
Цифровые издатели постоянно ищут способы оптимизировать и автоматизировать свои рабочие процессы в сфере мультимедиа, чтобы создавать и публиковать новый контент как можно быстрее.
Издатели могут иметь репозитории, содержащие миллионы изображений, и для экономии денег им необходимо иметь возможность повторно использовать эти изображения в статьях. Поиск изображения, которое лучше всего соответствует статье в репозиториях такого масштаба, может оказаться трудоемкой, повторяющейся и выполняемой вручную задачей, которую можно автоматизировать. Он также зависит от правильной маркировки изображений в репозитории, что также можно автоматизировать (историю успеха клиентов см. в документе Aller Media добивается успеха с KeyCore и AWS).
В этом посте мы покажем, как использовать Amazon Rekognition, Amazon SageMaker JumpStart и Amazon OpenSearch Service для решения этой бизнес-проблемы. Amazon Rekognition позволяет легко добавлять возможности анализа изображений в ваши приложения без каких-либо знаний в области машинного обучения (ML) и поставляется с различными API-интерфейсами для реализации таких сценариев использования, как обнаружение объектов, модерация контента, обнаружение и анализ лиц, а также распознавание текста и знаменитостей, что мы используем в этом примере. SageMaker JumpStart — это сервис с низким кодированием, который поставляется с готовыми решениями, примерами блокнотов и множеством современных предварительно обученных моделей из общедоступных источников, которые можно легко развернуть одним щелчком мыши в вашей учетной записи AWS. . Эти модели были упакованы так, чтобы их можно было безопасно и легко развертывать с помощью API-интерфейсов Amazon SageMaker. Новый SageMaker JumpStart Foundation Hub позволяет легко развертывать большие языковые модели (LLM) и интегрировать их с вашими приложениями. OpenSearch Service — это полностью управляемый сервис, который упрощает развертывание, масштабирование и эксплуатацию OpenSearch. Служба OpenSearch позволяет хранить векторы и другие типы данных в индексе и предлагает богатые функциональные возможности, позволяющие искать документы с использованием векторов и измерять семантическую связанность, которую мы используем в этом посте.
Конечная цель этого поста — показать, как мы можем представить набор изображений, семантически похожих на некоторый текст, будь то статья или синопсис телепередачи.
На следующем снимке экрана показан пример использования мини-статьи в качестве входных данных для поиска вместо использования ключевых слов и возможности отображать семантически похожие изображения.
Обзор решения
Решение разделено на два основных раздела. Сначала вы извлекаете метаданные ярлыков и знаменитостей из изображений с помощью Amazon Rekognition. Затем вы генерируете внедрение метаданных с помощью LLM. Вы храните имена знаменитостей и встраиваете метаданные в службу OpenSearch. Во втором основном разделе у вас есть API для запроса изображений в индексе вашей службы OpenSearch с использованием возможностей интеллектуального поиска OpenSearch для поиска изображений, семантически похожих на ваш текст.
В этом решении используются наши управляемые событиями сервисы Amazon EventBridge, AWS Step Functions и AWS Lambda для организации процесса извлечения метаданных из изображений с помощью Amazon Rekognition. Amazon Rekognition выполнит два вызова API для извлечения ярлыков и известных знаменитостей из изображения.
API обнаружения знаменитостей Amazon Rekognition возвращает ряд элементов в ответе. Для этого поста вы используете следующее:
- Имя, идентификатор и URL-адреса — имя знаменитости, уникальный идентификатор Amazon Rekognition и список URL-адресов, таких как ссылка на IMDb знаменитости или ссылка на Википедию для получения дополнительной информации.
- MatchConfidence — показатель достоверности совпадения, который можно использовать для управления поведением API. Мы рекомендуем применить подходящий порог к этому показателю в вашем приложении, чтобы выбрать предпочтительную рабочую точку. Например, установив пороговое значение 99 %, вы можете исключить больше ложных срабатываний, но можете пропустить некоторые потенциальные совпадения.
Во втором вызове API API обнаружения меток Amazon Rekognition возвращает ряд элементов в ответе. Вы используете следующее:
- Имя – имя обнаруженной метки.
- Уверенность – уровень уверенности в метке, присвоенной обнаруженному объекту.
