
В нашем предыдущем сообщении в блоге мы говорили о том, как упростить развертывание и мониторинг базовых моделей с помощью DataRobot MLOps. Мы взяли предварительно обученную модель из HuggingFace с помощью Tensorflow, написали простой скрипт вывода и загрузили скрипт и сохраненную модель в виде пользовательского пакета модели в DataRobot MLOps. Затем мы легко развернули предварительно обученную базовую модель на серверах DataRobot всего за несколько минут.
В этом сообщении блога мы покажем, как можно без особых усилий добиться значительного повышения скорости логического вывода той же модели при одновременном снижении потребления ресурсов. В нашем пошаговом руководстве вы узнаете, что нужно всего лишь преобразовать вашу языковую модель в формат ONNX. Встроенная поддержка среды выполнения ONNX в DataRobot позаботится обо всем остальном.
Почему большие языковые модели сложны для логического вывода?
Ранее мы говорили о том, что такое языковые модели. Нейронная архитектура больших языковых моделей может иметь миллиарды параметров. Наличие огромного количества параметров означает, что эти модели будут жадными до ресурсов и медленными для прогнозирования. Из-за этого их сложно использовать для вывода с высокой производительностью. Кроме того, мы хотим, чтобы эти модели не только обрабатывали один вход за раз, но также обрабатывали пакеты входных данных и потребляли их более эффективно. Хорошая новость заключается в том, что у нас есть способ улучшить их производительность и пропускную способность, ускорив процесс вывода благодаря возможностям среды выполнения ONNX.
Что такое ONNX и среда выполнения ONNX?
ОННКС (Open Neural Network Exchange) — это открытый стандартный формат для представления моделей машинного обучения (ML), построенных на различных платформах, таких как PyTorch, Tensorflow/Keras, scikit-learn. Среда выполнения ONNX также является проектом с открытым исходным кодом, построенным на стандарте ONNX. Это механизм вывода, оптимизированный для ускорения процесса вывода моделей, преобразованных в формат ONNX, для широкого спектра операционных систем, языков и аппаратных платформ.
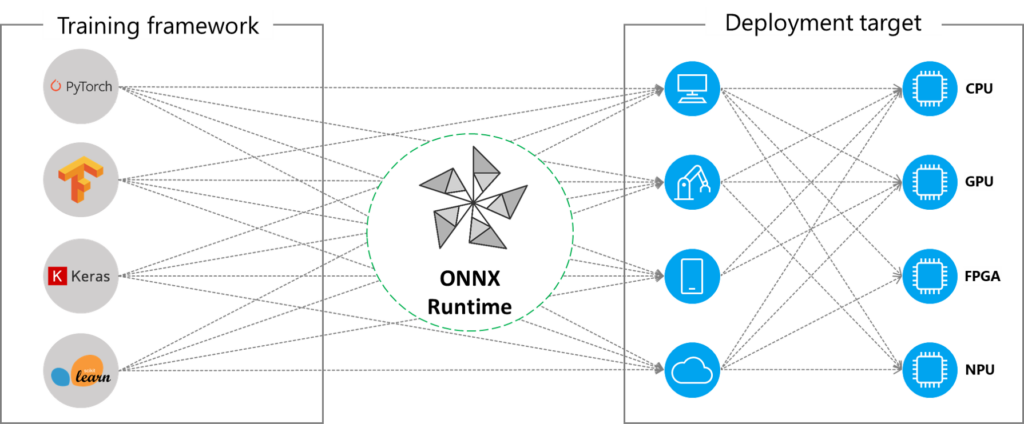
ONNX и его среда выполнения вместе образуют основу для стандартизации и ускорения вывода моделей в производственных средах. С помощью определенных методов оптимизации1, ONNX Runtime ускоряет вывод моделей на различных платформах, таких как мобильные устройства, облачные или пограничные среды. Он обеспечивает абстракцию, используя вычислительные возможности этих платформ через единый интерфейс API.
Кроме того, преобразуя модели в ONNX, мы получаем преимущество функциональной совместимости фреймворков, поскольку можем экспортировать модели, обученные в различных фреймворках ML, в ONNX и наоборот, загружать ранее экспортированные модели ONNX в память и использовать их в выбранной фреймворке ML.
