давней целью в области обучения роботов было создание универсальных агентов, способных выполнять задачи за людей. Естественный язык потенциально может стать для людей простым в использовании интерфейсом для постановки произвольных задач, но роботов сложно научить следовать языковым инструкциям. Такие подходы, как поведенческое клонирование с учетом языка (LCBC), обучают политике прямой имитации действий экспертов, обусловленных языком, но требуют от людей аннотировать все траектории обучения и плохо обобщать различные сцены и поведение. Между тем, недавние целеусловные подходы гораздо лучше справляются с общими задачами манипулирования, но не позволяют легко определять задачи для людей-операторов. Как мы можем совместить простоту постановки задач с помощью подходов, подобных LCBC, с повышением производительности целенаправленного обучения?
Концептуально робот, следующий инструкциям, требует двух способностей. Ему необходимо обосновать языковую инструкцию в физической среде, а затем иметь возможность выполнить последовательность действий для выполнения намеченной задачи. Этим возможностям не обязательно изучать сквозное изучение только траекторий, аннотированных человеком, их можно изучить отдельно от соответствующих источников данных. Данные о визуальном языке из источников, не связанных с роботами, могут помочь в изучении языка с обобщением на разнообразные инструкции и визуальные сцены. Между тем, немаркированные траектории робота можно использовать для обучения робота достижению определенных целевых состояний, даже если они не связаны с языковыми инструкциями.
Обусловленность визуальными целями (т.е. образами целей) обеспечивает дополнительные преимущества для изучения политики. Цели как форму спецификации задачи желательно масштабировать, поскольку их можно свободно генерировать, переименовывая задним числом (любое состояние, достигнутое на траектории, может быть целью). Это позволяет обучать политикам посредством целевого поведенческого клонирования (GCBC) на больших объемах неаннотированных и неструктурированных данных о траекториях, включая данные, собранные автономно самим роботом. Цели также легче обосновать, поскольку, как изображения, их можно напрямую сравнивать попиксельно с другими состояниями.