Ключевой концепцией семантического поиска являются вложения. Встраивание слов — это числовое представление слова или группы слов в форме вектора. Когда у вас много векторов, вы можете измерить расстояние между ними, а векторы, близкие по расстоянию, семантически схожи. Таким образом, если вы создаете встраивание всех метаданных ваших изображений, а затем встраиваете свой текст, например, статью или телесюжет, используя ту же модель, вы затем можете найти изображения, которые семантически похожи на ваши данный текст.
В SageMaker JumpStart доступно множество моделей для создания внедрений. Для этого решения вы используете встраивание GPT-J 6B из Обнимающее лицо. Он производит высококачественные встраивания и имеет один из лучших показателей производительности по версии Hugging Face. результаты оценки. Amazon Bedrock — еще один вариант, все еще находящийся в предварительной версии, где вы можете выбрать модель Amazon Titan Text Embeddings для создания вложений.
Вы используете предварительно обученную модель GPT-J из SageMaker JumpStart, чтобы создать внедрение метаданных изображения и сохранить их как вектор k-NN в индексе службы OpenSearch вместе с именем знаменитости в другом поле.
Вторая часть решения — вернуть пользователю 10 лучших изображений, которые семантически похожи на их текст, будь то статья или телесюжет, включая любых знаменитостей, если они присутствуют. Выбирая изображение для сопровождения статьи, вы хотите, чтобы оно резонировало с соответствующими моментами статьи. В SageMaker JumpStart имеется множество моделей резюмирования, которые позволяют взять длинный текст и сократить его до основных моментов оригинала. В качестве модели суммирования вы используете модель AI21 Labs Summarize. Эта модель обеспечивает высококачественные обзоры новостных статей, а исходный текст может содержать около 10 000 слов, что позволяет пользователю резюмировать всю статью за один раз.
Чтобы определить, содержит ли текст какие-либо имена, потенциально известные знаменитости, вы используете Amazon Comprehend, который может извлекать ключевые сущности из текстовой строки. Затем вы фильтруете по сущности Person, которую используете в качестве входного параметра поиска.
Затем вы берете обобщенную статью и создаете встраивание, которое можно использовать в качестве еще одного входного параметра поиска. Важно отметить, что для внедрения статьи вы используете ту же модель, развернутую в той же инфраструктуре, что и для изображений. Затем вы используете Точный k-NN со сценарием подсчета очков чтобы можно было осуществлять поиск по двум полям: именам знаменитостей и вектору, в котором запечатлена смысловая информация статьи. Обратитесь к этому посту, в котором объясняются возможности векторной базы данных Amazon OpenSearch Service, о масштабируемости сценария Score и о том, как этот подход к большим индексам может привести к высоким задержкам.
Прохождение
На следующей диаграмме показана архитектура решения.
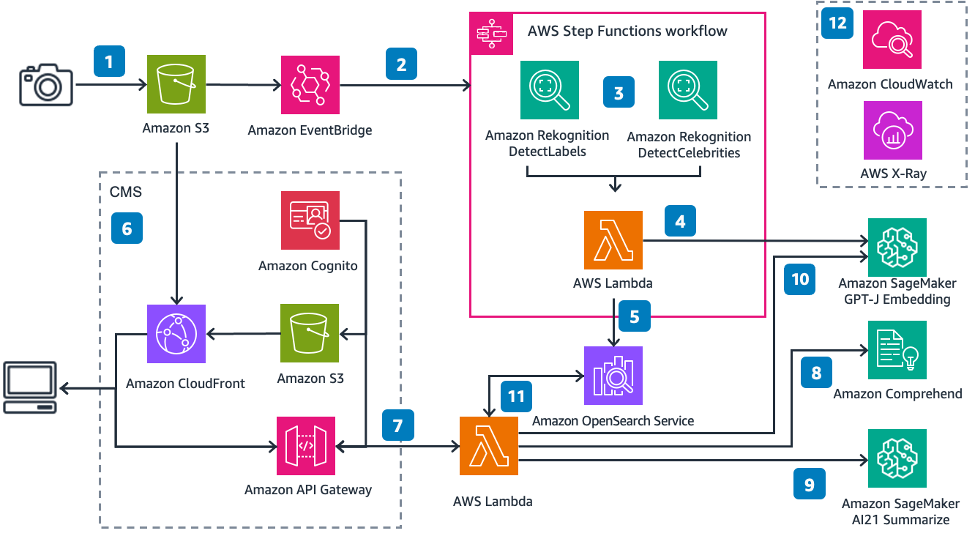
Следуя пронумерованным этикеткам:
- Вы загружаете изображение на Амазонка S3 ведро
- Amazon EventBridge прослушивает это событие, а затем запускает Функция шага AWS исполнение
- Функция Step принимает входные данные изображения, извлекает метку и метаданные знаменитостей.