Ускорение вывода моделей на основе трансформаторов с помощью ONNX Runtime
Различные тесты, выполненные независимыми инженерными группами в отрасли, продемонстрировали, что модели на основе трансформаторов могут значительно выиграть от оптимизации среды выполнения ONNX для уменьшения задержки и увеличения пропускной способности ЦП.
Некоторые примеры включают работу Microsoft над оптимизацией модели BERT с использованием ONNX Runtime.2, Результаты бенчмаркинга Twitter для логического вывода процессора трансформатора в Google Cloud3и ускорение преобразователей предложений с Hugging Face Optimum4.
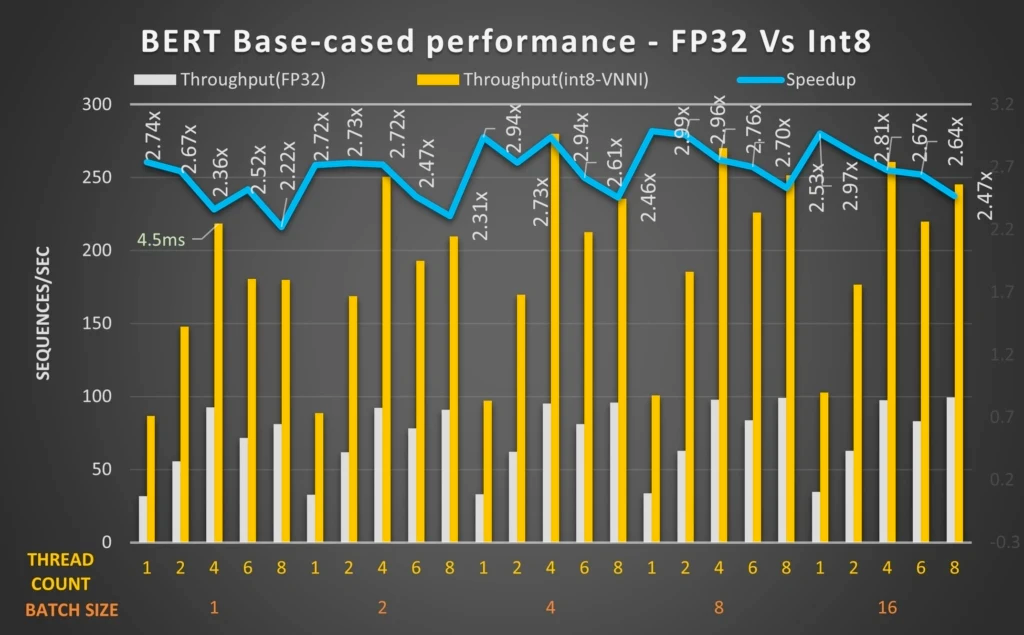
Эти тесты демонстрируют, что мы можем значительно увеличить пропускную способность и производительность для моделей НЛП на основе преобразователей, особенно за счет квантования. Например, в приведенном выше тесте команды Microsoft квантованная 12-уровневая модель BERT с Intel® DL Boost: VNNI и ONNX Runtime может обеспечить прирост производительности до 2,9 раз.
Как DataRobot MLOps изначально поддерживает ONNX?
Для рабочих процессов моделирования или логического вывода вы можете интегрировать собственный код в DataRobot с помощью следующих двух механизмов:
- В качестве пользовательской задачи: Хотя DataRobot предоставляет сотни встроенных задач, бывают ситуации, когда вам нужны методы предварительной обработки или моделирования, которые в настоящее время не поддерживаются по умолчанию. Чтобы восполнить этот пробел, вы можете добавить пользовательскую задачу, реализующую отсутствующий метод, подключить эту задачу к план внутри DataRobot, а затем обучите, оцените и разверните этот план таким же образом, как и для любого другого плана, созданного DataRobot. Вы можете просмотреть, как работает процесс здесь.
