
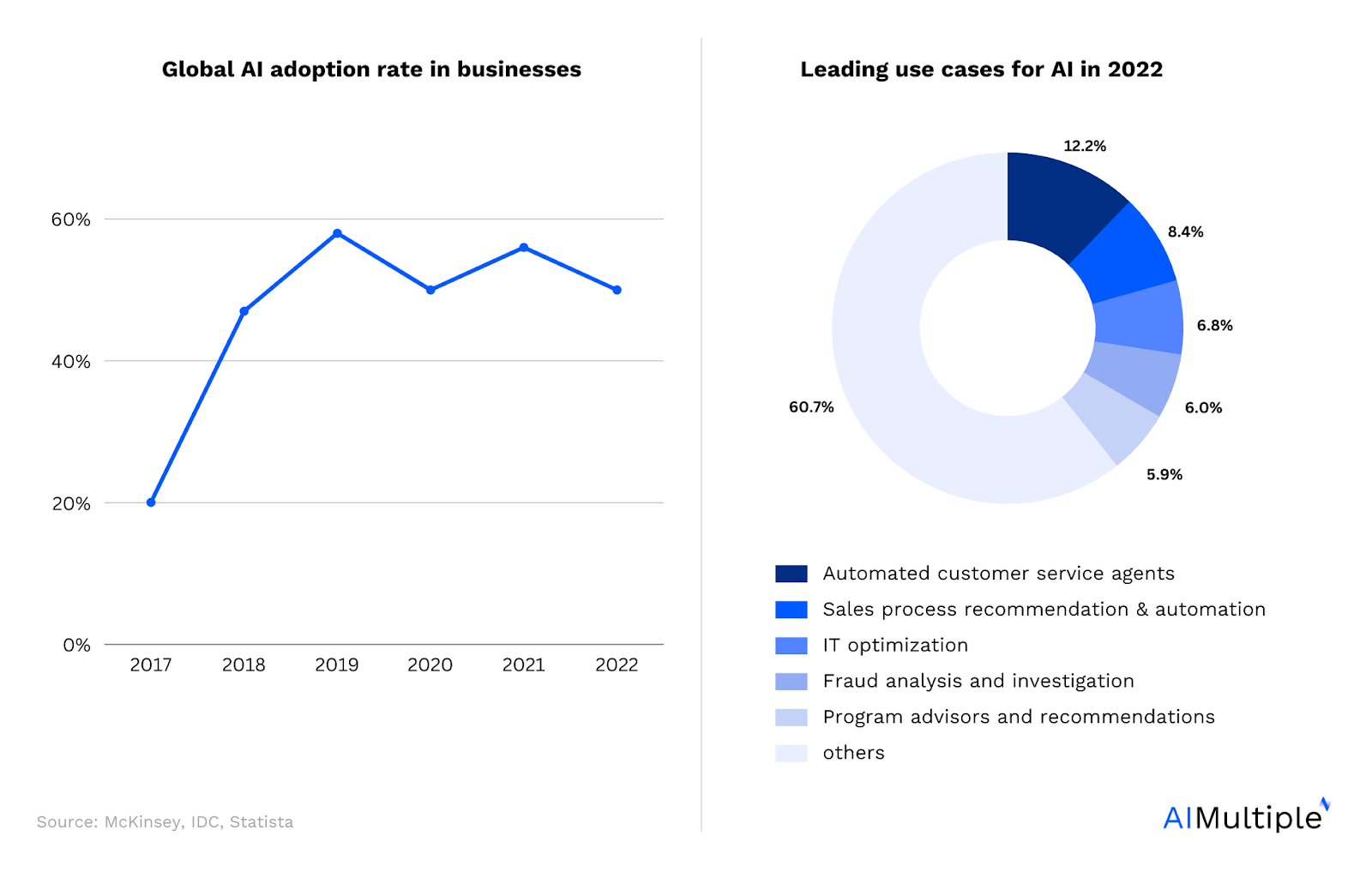
Искусственный интеллект (ИИ) стал неотъемлемой частью успеха в бизнесе, и его влияние только возрастает (рис. 1). От прогностических моделей, которые помогают в медицинской диагностике, до систем обработки естественного языка (NLP), таких как чат-боты и личные помощники, приложения ИИ безграничны. Хотя ИИ имеет огромный бизнес-потенциал, 70%1 проектов искусственного интеллекта потерпят неудачу, и руководители ищут способы обеспечить успех своих проектов.
