
Существует бесчисленное множество показателей, которые помогают ученым, работающим с данными, лучше понять эффективность модели. Но показатели точности модели и диагностические диаграммы, несмотря на их полезность, представляют собой совокупность — они могут скрыть важную информацию о ситуациях, в которых модель может работать не так, как ожидалось. Мы могли бы построить модель с высокой общей точностью, но неосознанно отстает в определенных сценарияханалогично тому, как виниловая пластинка может выглядеть целой, но на ней есть царапины, которые невозможно обнаружить, пока вы не проиграете определенную часть пластинки.
Любому человеку, который использует модели — от специалистов по обработке данных до руководителей — может потребоваться дополнительная информация, чтобы решить, действительно ли модель готова к производству, а если нет, то как ее улучшить. Эти идеи могут лежать в определенных сегментах ваших данных моделирования.
Почему сегментация модели имеет значение
Во многих случаях построение отдельных моделей для разных сегментов данных обеспечит более высокую общую производительность модели, чем подход «одна модель, которая управляет всеми».
Допустим, вы прогнозируете доход своего бизнеса. У вас есть два основных бизнес-подразделения: подразделение Enterprise/B2B и подразделение Consumer/B2C. Вы можете начать с построения единой модели для прогнозирования общего дохода. Но когда вы измеряете качество своих прогнозов, вы можете обнаружить, что оно не так хорошо, как нужно вашей команде. В этой ситуации построение модели для вашего подразделения B2B и отдельной модели для вашего подразделения B2C, скорее всего, улучшит производительность вашего подразделения. оба.
Разделив модель на более мелкие и более конкретные модели, обученные на подгруппах наших данных, мы можем получить более конкретную информацию, адаптировать модель к этой отдельной группе (население, SKU и т. д.) и в конечном итоге улучшить производительность модели.
Это особенно верно, если:
- Ваши данные имеют естественные кластеры — например, отдельные блоки B2B и B2C.
- У вас есть группы, которые несбалансированы в наборе данных. Более крупные группы в данных могут доминировать над небольшими, а модель с высокой общей точностью может маскировать более низкую производительность подгрупп. Если ваш B2B-бизнес приносит 80% вашего дохода, ваш подход «одна модель, чтобы управлять всеми» может оказаться совершенно неприемлемым для вашего B2C-бизнеса, но этот факт скрывается за относительным размером вашего B2B-бизнеса.
Но как далеко вы зайдете по этому пути? Полезно ли дальнейшее разделение бизнеса B2B по каждому из 20 различных каналов или линеек продуктов? Зная, что один общий показатель точности для всего вашего набора данных может скрывать важную информацию, есть ли простой способ узнать, какие подгруппы наиболее важны или какие подгруппы страдают от низкой производительности? А как насчет выводов: одни и те же факторы стимулируют продажи как в сегментах B2B, так и в сегментах B2C, или между этими сегментами существуют различия? Чтобы принять эти решения, нам необходимо быстро понять суть модели для различных сегментов наших данных — информацию, связанную как с производительностью, так и с объяснимостью модели. DataRobot Sliced Insights упрощает эту задачу.
Детальная информация DataRobot, теперь доступный на платформе DataRobot AI, позволяет пользователям проверять эффективность модели на определенных подмножествах своих данных. Пользователи могут быстро определять интересующие их сегменты данных, называемые срезами, и оценивать производительность этих сегментов. Они также могут быстро генерировать соответствующую информацию и делиться ею с заинтересованными сторонами.
Как генерировать фрагментированную информацию
Sliced Insights можно полностью генерировать в пользовательском интерфейсе — код не требуется. Сначала определите срез на основе трех фильтров: числовых или категориальных признаков, определяющих интересующий сегмент. Наслаивая несколько фильтров, пользователи могут определять собственные группы, которые их интересуют. Например, если я оцениваю модель повторной госпитализации в больницу, я мог бы определить собственный срез на основе пола, возраста, количества процедур, которые прошел пациент, или любой их комбинации.
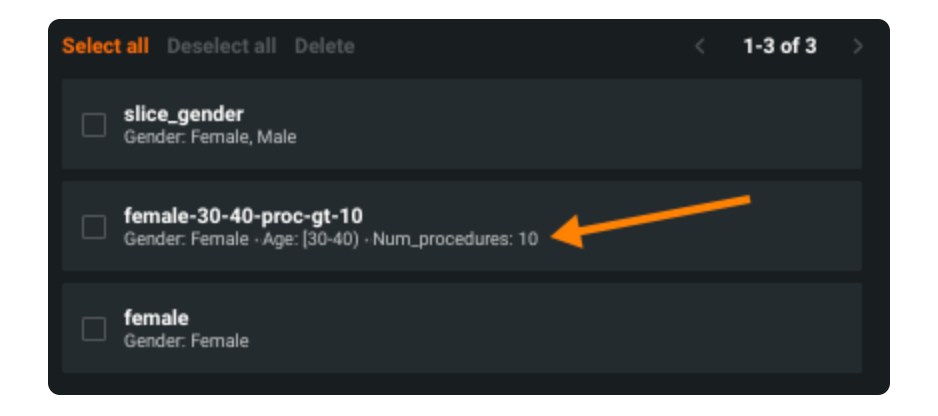
После определения среза пользователи генерируют срезовую информацию, применяя этот срез к основным инструментам производительности и объяснимости в DataRobot: «Эффекты функций», «Влияние функций», «Диаграмма подъема», «Остатки» и «Кривая ROC».