Однако цели менее интуитивны для пользователей, чем естественный язык. В большинстве случаев пользователю проще описать задачу, которую он хочет выполнить, чем предоставить целевое изображение, которое, вероятно, в любом случае потребует выполнения задачи для создания изображения. Предоставляя языковой интерфейс для политик, обусловленных целями, мы можем объединить сильные стороны спецификации целей и языковых задач, чтобы создать универсальных роботов, которыми можно легко управлять. Наш метод, обсуждаемый ниже, предоставляет такой интерфейс для обобщения различных инструкций и сцен с использованием данных на языке видения и улучшения физических навыков за счет обработки больших неструктурированных наборов данных роботов.
Представления целей для выполнения инструкций
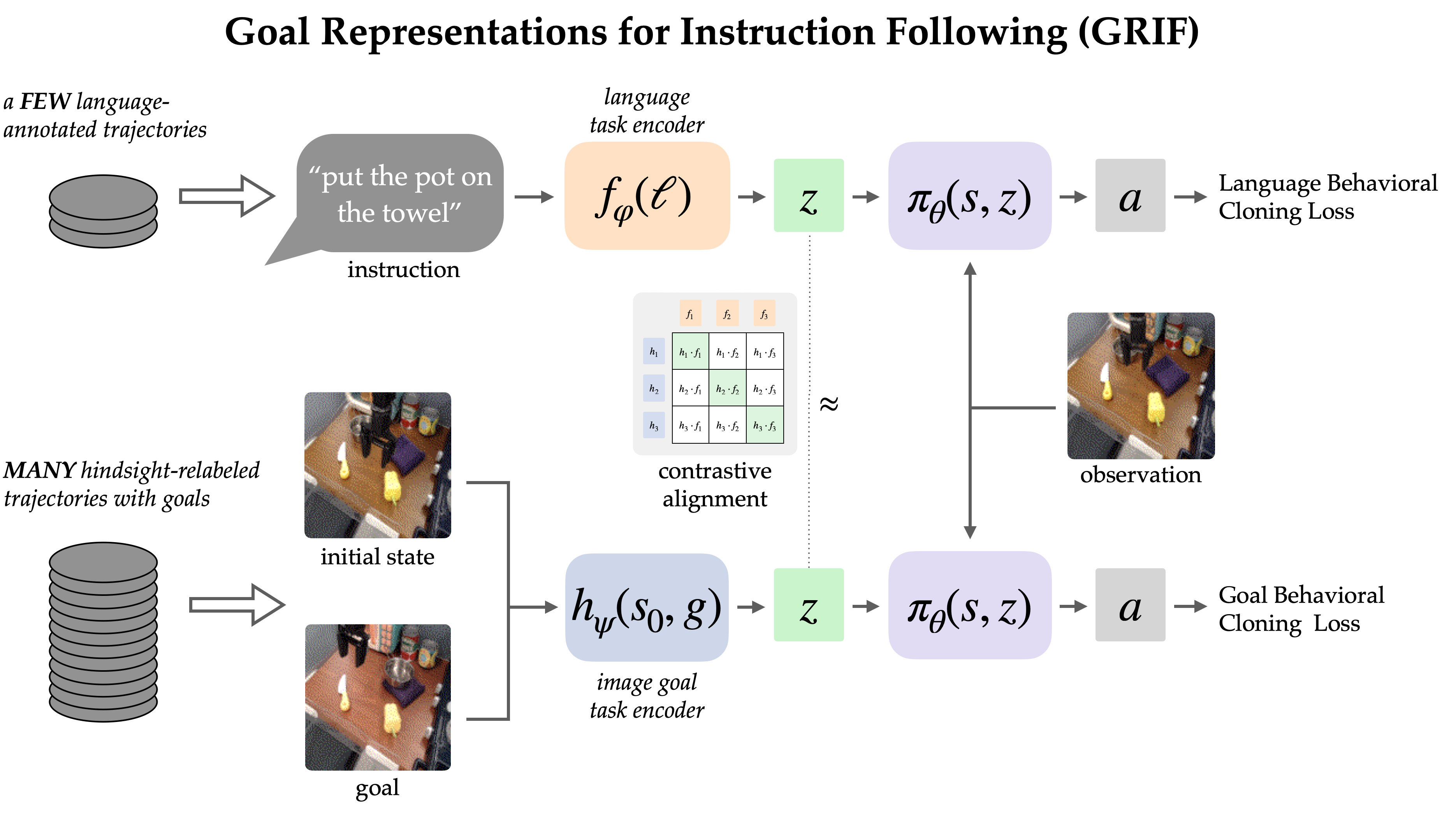
Модель GRIF состоит из языкового кодировщика, кодировщика целей и сети политики. Кодировщики соответственно отображают языковые инструкции и изображения целей в общее пространство представления задач, что обуславливает работу сети политик при прогнозировании действий. Модель может быть эффективно обусловлена либо языковыми инструкциями, либо целевыми изображениями для прогнозирования действий, но мы в первую очередь используем целевое обучение как способ улучшения варианта использования, обусловленного языком.
Наш подход, Представление целей для следования инструкциям (GRIF), совместно тренирует языковую и целевую политику с согласованным представлением задач. Наше ключевое понимание состоит в том, что эти представления, согласованные с языком и модальностями целей, позволяют нам эффективно сочетать преимущества целенаправленного обучения с языково-обусловленной политикой. Изученные политики затем можно обобщать по языку и сценам после обучения, в основном, на неразмеченных демонстрационных данных.
Мы обучили GRIF на версии Набор данных Bridge-v2 содержащий 7 тысяч помеченных демонстрационных траекторий и 47 тысяч немаркированных траекторий в условиях кухонных манипуляций. Поскольку все траектории в этом наборе данных должны были быть аннотированы людьми вручную, возможность напрямую использовать 47 тыс. траекторий без аннотаций значительно повышает эффективность.
Чтобы учиться на обоих типах данных, GRIF обучается совместно с поведенческим клонированием, обусловленным языком (LCBC) и поведенческим клонированием, обусловленным целью (GCBC). Размеченный набор данных содержит как языковые, так и целевые спецификации задач, поэтому мы используем его для контроля как прогнозов, обусловленных языком, так и целей (т. е. LCBC и GCBC). Немаркированный набор данных содержит только цели и используется для GCBC. Разница между LCBC и GCBC заключается лишь в выборе представления задачи из соответствующего кодировщика, которое передается в общую сеть политик для прогнозирования действий.