- AWS Лямбда функция принимает метаданные изображения и генерирует встраивание
- Лямбда затем функция вставляет имя знаменитости (если оно присутствует) и встраивание в виде вектора k-NN в индекс службы OpenSearch.
- Амазонка S3 размещает простой статический веб-сайт, обслуживаемый Amazon CloudFront распределение. Интерфейс пользователя (UI) позволяет аутентифицироваться в приложении, используя Амазон Когнито для поиска изображений
- Вы отправляете статью или текст через пользовательский интерфейс.
- Другой Лямбда вызовы функций Amazon Понимание обнаружить любые имена в тексте
- Затем функция суммирует текст, чтобы получить соответствующие моменты из статьи.
- Функция генерирует вложение краткой статьи.
- Затем функция ищет Сервис OpenSearch индекс изображения для любого изображения, соответствующего имени знаменитости и k-ближайшим соседям вектора с использованием косинусного сходства
- Amazon CloudWatch и AWS-рентген дать вам возможность наблюдать за сквозным рабочим процессом, чтобы предупредить вас о любых проблемах.
Извлекайте и сохраняйте метаданные ключевых изображений
API Amazon Rekognition DetectLabels и RecounceeCelebrities предоставляют метаданные ваших изображений — текстовые метки, которые вы можете использовать для формирования предложения, на основе которого можно создать встраивание. В статье представлен текстовый ввод, который можно использовать для создания встраивания.
Создание и сохранение вложений слов
На следующем рисунке показано построение векторов наших изображений в двумерном пространстве, где для наглядности мы классифицировали вложения по их основной категории.

Вы также создаете встраивание этой недавно написанной статьи, чтобы можно было искать в службе OpenSearch ближайшие к статье изображения в этом векторном пространстве. Используя алгоритм k-ближайших соседей (k-NN), вы определяете, сколько изображений будет возвращено в ваших результатах.
При увеличении предыдущего рисунка векторы ранжируются на основе их расстояния от статьи, а затем возвращаются K-ближайшие изображения, где K в этом примере равно 10.
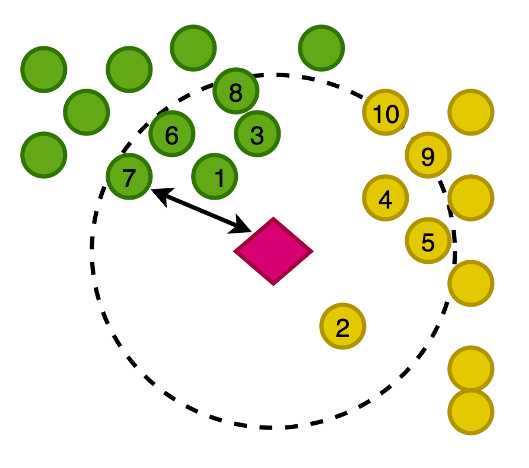
Служба OpenSearch предлагает возможность хранить большие векторы в индексе, а также предлагает функциональные возможности для выполнения запросов к индексу с использованием k-NN, так что вы можете запрашивать вектор для возврата k-ближайших документов, которые имеют векторы на близком расстоянии. используя различные измерения. В этом примере мы используем косинусное подобие.
Обнаружение имен в статье
Вы используете Amazon Comprehend, сервис обработки естественного языка (NLP) искусственного интеллекта, чтобы извлечь ключевые объекты из статьи. В этом примере вы используете Amazon Comprehend для извлечения сущностей и фильтрации по сущности Person, которая возвращает любые имена, которые Amazon Comprehend может найти в журналистской истории, с помощью всего лишь нескольких строк кода:
В этом примере вы загружаете изображение в Amazon Simple Storage Service (Amazon S3), что запускает рабочий процесс, в котором вы извлекаете метаданные из изображения, включая ярлыки и любых знаменитостей. Затем вы преобразуете извлеченные метаданные во встраивание и сохраняете все эти данные в службе OpenSearch.
Подведите итог статьи и создайте вложение
Краткое изложение статьи — важный шаг, позволяющий убедиться, что встраивание слов отражает важные моменты статьи и, следовательно, возвращает изображения, которые перекликаются с темой статьи.