- В качестве пользовательской модели вывода: Это может быть предварительно обученная модель или пользовательский код, подготовленный для логического вывода, или их комбинация. Модель логического вывода может иметь предопределенную схему ввода/вывода для классификации/регрессии/обнаружения аномалий или быть полностью неструктурированной. Вы можете прочитать более подробную информацию о развертывании ваших пользовательских моделей вывода. здесь.
В обоих случаях, чтобы запустить свои пользовательские модели на платформе ИИ DataRobot с поддержкой MLOps, вы сначала выбираете один из наших public_dropin_environments такие как Python3 + PyTorch, Python3 + Keras/Tensorflow или Python3 + ONNX. Каждая из этих сред определяет библиотеки, доступные в среде, и предоставляет шаблон. Ваши собственные требования к зависимостям могут быть применены к одной из этих базовых сред, чтобы создать среду выполнения для ваших настраиваемых задач или настраиваемых моделей вывода.
Дополнительным преимуществом сред выполнения DataRobot является то, что если у вас есть один артефакт модели и ваша модель соответствует определенным структурам ввода/вывода, то есть вам не нужен настраиваемый сценарий вывода для преобразования входного запроса или необработанных прогнозов, вы даже не необходимо предоставить собственный сценарий в загруженном пакете модели. В случае с ONNX, если вы хотите прогнозировать только с одним файлом .onnx, и этот файл модели соответствует структурированная спецификация, когда вы выбираете базовую среду Python3+ONNX для своего пользовательского пакета модели, DataRobot MLOps будет знать, как загрузить эту модель в память и делать прогнозы с ее помощью. Чтобы узнать больше и получить простые для воспроизведения примеры, посетите веб-сайт раздел шаблонов пользовательских моделей вывода в нашем репозитории пользовательских моделей.
Прохождение
Прочитав всю эту информацию о преимуществах производительности и относительной простоте реализации моделей с помощью ONNX, я уверен, что вы более чем рады приступить к работе.
Чтобы продемонстрировать сквозной пример, мы выполним следующие шаги:
- Возьмите ту же модель фундамента из нашего предыдущего поста в блоге и сохраните ее на локальном диске.
- Экспортируйте сохраненную модель Tensorflow в формат ONNX.
- Упакуйте артефакт модели ONNX вместе с пользовательским скриптом вывода (custom.py).
- Загрузите пакет пользовательской модели в DataRobot MLOps в базовой среде ONNX.
- Создайте развертывание.
- Отправлять запросы прогнозирования в конечную точку развертывания.
Для краткости мы покажем только дополнительные и измененные шаги, которые вы будете выполнять в дополнение к пошаговому руководству из нашего предыдущего блога, но сквозная реализация доступна в этом Google Colab. блокнот в репозитории сообщества DataRobot.
Преобразование базовой модели в ONNX
Для этого урока мы будем использовать transformer инструмент преобразования ONNX библиотеки, чтобы преобразовать LLM, отвечающий на наши вопросы, в формат ONNX, как показано ниже.
FOUNDATION_MODEL = "bert-large-uncased-whole-word-masking-finetuned-squad"
!python -m transformers.onnx --model=$FOUNDATION_MODEL --feature=question-answering $BASE_PATH
Изменение вашего пользовательского сценария вывода для использования вашей модели ONNX
Для вывода этой модели на DataRobot MLOps наш скрипт custom.py загрузит модель ONNX в память в сеансе среды выполнения ONNX и обработает входящие запросы прогнозирования следующим образом:
%%writefile $BASE_PATH/custom.py
"""
Copyright 2021 DataRobot, Inc. and its affiliates.
All rights reserved.
This is proprietary source code of DataRobot, Inc. and its affiliates.
Released under the terms of DataRobot Tool and Utility Agreement.
