
На быстро растущем рынке искусственного интеллекта (ИИ) и генеративного ИИ (рис. 1) центральное место занял один термин — «большие языковые модели», или LLM. Эти огромные модели позволяют машинам создавать контент так же, как люди. Данные играют основополагающую роль в формировании поведения, опыта и диапазона этих моделей. Но как получить доступ к этим данным, особенно с учетом возникающих проблем?
В этой статье представлено подробное руководство по данным LLM, помогает руководителям бизнеса решить, какой метод сбора выбрать, а также представлены некоторые варианты услуг по сбору данных с помощью ИИ.
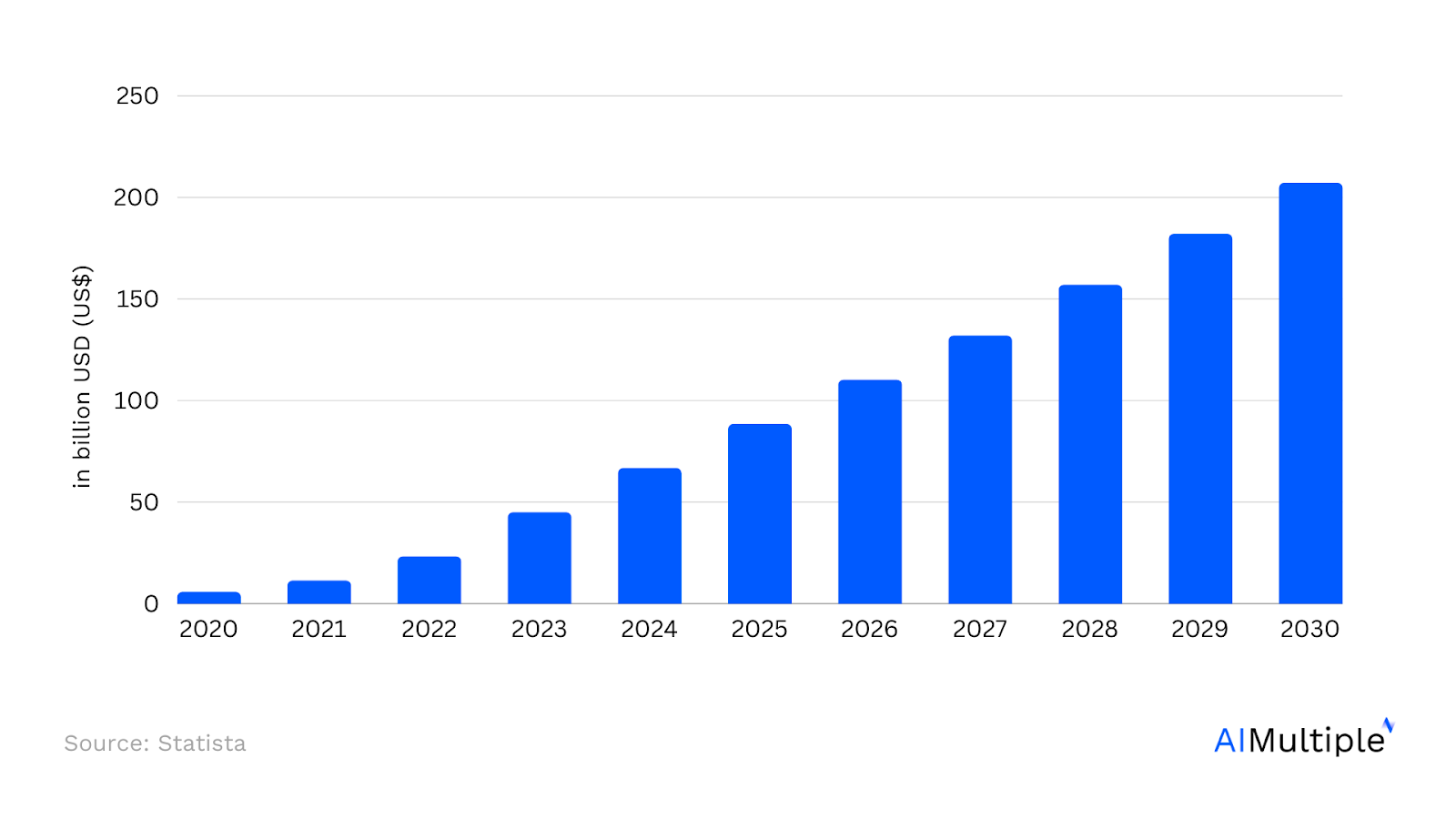
Рисунок 1. Рынок генеративного искусственного интеллекта1
Что такое большие языковые модели?