Поделившись сетью политики, мы можем ожидать некоторых улучшений от использования немаркированного набора данных для целенаправленного обучения. Однако GRIF обеспечивает гораздо более сильный переход между двумя модальностями, поскольку признает, что некоторые языковые инструкции и образы целей определяют одно и то же поведение. В частности, мы используем эту структуру, требуя, чтобы языковые представления и представления целей были схожими для одной и той же семантической задачи. Если предположить, что эта структура сохраняется, немаркированные данные также могут принести пользу политике, обусловленной языком, поскольку представление цели приближается к представлению отсутствующей инструкции.
Согласование посредством контрастного обучения
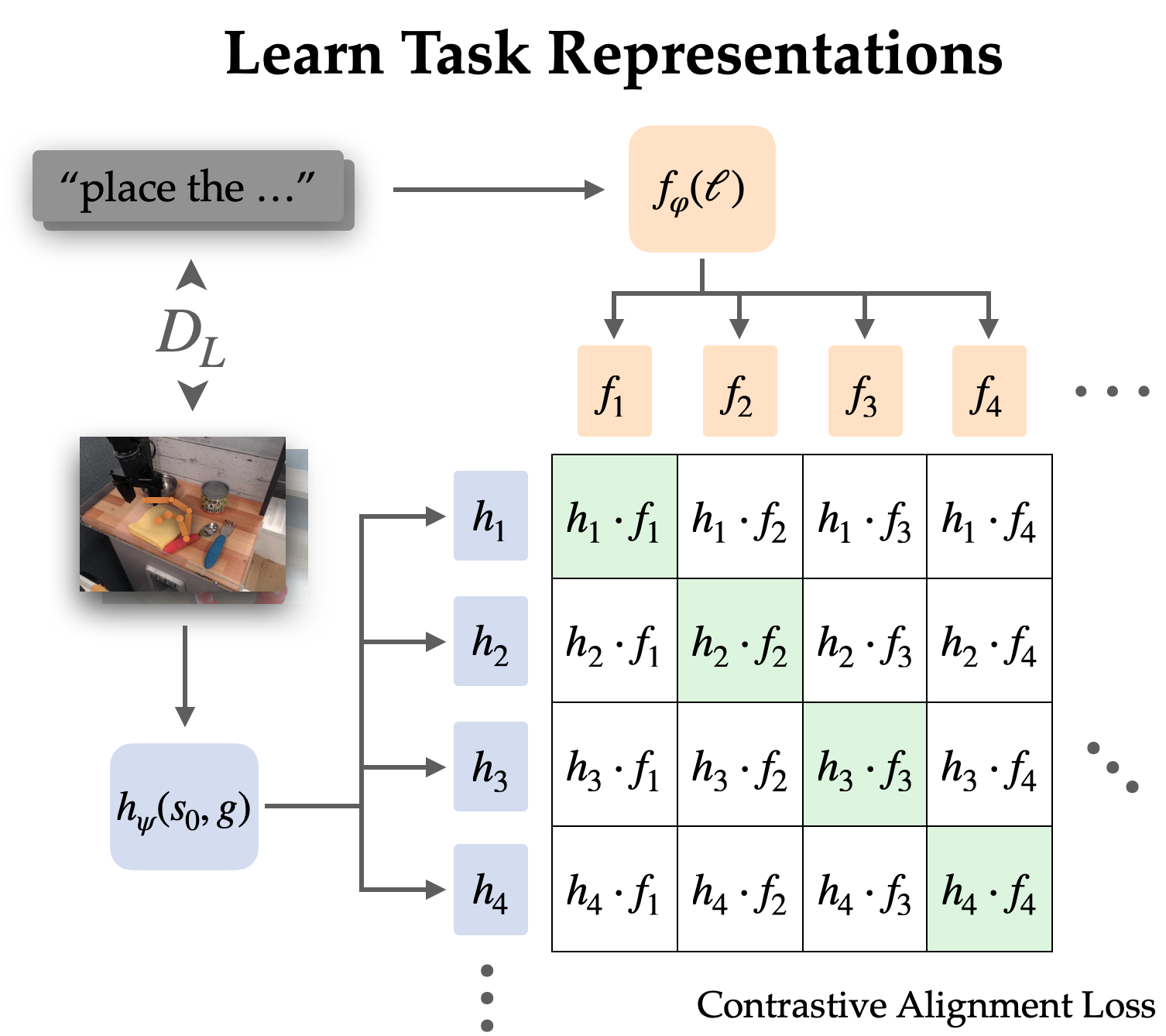
Мы явно согласовываем представления между задачами, обусловленными целью и языком, в помеченном наборе данных посредством контрастного обучения.
Поскольку язык часто описывает относительные изменения, мы предпочитаем согласовывать представления пар состояние-цель с языковой инструкцией (в отличие от просто цели с языком). Эмпирически это также облегчает изучение представлений, поскольку они могут опустить большую часть информации в изображениях и сосредоточиться на переходе от состояния к цели.
Мы изучаем эту структуру выравнивания с помощью цели infoNCE по инструкциям и изображениям из размеченного набора данных. Мы обучаем двойных кодировщиков изображений и текста, проводя контрастное обучение на сопоставлении пар языковых и целевых представлений. Цель поощряет высокое сходство между представлениями одной и той же задачи и низкое сходство для других, когда отрицательные примеры выбираются из других траекторий.
При использовании наивной отрицательной выборки (единой от остального набора данных) изученные представления часто игнорировали реальную задачу и просто согласовывали инструкции и цели, относящиеся к одним и тем же сценам. Чтобы использовать политику в реальном мире, не очень полезно связывать язык со сценой; скорее нам это нужно, чтобы устранить неоднозначность между различными задачами в одной сцене. Таким образом, мы используем стратегию жесткой негативной выборки, при которой до половины негативов отбирается с разных траекторий в одной и той же сцене.
