
В современном цифровом мире большинство потребителей предпочитают самостоятельно находить ответы на свои вопросы по обслуживанию клиентов, а не тратить время на обращение к предприятиям и/или поставщикам услуг. В этой записи блога рассматривается инновационное решение для создания чат-бота вопросов и ответов в Amazon Lex, использующего существующие ответы на часто задаваемые вопросы с вашего веб-сайта. Этот инструмент на основе искусственного интеллекта может обеспечить быстрые и точные ответы на реальные запросы, позволяя клиенту быстро и легко решать распространенные проблемы самостоятельно.
Прием одного URL-адреса
Многие предприятия имеют опубликованный набор ответов на часто задаваемые вопросы для своих клиентов, доступный на их веб-сайте. В этом случае мы хотим предложить клиентам чат-бота, который может ответить на их вопросы из наших опубликованных часто задаваемых вопросов. В записи блога под названием «Расширьте возможности Amazon Lex с помощью диалоговых функций часто задаваемых вопросов с помощью LLM» мы продемонстрировали, как вы можете использовать комбинацию Amazon Lex и LlamaIndex для создания чат-бота на основе имеющихся у вас источников знаний, таких как документы PDF или Word. Чтобы поддерживать простой FAQ, основанный на веб-сайте часто задаваемых вопросов, нам необходимо создать процесс загрузки, который может сканировать веб-сайт и создавать вложения, которые LlamaIndex может использовать для ответов на вопросы клиентов. В этом случае мы будем опираться на бота, созданного в предыдущем сообщении в блоге, который запрашивает эти вложения с высказыванием пользователя и возвращает ответ из часто задаваемых вопросов веб-сайта.
На следующей диаграмме показано, как процесс загрузки и бот Amazon Lex работают вместе для нашего решения.
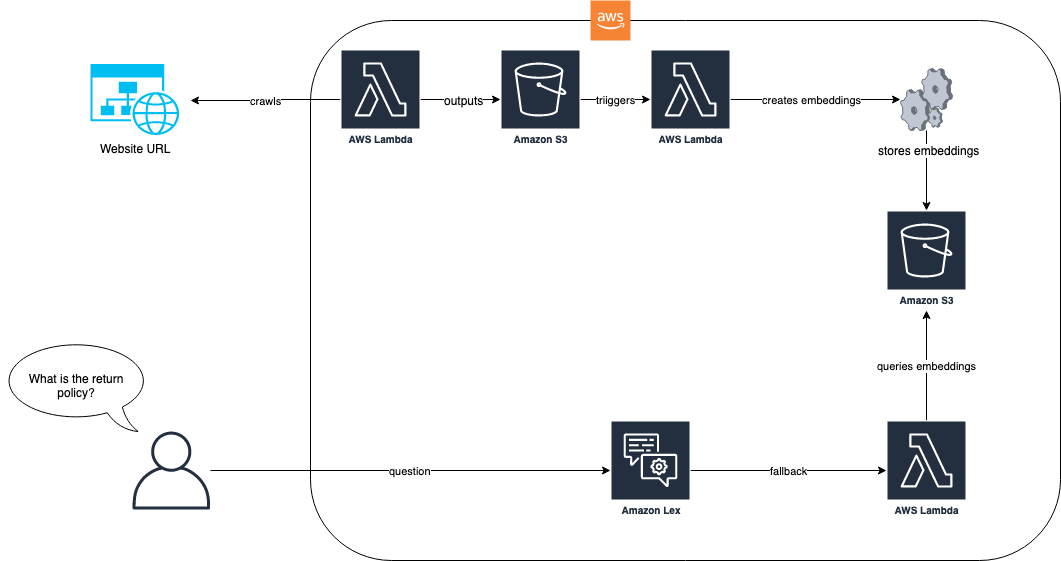
В рабочем процессе решения веб-сайт с часто задаваемыми вопросами загружается через AWS Lambda. Эта функция Lambda сканирует веб-сайт и сохраняет полученный текст в корзине Amazon Simple Storage Service (Amazon S3). Затем корзина S3 запускает функцию Lambda, которая использует LlamaIndex для создания вложений, которые хранятся в Amazon S3. Когда от конечного пользователя поступает вопрос, например «Какова ваша политика возврата?», бот Amazon Lex использует свою функцию Lambda для запроса вложений, используя подход на основе RAG с LlamaIndex. Дополнительные сведения об этом подходе и предварительных требованиях см. в записи блога Расширьте возможности Amazon Lex с помощью диалоговых функций часто задаваемых вопросов с помощью LLM.