Модели большого языка, или LLM, представляют собой подмножество искусственного интеллекта, относящееся к области обработки естественного языка (NLP).
Эти модели искусственного интеллекта предназначены для понимания и выдачи человеческих ответов на нескольких языках, достигая этого за счет огромных наборов данных и методов глубокого обучения.
Некоторые из наиболее популярных моделей большого языка включают генеративные предварительно обученные преобразователи (серия GPT) и представления двунаправленного кодировщика (BERT).
Как LLM влияет на технологическую отрасль?
LLM совершает революцию в различных секторах:
- Разговорный ИИ: Большие языковые модели лежат в основе многих чат-ботов службы поддержки клиентов. Они предназначены для понимания вводимых пользователем данных и обеспечения взаимодействия, подобного человеческому, что делает автоматизированную поддержку клиентов более эффективной и удобной для пользователя.
- Языковой перевод: Магистр права произвел революцию в нашем подходе к языковому переводу. Будь то перевод повседневных разговоров или сложных юридических документов, эти модели обеспечивают быстрый и точный перевод, помогая преодолеть языковые барьеры и способствовать глобальному общению.
- Программирование: Некоторые продвинутые программы LLM могут помочь в генерации кода. Это не только упрощает процесс кодирования, но и позволяет бизнес-пользователям, которые могут не обладать глубокими техническими знаниями, участвовать в разработке программного обеспечения.
- Научное исследование: Магистр права играет важную роль в мире науки, помогая исследователям. Они могут перевести сложный научный жаргон на более понятные термины и предоставить ценную информацию, помогая интерпретировать данные и ускоряя исследовательский процесс.
Важность данных для LLM
Чтобы производительность большой языковой модели была первоклассной, она в значительной степени зависит от данных обучения. Эти данные помогают:
- Понимание сложных предложений: Контекст имеет жизненно важное значение, и наличие огромных объемов разнообразных данных позволяет специалистам LLM понимать сложные структуры.
- Анализ настроений: Для оценки настроений клиентов или интерпретации тона текста требуется широкий спектр примеров.
- Конкретные задачи: Будь то перевод языков или классификация текста, специализированные данные помогают точно настроить модели для конкретных задач.
Однако получить эти данные не всегда просто. В условиях растущей обеспокоенности по поводу конфиденциальности, интеллектуальной собственности и этических соображений получение высококачественных и разнообразных наборов данных становится все более сложной задачей.
Как мы собираем данные для LLM?
В этом разделе освещаются некоторые популярные методы получения соответствующих данных для разработки больших языковых моделей.
1. Краудсорсинг
Платформа краудсорсинга данных является одним из лучших источников для сбора данных LLM. Использование обширной глобальной сети людей для накопления или маркировки данных. Этот метод привлекает людей из разных слоев общества и географического положения для сбора уникальных и разнообразных данных.
Преимущества:
- Доступ к разнообразному и обширному спектру точек данных. Поскольку участники находятся по всему миру, набор данных гораздо более разнообразен.
- Часто более рентабельно, чем традиционные методы сбора данных, поскольку не требует дополнительных затрат.
- Ускоряет сбор данных благодаря одновременному получению данных из нескольких источников.
Проблемы:
- Обеспечение качества может быть затруднено при работе с разными участниками, поскольку вы не можете физически контролировать работу.
- Этические соображения, особенно в отношении справедливой компенсации. Многие компании, такие как Amazon Mechanical Turk, были оштрафованы за несправедливую практику компенсации на своих краудсорсинговых платформах.
Некоторые популярные на рынке услуги краудсорсинга данных
Вот наши лучшие выборы:
Clickworker — это краудсорсинговая платформа, предлагающая все виды услуг по обработке данных с использованием искусственного интеллекта. Его глобальная сеть, насчитывающая более 4,5 миллионов сотрудников, предлагает созданные человеком наборы данных для различных вариантов использования, включая разработку LLM.
Appen также является популярной краудсорсинговой платформой, предлагающей услуги по обработке данных, созданных искусственным интеллектом. Сеть компании насчитывает более 1 миллиона сотрудников. Прочтите эти статьи, чтобы узнать больше об Appen:
2. Автоматизированные средства
Использование методов автоматического сбора данных, таких как веб-скребки, можно использовать для извлечения огромных объемов текстовых данных с открытым исходным кодом с веб-сайтов, форумов, блогов и других онлайн-источников.
