
Люди — интерактивный вид. Мы взаимодействуем с физическим миром и друг с другом. Чтобы искусственный интеллект (ИИ) был в целом полезным, он должен уметь взаимодействовать с людьми и их средой. В этой работе мы представляем Мультимодальный Интерактивный Агент (МИА), который сочетает в себе визуальное восприятие, понимание и производство языка, навигацию и манипулирование, чтобы участвовать в расширенных и часто неожиданных физических и языковых взаимодействиях с людьми.

Мы опираемся на подход, предложенный Abramson et al. (2020), в котором для обучения агентов в основном используется имитационное обучение. После обучения MIA демонстрирует некоторое рудиментарное интеллектуальное поведение, которое мы надеемся позже улучшить, используя обратную связь от человека. Эта работа сосредоточена на создании этого интеллектуального поведенческого априора, и мы оставляем дальнейшее обучение на основе обратной связи для будущей работы.
Мы создали среду Playhouse, трехмерную виртуальную среду, состоящую из рандомизированного набора комнат и большого количества бытовых объектов, с которыми можно взаимодействовать, чтобы обеспечить пространство и обстановку для совместного взаимодействия людей и агентов. Люди и агенты могут взаимодействовать в Playhouse, управляя виртуальными роботами, которые передвигаются, манипулируют объектами и общаются с помощью текста. Эта виртуальная среда допускает широкий спектр ситуативных диалогов, начиная от простых инструкций (например, «Пожалуйста, возьмите книгу с пола и поставьте ее на синюю книжную полку») до творческой игры (например, «Принесите еду на стол, чтобы мы можем есть»).
Мы собрали человеческие примеры взаимодействия Playhouse с использованием языковых игр, набора сигналов, побуждающих людей импровизировать определенные действия. В языковой игре один игрок (установщик) получает предварительно написанную подсказку, указывающую тип задачи, которую нужно предложить другому игроку (решателю). Например, сеттер может получить подсказку «Задайте другому игроку вопрос о существовании объекта», а после некоторого исследования сеттер может спросить: «Пожалуйста, скажите мне, есть ли в комнате синяя утка, которая также не иметь никакой мебели». Чтобы обеспечить достаточное поведенческое разнообразие, мы также включили подсказки в свободной форме, которые предоставили сеттерам свободу выбора для импровизации взаимодействий (например, «Теперь возьмите любой предмет, который вам нравится, и ударьте по теннисному мячу со стула, чтобы он катится рядом с часами или где-то рядом с ними.”). В общей сложности мы собрали 2,94 года человеческих взаимодействий в реальном времени в Playhouse.
.jpg)
Наша стратегия обучения представляет собой комбинацию контролируемого предсказания действий человека (поведенческого клонирования) и обучения с самоконтролем. При прогнозировании действий человека мы обнаружили, что использование стратегии иерархического управления значительно повышает производительность агентов. В этом случае агент получает новые наблюдения примерно 4 раза в секунду. Для каждого наблюдения он создает последовательность действий движения без обратной связи и, необязательно, выдает последовательность языковых действий. В дополнение к поведенческому клонированию мы используем форму обучения с самоконтролем, которая ставит перед агентами задачу классифицировать, относятся ли определенные зрительные и языковые входные данные к одному и тому же или к разным эпизодам.
Чтобы оценить производительность агентов, мы попросили участников-людей взаимодействовать с агентами и предоставлять бинарную обратную связь, указывающую, успешно ли агент выполнил инструкцию. MIA достигает более 70% успеха в онлайн-взаимодействиях, оцениваемых людьми, что составляет 75% успеха, которого достигают сами люди, когда они играют в качестве решателей. Чтобы лучше понять роль различных компонентов в MIA, мы выполнили серию абляции, удалив, например, визуальные или языковые входные данные, потерю самоконтроля или иерархический контроль.
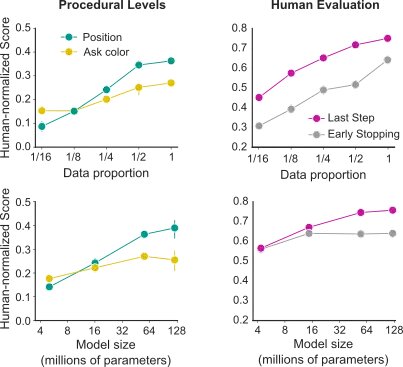
Современные исследования в области машинного обучения выявили замечательные закономерности производительности в отношении различных параметров масштаба; в частности, производительность модели масштабируется по степенному закону в зависимости от размера набора данных, размера модели и вычислительных ресурсов. Эти эффекты были наиболее четко отмечены в языковой области, которая характеризуется огромными размерами наборов данных и высокоразвитыми архитектурами и протоколами обучения. Однако в этой работе мы находимся в совершенно другом режиме — со сравнительно небольшими наборами данных и мультимодальными, многозадачными целевыми функциями, обучающими гетерогенные архитектуры. Тем не менее, мы демонстрируем четкие эффекты масштабирования: по мере увеличения набора данных и размера модели производительность заметно возрастает.
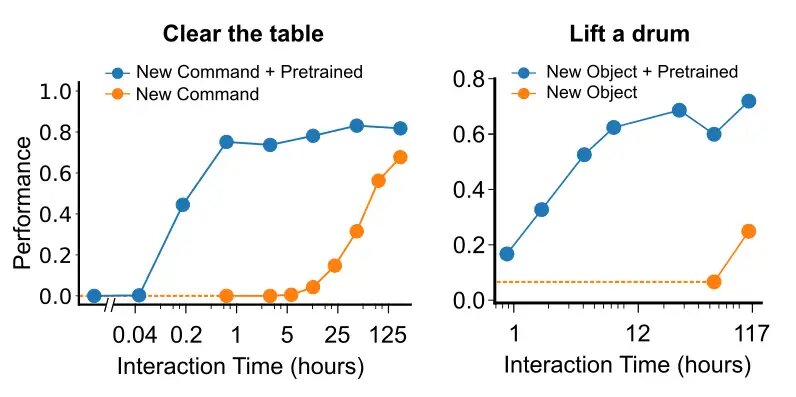
В идеальном случае обучение становится более эффективным при достаточно большом наборе данных, поскольку знания передаются между опытами. Чтобы выяснить, насколько идеальны наши обстоятельства, мы изучили, сколько данных необходимо, чтобы научиться взаимодействовать с новым, ранее невиданным объектом и научиться выполнять новую, ранее неслыханную команду/глагол. Мы разделили наши данные на фоновые данные и данные, включающие языковые инструкции, относящиеся к объекту или глаголу. Когда мы повторно ввели данные, относящиеся к новому объекту, мы обнаружили, что менее 12 часов человеческого взаимодействия было достаточно для достижения максимальной производительности. Аналогичным образом, когда мы ввели новую команду или глагол «очистить» (т. е. убрать все объекты с поверхности), мы обнаружили, что всего 1 часа демонстрации человеком было достаточно, чтобы достичь максимальной производительности в задачах, связанных с этим словом.
MIA демонстрирует поразительно богатое поведение, в том числе разнообразие поведения, которое не было заранее продумано исследователями, включая уборку комнаты, поиск нескольких определенных объектов и задавание уточняющих вопросов, когда инструкция неоднозначна. Эти взаимодействия постоянно вдохновляют нас. Однако открытость поведения МВД создает огромные проблемы для количественной оценки. Разработка комплексных методологий для захвата и анализа открытого поведения при взаимодействии человека с агентом станет важным направлением нашей будущей работы.
Более подробное описание нашей работы см. бумага.