После того, как предварительные условия из вышеупомянутого блога выполнены, первым шагом будет добавление часто задаваемых вопросов в репозиторий документов, который может быть векторизован и проиндексирован LlamaIndex. Следующий код показывает, как это сделать:
В предыдущем примере мы берем предопределенный URL веб-сайта с часто задаваемыми вопросами от Zappos и загружаем его с помощью EZWebLoader сорт. С помощью этого класса мы перешли по URL-адресу и загрузили все вопросы, которые есть на странице, в индекс. Теперь мы можем задать вопрос вроде «Есть ли у Zappos подарочные карты?» и получите ответы прямо из часто задаваемых вопросов на веб-сайте. На следующем снимке экрана показана тестовая консоль бота Amazon Lex, отвечающая на этот вопрос из часто задаваемых вопросов.

Нам удалось добиться этого, потому что мы просканировали URL-адрес на первом этапе и создали вложения, которые LlamaIndex мог использовать для поиска ответа на наш вопрос. Функция Lambda нашего бота показывает, как этот поиск выполняется всякий раз, когда возвращается резервное намерение:
Это решение хорошо работает, когда на одной веб-странице есть все ответы. Однако большинство сайтов с часто задаваемыми вопросами не построены на одной странице. Например, в нашем примере с Zappos, если мы зададим вопрос «Есть ли у вас политика сопоставления цен?», мы получим менее чем удовлетворительный ответ, как показано на следующем снимке экрана.
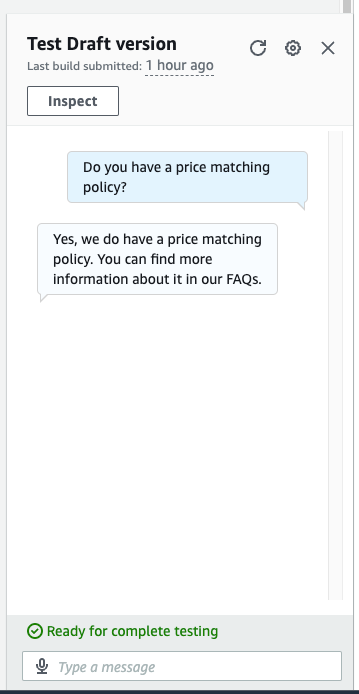
В предыдущем диалоге ответ о правилах сопоставления цен бесполезен для нашего пользователя. Этот ответ короткий, потому что ссылка на часто задаваемые вопросы является ссылкой на конкретную страницу о политике сопоставления цен, а наше веб-сканирование было только для одной страницы. Чтобы получить более качественные ответы, необходимо также сканировать эти ссылки. В следующем разделе показано, как получить ответы на вопросы, требующие двух или более уровней глубины страницы.
Сканирование N-уровня
Когда мы сканируем веб-страницу в поисках часто задаваемых вопросов, нужная нам информация может содержаться на связанных страницах. Например, в нашем примере с Zappos мы задаем вопрос «Есть ли у вас политика соответствия цен?» и ответ: «Да, пожалуйста, посетите <ссылка>, чтобы узнать больше». Если кто-то спросит: «Какова ваша политика соответствия цен?» тогда мы хотим дать полный ответ с политикой. Достижение этого означает, что нам необходимо пройти по ссылкам, чтобы получить актуальную информацию для нашего конечного пользователя. В процессе загрузки мы можем использовать наш веб-загрузчик, чтобы найти якорные ссылки на другие HTML-страницы, а затем пройти по ним. Следующее изменение кода нашего поискового робота позволяет нам находить ссылки на страницах, которые мы сканируем. Он также включает дополнительную логику, позволяющую избежать циклического сканирования и разрешить фильтрацию по префиксу.