В этом руководстве мы рассмотрим 7 основных шагов, связанных с созданием собственного решения ИИ для руководителей бизнеса, планирующих инициировать проекты ИИ.
Рисунок 1. Глобальное внедрение ИИ2
1. Определение целей и требований
Этот этап подпадает под процесс планирования.
1.1. Определите объем
Прежде чем углубляться в алгоритмы машинного обучения и нейронные сети, вы должны сначала определить, чего вы стремитесь достичь с помощью своей системы искусственного интеллекта. Будь то улучшение обслуживания клиентов с помощью чат-бота или анализ неструктурированных данных для исследования рынка, четко определите свои цели.
Вы можете использовать эту обширную библиотеку, содержащую более 100 вариантов использования и приложений ИИ, чтобы узнать, где можно внедрить ИИ в вашем бизнесе:
1.2. Распределение ресурсов
В зависимости от сложности проекта вам понадобится различное количество ресурсов. Это касается не только вычислительных ресурсов, но и человеческих ресурсов, таких как специалисты по обработке данных и разработчики искусственного интеллекта. Предварительное планирование обеспечивает плавное развитие в будущем.
2. Сбор данных
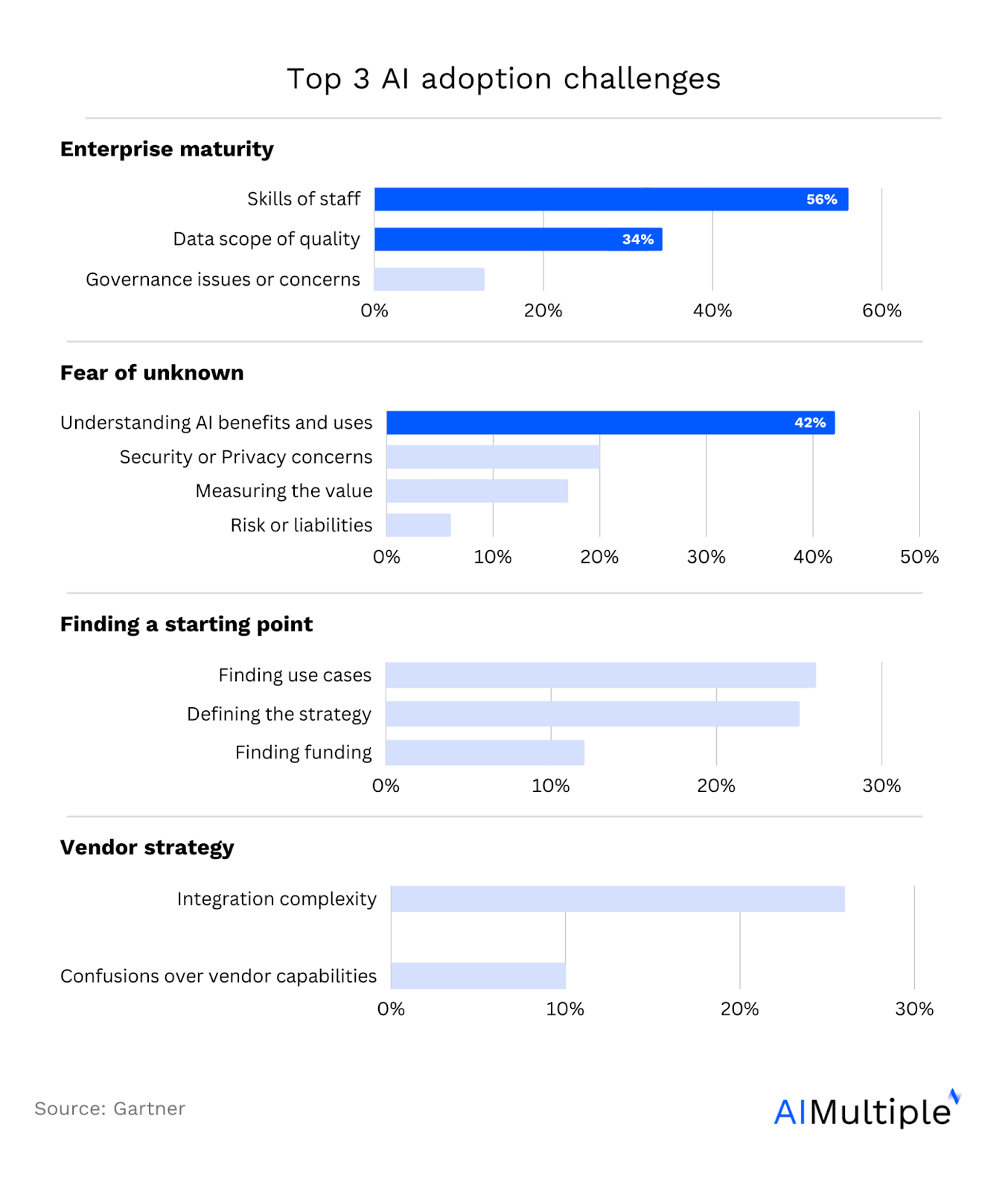
Сбор обучающих данных — один из наиболее важных этапов разработки модели ИИ, поскольку данные служат топливом для модели машинного обучения. Исследования показывают, что получение актуальных и высококачественных данных является одним из самых больших препятствий на пути внедрения ИИ (рис. 3).