Естественно, эта контрастная система обучения дразнит предварительно обученные модели языка видения, такие как CLIP. Они демонстрируют эффективные возможности обобщения с нулевым и малым количеством шагов для задач, связанных с визуальным языком, и предлагают способ объединить знания, полученные в результате предварительного обучения в масштабе Интернета. Однако большинство моделей языка видения предназначены для согласования одного статического изображения с его подписью без возможности понять изменения в окружающей среде, и они плохо работают, когда приходится обращать внимание на один объект в загроможденных сценах.
Чтобы решить эти проблемы, мы разработали механизм размещения и точной настройки CLIP для согласования представлений задач. Мы модифицируем архитектуру CLIP, чтобы она могла работать с парой изображений, объединенных с ранним слиянием (наложением по каналам). Это оказывается подходящей инициализацией для кодирования пар изображений состояния и цели, которая особенно хороша для сохранения преимуществ предварительного обучения от CLIP.
Результаты политики роботов
Для нашего основного результата мы оцениваем политику GRIF в реальном мире по 15 задачам в 3 сценах. Инструкции выбираются как смесь тех, которые хорошо представлены в обучающих данных, и новых, требующих некоторой степени композиционного обобщения. В одной из сцен также присутствует невидимая комбинация объектов.
Мы сравниваем GRIF с простым LCBC и более строгими базовыми показателями, вдохновленными предыдущими работами, такими как ЛангЛфП и БК-З. LLfP соответствует совместному обучению с LCBC и GCBC. BC-Z — это адаптация одноименного метода к нашим условиям, где мы тренируемся на LCBC, GCBC и простом термине выравнивания. Он оптимизирует потерю косинусного расстояния между представлениями задач и не использует предварительное обучение языка изображений.
Эта политика была подвержена двум основным видам сбоев. Они могут не понимать языковую инструкцию, в результате чего они пытаются выполнить другое задание или вообще не выполняют никаких полезных действий. Если языковая основа не является надежной, политики могут даже запустить непреднамеренную задачу после выполнения правильной задачи, поскольку исходная инструкция находится вне контекста.
Примеры неисправностей заземления