Например, организация, работающая над улучшением агрегатора новостей на базе искусственного интеллекта, может использовать инструменты веб-скрапинга для сопоставления статей, заголовков и фрагментов новостей из глобальных источников, чтобы понять различные стили и форматы письма.
Преимущества:
- Доступ к практически безграничному пулу данных по бесчисленным темам.
- Постоянные обновления в связи с постоянно развивающейся природой Интернета.
- Гораздо быстрее и дешевле по сравнению с другими способами сбора языковых данных.
Проблемы:
- Обеспечение актуальности данных и фильтрация шума может занять много времени.
- Навигация по правам и разрешениям интеллектуальной собственности может быть сложной и дорогостоящей, поскольку многие онлайн-платформы теперь взимают с компаний плату за сбор их данных. Если разработчики выполняют парсинг без разрешения, им грозят судебные иски.
Посмотрите это видео, чтобы узнать, как на OpenAI подали в суд за кражу данных популярных авторов:
3. Партнерство с сервисами
Формирование сотрудничества с академическими учреждениями, исследовательскими организациями или корпорациями для получения собственных наборов данных.
Например, фирма, специализирующаяся на юридических инструментах искусственного интеллекта, может сотрудничать с юридическими школами и юридическими учреждениями, чтобы получить доступ к обширной библиотеке юридических документов, тематических исследований и научных статей.
Преимущества:
- Получение специализированных, тщательно подобранных наборов данных.
- Взаимная выгода: пока компания, занимающаяся искусственным интеллектом, получает данные, учреждение может получать передовые инструменты искусственного интеллекта, помощь в исследованиях или даже финансовую компенсацию.
- Данные являются законными и не подлежат судебным искам.
Проблемы:
- Установление и поддержание доверительных партнерских отношений может оказаться сложной задачей, поскольку разные организации имеют разные программы и приоритеты.
- Балансирование обмена данными с протоколами конфиденциальности и этическими соображениями также может быть сложной задачей, поскольку не все организации доверяют свои данные другим.
4. Синтетические данные
Вы также можете использовать модели искусственного интеллекта или симуляцию для создания синтетических, но реалистичных наборов данных.
Например, если виртуальному чат-боту-помощнику по покупкам не хватает реального взаимодействия с клиентами. Он может использовать ИИ для моделирования запросов потенциальных клиентов, обратной связи и транзакционных разговоров.
Преимущества:
- Быстрое создание обширных наборов данных, адаптированных к конкретным потребностям.
- Снижение зависимости от сбора реальных данных, который может занять много времени или ресурсов.
Проблемы:
- Обеспечение того, чтобы синтетические данные точно отражали реальные сценарии, может быть сложной задачей, поскольку даже современные мощные модели искусственного интеллекта иногда не могут предоставить точные данные.
- Синтетические данные не могут работать сами по себе. Вам по-прежнему потребуются данные, созданные человеком, для добавления к синтетическим данным.
Вот статья, в которой сравниваются лучшие решения для синтетических данных на рынке.
5. Покупка и лицензирование
Непосредственная покупка наборов данных или получение лицензий на их использование в учебных целях. Онлайн-платформы и другие форумы теперь продают свои данные. Например, Reddit недавно начал взимать плату с разработчиков ИИ за доступ к своим пользовательским данным.2.
Преимущества:
- Немедленный доступ к большим, часто хорошо структурированным наборам данных.
- Ясность в отношении прав и разрешений на использование.
Проблемы:
- Может оказаться дорогостоящим, особенно для нишевых или высококачественных наборов данных.
- Потенциальные ограничения на использование, изменение или совместное использование данных на основании лицензионных соглашений.
Рекомендации
Поскольку каждый метод предлагает свои уникальные преимущества и проблемы, компании, занимающиеся искусственным интеллектом, и исследователи должны взвесить свои потребности, ресурсы и цели, чтобы определить наиболее эффективные стратегии получения данных LLM. Поскольку спрос на более сложные программы LLM продолжает расти, будут расти и инновации в сборе критически важных данных, которые лежат в их основе.
дальнейшее чтение
Если вам нужна помощь в поиске поставщика или у вас есть вопросы, свяжитесь с нами:
Найдите подходящих поставщиков
Внешние ресурсы
- Статистика рынка. (2023). Генеративный ИИ – по всему миру. Статистика. Доступ: 9 октября 2023 г.
- Николас, Гордон. (2023). Reddit будет взимать плату с компаний и организаций за доступ к своим данным, а генеральный директор обвиняет ИИ. Удача. Доступ: 9 октября 2023 г.