В приведенном выше коде мы вводим возможность сканирования N уровней в глубину и даем префикс, который позволяет ограничить сканирование только теми объектами, которые начинаются с определенного шаблона URL. В нашем примере Zappos все страницы обслуживания клиентов происходят из zappos.com/c, поэтому мы включаем его в качестве префикса, чтобы ограничить наше сканирование меньшим и более релевантным подмножеством. Код показывает, как мы можем принимать до двух уровней в глубину. Логика Lambda нашего бота осталась прежней, потому что ничего не изменилось, за исключением того, что краулер загружает больше документов.
Теперь у нас есть все документы, проиндексированные, и мы можем задать более подробный вопрос. На следующем снимке экрана наш бот дает правильный ответ на вопрос «Есть ли у вас политика сопоставления цен?»

Теперь у нас есть полный ответ на наш вопрос о сопоставлении цен. Вместо того, чтобы просто сказать «Да, смотрите нашу политику», он предоставляет нам детали сканирования второго уровня.
Очистить
Чтобы избежать будущих расходов, продолжите удаление всех ресурсов, которые были развернуты в рамках этого упражнения. Мы предоставили сценарий для корректного закрытия конечной точки Sagemaker. Подробности использования в README. Кроме того, чтобы удалить все другие ресурсы, которые вы можете запустить cdk destroy в том же каталоге, что и другие команды cdk, чтобы отменить все ресурсы в вашем стеке.
Заключение
Возможность загрузить набор часто задаваемых вопросов в чат-бот позволяет вашим клиентам находить ответы на свои вопросы с помощью простых запросов на естественном языке. Объединив встроенную в Amazon Lex поддержку резервной обработки с решением RAG, таким как LlamaIndex, мы можем предоставить нашим клиентам быстрый способ получить удовлетворительные, проверенные и утвержденные ответы на часто задаваемые вопросы. Применяя сканирование N-уровня в нашем решении, мы можем разрешить ответы, которые могут охватывать несколько ссылок на часто задаваемые вопросы, и предоставить более подробные ответы на запросы наших клиентов. Следуя этим шагам, вы сможете беспрепятственно интегрировать мощные возможности вопросов и ответов на основе LLM и эффективный прием URL-адресов в чат-бота Amazon Lex. Это приводит к более точному, всестороннему и контекстно-зависимому взаимодействию с пользователями.
Об авторах
 Макс Хенкель-Уоллес работает инженером по разработке программного обеспечения в AWS Lex. Ему нравится работать, используя технологии для максимального успеха клиентов. Вне работы он страстно любит готовить, проводить время с друзьями и ходить в походы.
Макс Хенкель-Уоллес работает инженером по разработке программного обеспечения в AWS Lex. Ему нравится работать, используя технологии для максимального успеха клиентов. Вне работы он страстно любит готовить, проводить время с друзьями и ходить в походы.
 Сун Фэн — старший научный сотрудник AWS AI Labs, специализирующийся на обработке естественного языка и искусственном интеллекте. В ее исследованиях рассматриваются различные аспекты этих областей, включая моделирование диалогов на основе документов, обоснование диалогов, ориентированных на задачи, и интерактивную генерацию текста с использованием мультимодальных данных.
Сун Фэн — старший научный сотрудник AWS AI Labs, специализирующийся на обработке естественного языка и искусственном интеллекте. В ее исследованиях рассматриваются различные аспекты этих областей, включая моделирование диалогов на основе документов, обоснование диалогов, ориентированных на задачи, и интерактивную генерацию текста с использованием мультимодальных данных.
 Джон Бейкер является руководителем SDE в AWS, где он работает над обработкой естественного языка, большими языковыми моделями и другими проектами, связанными с ML/AI. Он работает в Amazon более 9 лет и работал с AWS, Alexa и Amazon.com. В свободное время Джон любит кататься на лыжах и заниматься другими видами активного отдыха на северо-западе Тихого океана.
Джон Бейкер является руководителем SDE в AWS, где он работает над обработкой естественного языка, большими языковыми моделями и другими проектами, связанными с ML/AI. Он работает в Amazon более 9 лет и работал с AWS, Alexa и Amazon.com. В свободное время Джон любит кататься на лыжах и заниматься другими видами активного отдыха на северо-западе Тихого океана.