«положи гриб в металлический горшок»

«положи ложку на полотенце»

«положи желтый перец на ткань»

«положи желтый перец на ткань»
Другой вид отказа — неспособность манипулировать объектами. Это может быть связано с отсутствием захвата, неточным движением или выпуском предметов в неподходящее время. Мы отмечаем, что это не недостатки, присущие настройке робота, поскольку политика GCBC, обученная на всем наборе данных, может последовательно преуспевать в манипуляциях. Скорее, этот режим сбоя обычно указывает на неэффективность использования целевых данных.
Примеры неудачных манипуляций

«перемести болгарский перец налево от стола»

«положи болгарский перец в кастрюлю»

«подвинь полотенце рядом с микроволновой печью»
Сравнивая исходные показатели, можно сказать, что каждый из них в разной степени пострадал от этих двух режимов сбоя. LCBC полагается исключительно на небольшой набор данных помеченных траекторий, и его плохие возможности манипулирования не позволяют ему выполнять какие-либо задачи. LLfP совместно обучает политике использования маркированных и немаркированных данных и демонстрирует значительно улучшенные возможности манипулирования по сравнению с LCBC. Он обеспечивает разумные показатели успеха для обычных инструкций, но не может обосновать более сложные инструкции. Стратегия согласования BC-Z также улучшает возможности манипулирования, вероятно, потому, что согласование улучшает передачу между модальностями. Однако без внешних источников данных на языке видения ему все еще сложно обобщить новые инструкции.
GRIF демонстрирует лучшее обобщение, а также обладает сильными возможностями манипулирования. Он способен обосновать языковые инструкции и выполнить задачу, даже если в сцене возможно множество различных задач. Ниже мы покажем некоторые варианты внедрения и соответствующие инструкции.
Внедрение политики от GRIF

«переместить кастрюлю вперед»

«положи болгарский перец в кастрюлю»

«положи нож на фиолетовую ткань»

«положи ложку на полотенце»
Заключение
GRIF позволяет роботу использовать большие объемы немаркированных данных о траекториях для изучения политик, обусловленных целями, обеспечивая при этом «языковой интерфейс» для этих политик через согласованные представления задач на языке и цели. В отличие от предыдущих методов выравнивания языка и изображения, наши представления согласовывают изменения состояния с языком, что, как мы показываем, приводит к значительным улучшениям по сравнению со стандартными целями выравнивания изображения и языка в стиле CLIP. Наши эксперименты показывают, что наш подход может эффективно использовать немаркированные роботизированные траектории, обеспечивая значительное улучшение производительности по сравнению с базовыми показателями и методами, которые используют только данные с языковыми аннотациями.
Наш метод имеет ряд ограничений, которые могут быть устранены в будущих работах. GRIF не очень хорошо подходит для задач, в которых инструкции говорят больше о том, как выполнить задачу, чем о том, что делать (например, «медленно наливайте воду») — такие качественные инструкции могут потребовать других типов потерь выравнивания, которые учитывают промежуточные этапы задачи. исполнение. GRIF также предполагает, что вся языковая подготовка исходит из той части нашего набора данных, которая полностью аннотирована, или предварительно обученного VLM. Захватывающим направлением будущей работы было бы расширить нашу потерю выравнивания, чтобы использовать видеоданные человека для изучения богатой семантики из данных в масштабе Интернета. Такой подход может затем использовать эти данные для улучшения изучения языка за пределами набора данных роботов и обеспечения широко обобщаемых политик роботов, которые могут следовать инструкциям пользователя.
Этот пост основан на следующей статье:

BAIR Blog — официальный блог Лаборатории исследований искусственного интеллекта Беркли (BAIR).
BAIR Blog — официальный блог Лаборатории исследований искусственного интеллекта Беркли (BAIR).