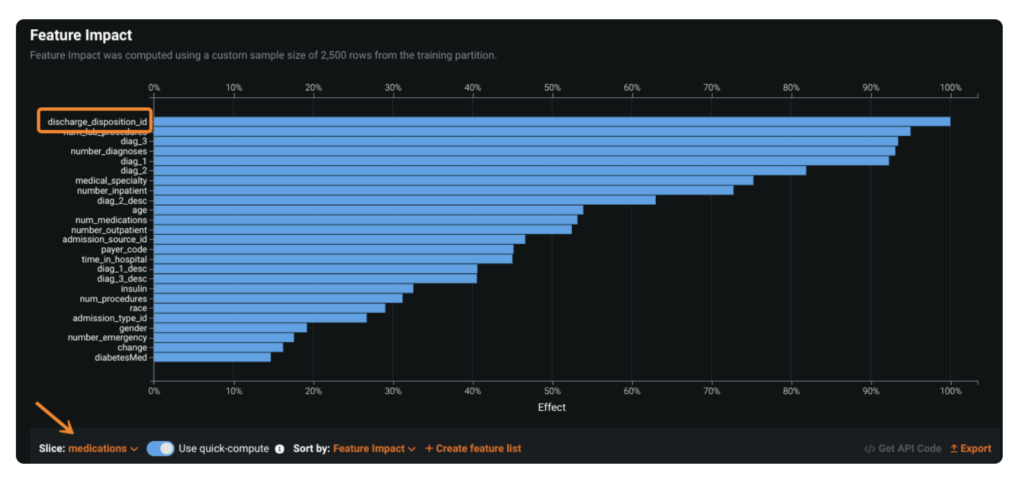
Этот процесс часто является итеративным. Как специалист по данным, я мог бы начать с определения срезов для ключевых сегментов моих данных — например, пациентов, которые были госпитализированы на неделю или дольше, по сравнению с теми, кто оставался там всего на день или два.
Оттуда я могу копнуть глубже, добавив больше фильтров. На встрече мое руководство может спросить меня о влиянии ранее существовавших условий. Теперь, с помощью пары кликов, я могу увидеть, как это повлияет на производительность моей модели и связанные с этим идеи. Переключение между срезами вперед и назад приводит к получению новой и другой информации о срезах. Более подробную информацию о настройке и использовании срезов см. посетите страницу документации.
Практический пример: неявки в больницу
Недавно я работал с больничной системой, которая разработала модель неявки пациентов. Результаты выглядели довольно точными: модель отличала пациентов с наименьшим риском неявки от пациентов с более высоким риском и выглядела хорошо откалиброванной (прогнозируемые и фактические линии близко следуют друг за другом). Тем не менее, они хотели быть уверены, что после развертывания это принесет пользу их командам конечных пользователей.
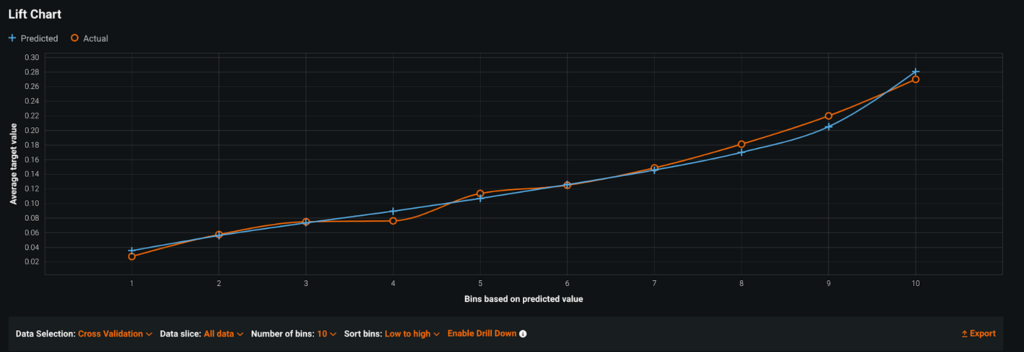
Команда считала, что между отделами будут очень разные модели поведения. У них было несколько крупных отделений (внутренней медицины, семейной медицины) и длинный хвост более мелких (онкологии, гастроэнтерологии, неврологии, трансплантологии). В некоторых департаментах наблюдался высокий процент неявок (до 20%), тогда как в других редко неявки вообще (<5%).
