
До сих пор мы говорили о дискриминационные модели который сопоставить входные объекты x с метками y и приблизительный P(y/x) – закон Байя.
Генеративные модели делают наоборот, они пытаются предсказывать входные функции с учетом меток. Предполагая, что задана метка y, насколько вероятно, что мы увидим определенные функции x. Они аппроксимировать совместную вероятность P(x и y).

Генеративно-состязательные сети (GAN)

источник: О’Райли

Компоненты ГАН:
1. Генератор – Это обратная CNN, вместо того, чтобы сжимать информацию по мере того, как мы идем по цепочке CNN и извлекать признаки на выходе, эта сеть принимает случайный шум в качестве входных признаков и генерирует изображение на выходе.
2. Дискриминатор – Дискриминатор — это CNN, которая просматривает изображения как из обучающего набора, так и из выходных данных Генератора и классифицирует их как настоящие (1) или фальшивые (0).
Как правило, и генератор, и дискриминатор имеют обратные функции для оптимизации. Где дискриминатор пытается минимизировать перекрестную энтропийную потерю правильного предсказания реального и поддельного изображения. Генератор пытается максимизировать эту потерю (пытаясь обмануть дискриминатор).
Давайте рассмотрим простую математику того, как Генератор и Дискриминатор конкурируют друг с другом:
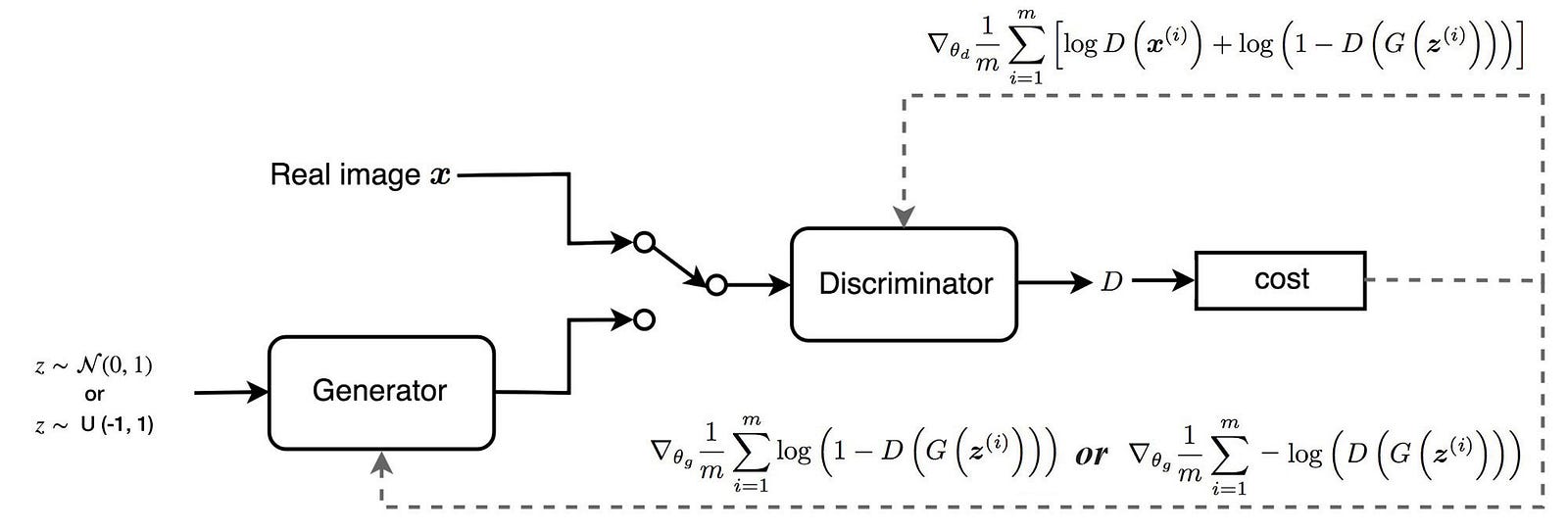
Отмечает функцию потерь Дискриминатора –
1. Первый срок является выходом дискриминатора для изображения тренировочного набора (x) – вы хотите, чтобы выход дискриминатора D (x) был равен 1. Давайте рассмотрим это, как выглядит потеря журнала –
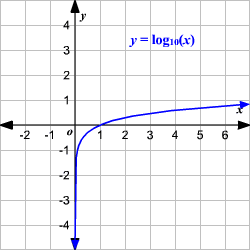
log(D(x) или 1) равно 0. Таким образом, для правильной классификации изображения тренировочного набора логарифмическая потеря будет равна 0. Однако для обратного случая – D(x) = 0 для изображения тренировочного набора , потеря будет равна отрицательной бесконечности.
2. Второй срок – log(1-D(G(z)), вы хотите, чтобы дискриминатор мог идентифицировать сгенерированное изображение G(z) и выводить D(G(z)) = 0. В этом случае потеря будет равна 0 Однако, если он ошибается и считает сгенерированное изображение реальным – log(0) равен -ve бесконечности.
3. Сеть сильно наказывается за неправильную классификацию в обоих случаях.
Дискриминатор пытается минимизировать потери из-за неправильной классификации, в то же время генератор пытается максимизировать потери дискриминатора для сгенерированного им вывода. Таким образом, концепция тесно связана с игрой минимум-макс.
Что здесь пытается сделать дискриминатор?

Источник — презентация Ian Goodfellow ’16 OpenAI.
- Цель дискриминатора определена на слайде выше (соотношение), дискриминатор, по сути, пытается определить разницу между входными данными, генерируемыми моделью, и фактическими входными данными обучающего набора.
- Итак, если pdata(x) = pmodel(x), то D(x) равно 0,5. Дискриминатор не может отличить подделку от настоящего. Это цель оптимизации здесь.
- Примечание. В то же время генератор пытается максимально приблизить модель и распределение данных друг к другу.
Оставайтесь с нами, чтобы узнать больше.
Использованная литература:
https://skymind.ai/wiki/generative-adversarial-network-gan
https://medium.com/@jonathan_hui/gan-whats-generative-adversarial-networks-and-its-application-f39ed278ef09