Модель AI21 Labs Summarize очень проста в использовании без каких-либо подсказок и всего лишь нескольких строк кода:
Затем вы используете модель GPT-J для создания встраивания.
Затем вы выполняете поиск своих изображений в службе OpenSearch.
Ниже приведен пример фрагмента этого запроса:
Архитектура содержит простое веб-приложение, представляющее систему управления контентом (CMS).
Для примера статьи мы использовали следующий ввод:
«Вернер Фогельс любил путешествовать по всему миру на своей Toyota. Мы видим, как его Toyota появляется во многих сценах, когда он едет на встречу с различными клиентами в их родных городах».
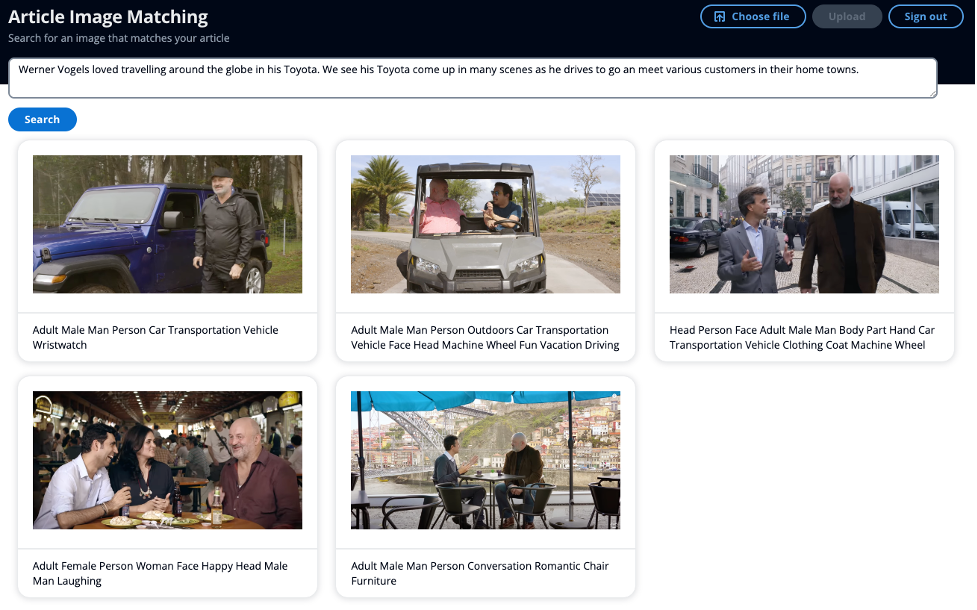
Ни одно из изображений не имеет метаданных со словом «Тойота», но семантика слова «Тойота» является синонимом автомобилей и вождения. Таким образом, на этом примере мы можем продемонстрировать, как можно выйти за рамки поиска по ключевым словам и возвращать изображения, семантически похожие. На приведенном выше снимке экрана пользовательского интерфейса подпись под изображением показывает метаданные, извлеченные Amazon Rekognition.
Вы можете включить это решение в более крупный рабочий процесс, в котором вы используете метаданные, которые вы уже извлекли из своих изображений, чтобы начать использовать векторный поиск вместе с другими ключевыми терминами, такими как имена знаменитостей, чтобы получить наиболее подходящие изображения и документы для вашего поискового запроса.
Заключение
В этом посте мы показали, как вы можете использовать Amazon Rekognition, Amazon Comprehend, SageMaker и OpenSearch Service для извлечения метаданных из ваших изображений, а затем использовать методы машинного обучения для их автоматического обнаружения с помощью поиска по знаменитостям и семантического поиска. Это особенно важно в издательской индустрии, где скорость имеет значение для быстрого распространения свежего контента на несколько платформ.
Дополнительную информацию о работе с мультимедийными ресурсами см. в разделе Медиа-аналитика стала умнее с Media2Cloud 3.0.
об авторе
 Марк Уоткинс является архитектором решений в команде СМИ и развлечений, помогая своим клиентам решать множество проблем с данными и машинным обучением. Вдали от профессиональной жизни он любит проводить время со своей семьей и наблюдать за тем, как растут двое его малышей.
Марк Уоткинс является архитектором решений в команде СМИ и развлечений, помогая своим клиентам решать множество проблем с данными и машинным обучением. Вдали от профессиональной жизни он любит проводить время со своей семьей и наблюдать за тем, как растут двое его малышей.