Они хотели знать, следует ли им создавать модель для каждого отдела или будет достаточно одной модели для всех отделов.
Используя Sliced Insights, быстро стало ясно, что построение одной модели для всех отделов — неправильный выбор. Из-за классового дисбаланса в данных модель хорошо соответствовала крупным отделам и имела высокую общую точность, что скрывало низкую производительность в небольших отделах.
Срез: Внутренняя медицина
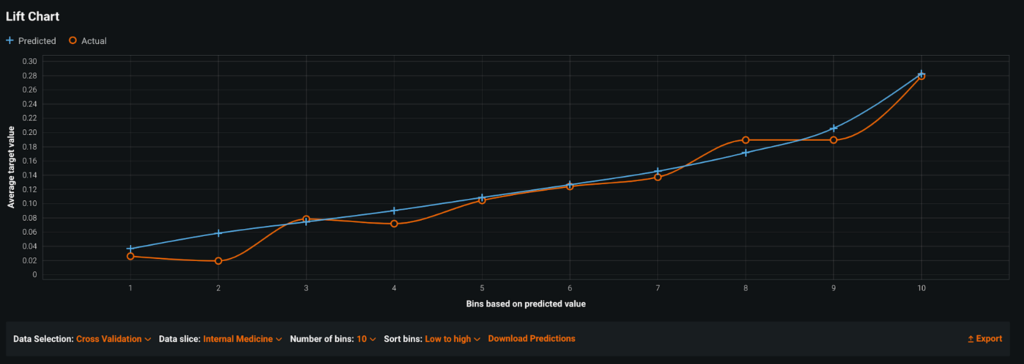
Секция: Гастроэнтерология
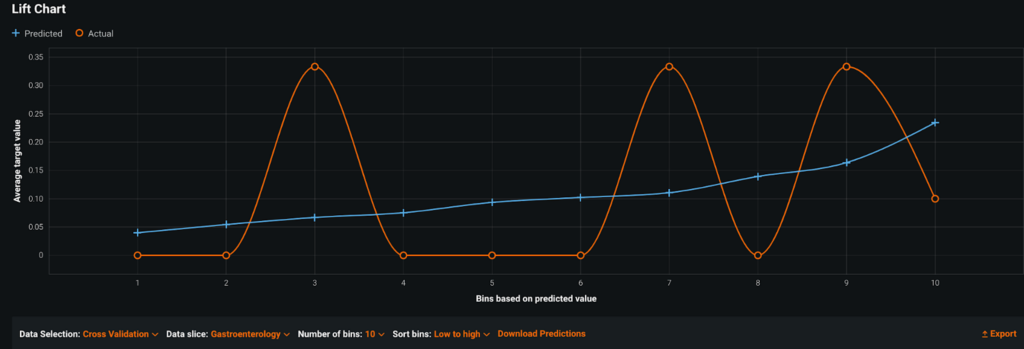
В результате команда решила ограничить область действия своей «общей» модели только теми отделами, в которых у них было больше всего данных и где модель приносила пользу. Для небольших отделений команда использовала экспертный опыт для кластеризации отделений на основе типов пациентов, которых они принимали, а затем обучила модель для каждого кластера. Компания Sliced Insights помогла этой медицинской команде создать правильный набор групп и моделей для каждого конкретного случая использования, чтобы каждое отделение могло реализовать свою ценность.
Частичная информация для лучшей сегментации модели
Sliced Insights помогает пользователям оценивать производительность своих моделей на более глубоком уровне, чем просмотр общих показателей. Модель, которая отвечает общим требованиям точности, может постоянно давать сбой для важных сегментов данных, например, для недостаточно представленных демографических групп или небольших бизнес-единиц. Определяя срезы и оценивая информацию о модели по отношению к этим срезам, пользователи могут легче определить, необходима ли сегментация модели или нет, быстро выявить эти сведения для лучшего взаимодействия с заинтересованными сторонами и, в конечном итоге, помочь организациям принимать более обоснованные решения о том, как и когда должна быть применена модель.
Об авторе

Кори Кайнд — ведущий специалист по данным в компании DataRobot, где она работает с клиентами из различных отраслей, внедряя решения на основе искусственного интеллекта для решения их наиболее насущных задач. Особое внимание она уделяет сектору здравоохранения, в частности тому, как организации создают и внедряют высокоточные, надежные решения искусственного интеллекта, которые обеспечивают как клинические, так и операционные результаты. До работы в DataRobot она работала специалистом по данным в Gartner. Она живет в Детройте и любит проводить время со своим партнером и двумя маленькими детьми.
Знакомьтесь, Кори Кайнд