"""
import json
import os
import io
from transformers import AutoTokenizer
import onnxruntime as ort
import numpy as np
import pandas as pd
def load_model(input_dir):
global model_load_duration
onnx_path = os.path.join(input_dir, "model.onnx")
tokenizer_path = os.path.join(input_dir)
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
sess = ort.InferenceSession(onnx_path)
return sess, tokenizer
def _get_answer_in_text(output, input_ids, idx, tokenizer):
answer_start = np.argmax(output(0), axis=1)(idx)
answer_end = (np.argmax(output(1), axis=1) + 1)(idx)
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids(answer_start:answer_end))
)
return answer
def score_unstructured(model, data, query, **kwargs):
global model_load_duration
sess, tokenizer = model
# Assume batch input is sent with mimetype:"text/csv"
# Treat as single prediction input if no mimetype is set
is_batch = kwargs("mimetype") == "text/csv"
if is_batch:
input_pd = pd.read_csv(io.StringIO(data), sep="|")
input_pairs = list(zip(input_pd("context"), input_pd("question")))
inputs = tokenizer.batch_encode_plus(
input_pairs, add_special_tokens=True, padding=True, return_tensors="np"
)
input_ids = inputs("input_ids")
output = sess.run(("start_logits", "end_logits"), input_feed=dict(inputs))
responses = ()
for i, row in input_pd.iterrows():
answer = _get_answer_in_text(output, input_ids(i), i, tokenizer)
response = {
"context": row("context"),
"question": row("question"),
"answer": answer,
}
responses.append(response)
to_return = json.dumps(
{
"predictions": responses
}
)
else:
data_dict = json.loads(data)
context, question = data_dict("context"), data_dict("question")
inputs = tokenizer(
question,
context,
add_special_tokens=True,
padding=True,
return_tensors="np",
)
input_ids = inputs("input_ids")(0)
output = sess.run(("start_logits", "end_logits"), input_feed=dict(inputs))
answer = _get_answer_in_text(output, input_ids, 0, tokenizer)
to_return = json.dumps(
{
"context": context,
"question": question,
"answer": answer
}
)
return to_returnСоздание пользовательского развертывания модели вывода в базовой среде DataRobot ONNX.
В качестве последнего изменения мы создадим развертывание этой пользовательской модели в базовой среде ONNX DataRobot MLOps, как показано ниже:
deployment = deploy_to_datarobot(BASE_PATH,
"ONNX",
"bert-onnx-questionAnswering",
"Pretrained BERT model, fine-tuned on SQUAD for question answering")Когда развертывание будет готово, мы проверим нашу пользовательскую модель с помощью нашего тестового ввода и убедимся, что наш предварительно обученный LLM отвечает на наши вопросы:
datarobot_predict(test_input, deployment.id)
Сравнение производительности
Теперь, когда у нас все готово, пришло время сравнить наше предыдущее развертывание Tensorflow с альтернативой ONNX.
Для наших целей сравнительного анализа мы ограничили развертывание нашей пользовательской модели только 4 ГБ памяти из наших настроек MLOps, чтобы мы могли сравнить альтернативы Tensorflow и ONNX при ограниченных ресурсах.
Как видно из приведенных ниже результатов, наша модель в ONNX предсказывает в 1,5 раза быстрее, чем ее аналог Tensorflow. И этот результат можно увидеть только через дополнительный базовый экспорт ONNX (т. е. без каких-либо дополнительных конфигураций оптимизации, таких как квантование).