Рисунок 3. Три основных препятствия на пути внедрения ИИ3
2.1. Понимание типов данных
Обучающие данные являются основой любой системы машинного обучения. Обычно вы имеете дело с двумя типами данных:
- Структурированные данные: Организованные данные, такие как базы данных и таблицы Excel.
- Неструктурированные данные: Текст, изображения, аудио, видео или любые другие данные, которые не организованы заранее определенным образом.
2.2. Источники данных
В зависимости от вашего приложения ИИ соответствующие данные могут поступать из различных источников, таких как использование предварительно упакованных данных, создание или сбор собственных данных, использование краудсорсинга и автоматизация процесса сбора данных с помощью инструментов очистки веб-страниц.
Вы можете использовать следующие методы сбора данных:

Спонсор
Clickworker предлагает созданные человеком наборы обучающих данных для моделей ИИ по модели краудсорсинга. Ее глобальная сеть, насчитывающая более 4,5 миллионов сотрудников, предлагает масштабируемые услуги передачи данных и RLHF 4 из 5 технологических гигантов США. Clickworker также предлагает:
- Аннотация данных
- RLHF (Обучение с подкреплением на основе отзывов людей)
Вы также можете просмотреть это руководство, чтобы найти подходящую службу сбора данных для вашего проекта.
3. Подготовка данных и манипулирование ими
Этот этап наступает после сбора данных. Обычно это предполагает приведение набора данных в большее соответствие с масштабом проекта ИИ.
3.1. Качество и очистка данных
Данные низкого качества могут снизить производительность модели. Следовательно, очистка данных, которая включает в себя удаление или исправление ошибочных данных, является важным шагом в этом процессе. Этот этап обычно включает предварительную обработку данных, которая предполагает обеспечение качества данных во время их сбора.
3.2. Преобразование необработанных данных
Другими словами, этот этап называется постобработкой обучающих данных. Это предполагает преобразование необработанных данных в формат, подходящий для моделей машинного обучения. Вот тут-то и пригодятся методы манипулирования данными. Ученые, работающие с данными, обычно используют инструменты анализа данных для преобразования необработанных данных в соответствующие функции.
3.3. Выбор функции
Это включает в себя определение наиболее важных переменных или функций, которые помогут алгоритмам ИИ в распознавании образов или других задачах.
3.4. Аннотация данных
На этом этапе вам также может потребоваться использовать аннотацию данных, чтобы сделать данные машиночитаемыми. Вы можете использовать инструменты аннотирования данных или обратиться к поставщику услуг данных, который предлагает услуги аннотирования данных.
Сбор данных для разработки моделей ИИ может оказаться трудоемким и ресурсоемким процессом; вот иллюстрация, упрощающая весь процесс:
Рисунок 3. Процесс сбора и создания надежных наборов данных для обучения ИИ.

Прочтите эту статью, чтобы узнать больше об этих 6 шагах по сбору соответствующих данных для обучения ИИ.
4. Выбор и разработка модели.
4.1. Выбор правильных алгоритмов
Машинное обучение предлагает богатый набор алгоритмов, предназначенных для решения различных задач. С одной стороны, у вас есть алгоритмы глубокого обучения, хорошо подходящие для сложных функций, таких как распознавание изображений и речи. Эти алгоритмы, часто основанные на нейронных сетях, превосходно справляются с распознаванием образов и могут эффективно обрабатывать неструктурированные данные. Модели глубокого обучения особенно популярны в проектах искусственного интеллекта, связанных с CV (компьютерным зрением) и НЛП (обработкой естественного языка).
Выбор правильного алгоритма зависит от множества факторов, таких как:
- Тип задачи: Это классификация, регрессия или кластеризация?
- Качество и количество данных: У вас есть большой объем высококачественных данных или вы работаете с меньшим набором данных?
- Вычислительные ресурсы: Есть ли у вас вычислительная мощность для поддержки более сложных алгоритмов?
- Временные ограничения: Как быстро необходимо развернуть модель?
4.2. Использование предварительно обученных моделей
Предварительно обученные модели могут ускорить процесс разработки ИИ. Эти модели уже обучены на комплексных наборах данных и могут быть адаптированы для аналогичных задач. Например, если вы работаете над распознаванием изображений, использование предварительно обученной модели, такой как VGG или ResNet, может сэкономить значительное время обучения.
Несмотря на то, что предварительно обученные модели обеспечивают прочную основу, они часто требуют тонкой настройки в соответствии с вашими конкретными потребностями. Обучение модели на вашем собственном наборе данных поможет лучше согласовать ее возможности с целями вашего проекта, тем самым обеспечивая более эффективную производительность. Этот подход сочетает в себе преимущества как пользовательских, так и предварительно обученных моделей.
4.3. Языки программирования и инструменты
Наиболее распространенными языками программирования для разработки программного обеспечения для искусственного интеллекта являются Python, R и Java. Кроме того, для более сложных моделей часто используются платформы глубокого обучения, такие как TensorFlow и PyTorch.
5. Обучение модели
Процесс обучения является одним из наиболее важных этапов всего процесса разработки.
5.1. Тренировочный процесс
Здесь ваша модель ИИ изучает все тонкости задач, которые она должна выполнять. Это включает в себя ввод очищенных и предварительно обработанных данных в модель. По мере того, как модель анализирует эти данные, она учится делать прогнозы на основе полученной информации.
Например, в случае модели машинного обучения, предназначенной для анализа настроений, процесс обучения включает в себя предоставление модели различных образцов текста вместе с их метками настроений, что позволяет модели выявлять закономерности того, как слова и фразы связаны с настроениями.
5.2. Непрерывное обучение
Модели ИИ обладают способностью развиваться и адаптироваться с помощью метода, называемого непрерывным обучением. Это особенно важно в сегодняшней быстро меняющейся ситуации, когда данные постоянно генерируются. Регулярно обновляя модель новыми данными, вы гарантируете, что она останется актуальной и точной в своих прогнозах и решениях.
Прочтите это краткое руководство, чтобы узнать больше о процессе обучения ИИ.
6. Валидация и тестирование
Это один из наиболее важных этапов, поскольку он помогает выявить проблемы в модели ИИ и улучшить их.
6.1. Оценка производительности модели
После процесса обучения следующим шагом является проверка модели ИИ путем тестирования ее производительности на новом, ранее не существовавшем наборе данных. Специалисты по данным часто используют такие показатели, как точность, точность и полнота, чтобы оценить эффективность модели.
Вы также можете сотрудничать с поставщиком услуг RLHF (обучение с подкреплением на основе отзывов людей), чтобы улучшить производительность вашей модели за счет большого количества талантливых специалистов.
6.2. Тонкая настройка
Если модель не соответствует показателям производительности, возможно, вам придется вернуться к чертежной доске. Это может означать сбор большего количества обучающих данных или выбор других алгоритмов машинного обучения.
7. Развертывание и обслуживание
7.1. Развертывание модели ИИ
После обучения и тестирования вашей модели последним шагом будет ее развертывание. Будь то чат-бот для обслуживания клиентов или сложная система анализа данных, модель искусственного интеллекта должна быть интегрирована в существующие инфраструктуры.
7.2. Долгосрочное обслуживание
Проекты ИИ не выполняются по принципу «установил и забыл». Они требуют постоянного обслуживания для адаптации к новым данным и условиям. Сюда входит мониторинг производительности системы и внесение необходимых обновлений.
Прочтите это руководство, чтобы узнать больше об улучшении моделей ИИ.
дальнейшее чтение
Если вам нужна помощь в поиске поставщика или у вас есть вопросы, свяжитесь с нами:
Найдите подходящих поставщиков
Ресурсы
- Сэм Рэнсботэм и др. (2019). Победа с ИИ. МИТСлоан. Доступ: 12 сентября 2023 г.
- МакКинси, IDC. (2023). Искусственный интеллект: углубленный анализ рынка 2023. Статистика. Доступ: 22 августа 2023 г.
- Лоуренс Гоасдафф. (2019). 3 барьера на пути внедрения ИИ. Гартнер. Доступ: 22 августа 2023 г.