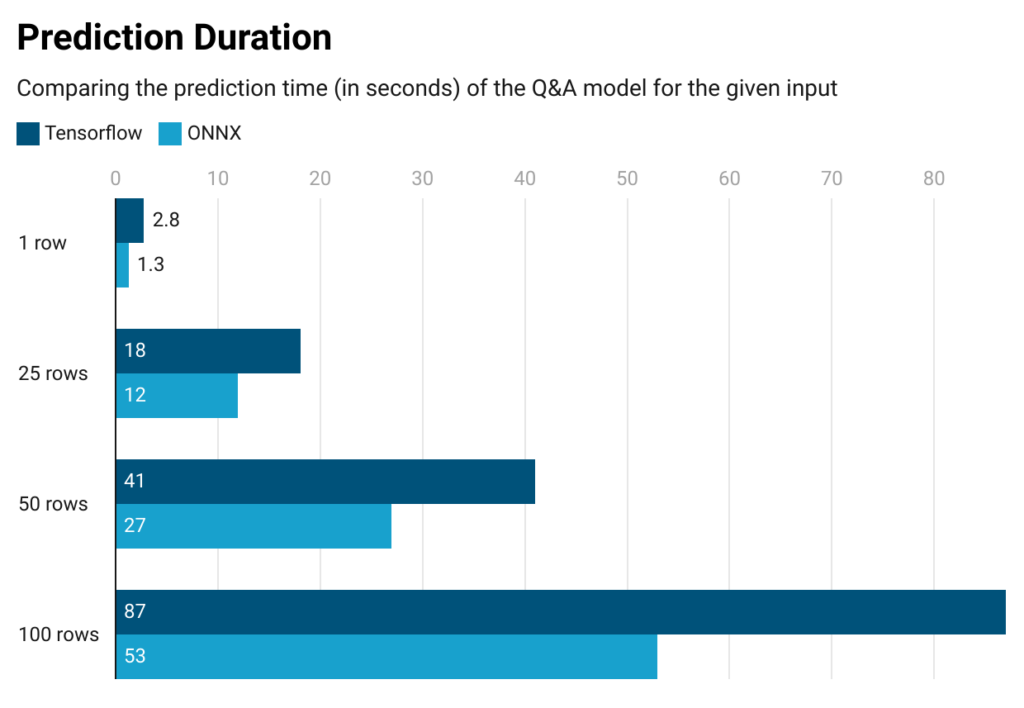
Что касается потребления ресурсов, то где-то после ~100 строк развертывание нашей модели Tensorflow начинает возвращать ошибки нехватки памяти (OOM), а это означает, что этой модели потребуется более 4 ГБ памяти для обработки и прогнозирования ~100 строк ввода. С другой стороны, наше развертывание модели ONNX может вычислять прогнозы примерно до 450 строк без возникновения ошибки OOM. В качестве вывода для нашего варианта использования тот факт, что модель Tensorflow обрабатывает до 100 строк, в то время как ее эквивалент ONNX обрабатывает до 450 строк, показывает, что модель ONNX более эффективна с точки зрения ресурсов, поскольку использует гораздо меньше памяти.
Начните использовать ONNX для ваших пользовательских моделей
Используя стандарт ONNX с открытым исходным кодом и среду выполнения ONNX, разработчики ИИ могут воспользоваться функциональной совместимостью платформы и ускоренной производительностью логического вывода, особенно для больших языковых моделей на основе преобразователей в предпочитаемой ими среде выполнения. Благодаря встроенной поддержке ONNX DataRobot MLOps позволяет организациям легко получать выгоду от своих развертываний машинного обучения с оптимизированной скоростью и пропускной способностью.
В этом сообщении в блоге мы показали, насколько легко использовать большую языковую модель для ответов на вопросы в ONNX в качестве пользовательской модели DataRobot, а также какую производительность логического вывода и эффективность использования ресурсов можно получить с помощью простого шага преобразования. Чтобы воспроизвести этот рабочий процесс, вы можете найти полноценный блокнот в репозитории сообщества DataRobot, а также многие другие учебные пособия, чтобы расширить возможности разработчиков ИИ с помощью возможностей DataRobot.
1 ONNX Runtime, оптимизация модели
2 Microsoft, Оптимизация модели BERT для ядер ЦП Intel с использованием поставщика выполнения по умолчанию во время выполнения ONNX
3 Блог Twitter, Ускорение логического вывода ЦП Transformer в Google Cloud
4 Филипп Шмид, Ускорьте преобразование предложений с оптимальным обниманием лица
5 Microsoft, Оптимизация модели BERT для ядер ЦП Intel с использованием поставщика выполнения по умолчанию во время выполнения ONNX
Об авторе

Асли Сабанджи Демирез — старший инженер по машинному обучению в DataRobot. Она имеет степень бакалавра в области вычислительной техники с двойной специализацией в области инженерии управления Стамбульского технического университета. Работая в офисе технического директора, ей нравится быть в центре исследований и разработок DataRobot для внедрения инноваций. Ее страсть заключается в области глубокого обучения, и ей особенно нравится создавать мощные интеграции между уровнями платформы и приложений в экосистеме ML, стремясь сделать целое больше, чем сумма частей.
Познакомьтесь с Аслы Сабанджи Демирез