
Привязка языка к зрению является фундаментальной проблемой для многих реальных систем искусственного интеллекта, таких как извлечение изображений или создание описаний для слабовидящих. Для успешного решения этих задач модели должны связывать различные аспекты языка, такие как объекты и глаголы, с изображениями. Например, чтобы различать два изображения в средней колонке ниже, модели должны различать глаголы «ловить» и «пинать». Понимание глаголов особенно сложно, так как оно требует не только распознавания объектов, но и того, как разные объекты на изображении соотносятся друг с другом. Чтобы преодолеть эту трудность, мы представляем набор данных SVO-Probes и используем его для исследования языковых и зрительных моделей для понимания глаголов.

В частности, мы рассматриваем модели мультимодальных трансформеров (например, Lu et al., 2019; Chen et al., 2020; Tan and Bansal, 2019; Li et al., 2020), которые продемонстрировали успех на различных языках и видениях. задания. Однако, несмотря на высокую производительность в тестах, неясно, обладают ли эти модели детальным мультимодальным пониманием. В частности, предыдущая работа показывает, что модели языка и зрения могут преуспеть в тестах без мультимодального понимания: например, ответы на вопросы об изображениях, основанные только на языковых априорных состояниях (Agrawal et al., 2018) или «галлюцинирующие» объекты, которых нет на изображении. при подписи к изображениям (Rohrbach et al., 2018). Чтобы предвидеть ограничения модели, работайте, как Shekhar et al. предлагать специализированные оценки для систематического исследования моделей на предмет понимания языка. Однако предыдущие наборы зондов ограничены по количеству объектов и глаголов. Мы разработали SVO-зонды, чтобы лучше оценить потенциальные ограничения в понимании глаголов в текущих моделях.
SVO-Probes включает 48 000 пар изображений и предложений и проверяет понимание более 400 глаголов. Каждое предложение можно разбить на триплет
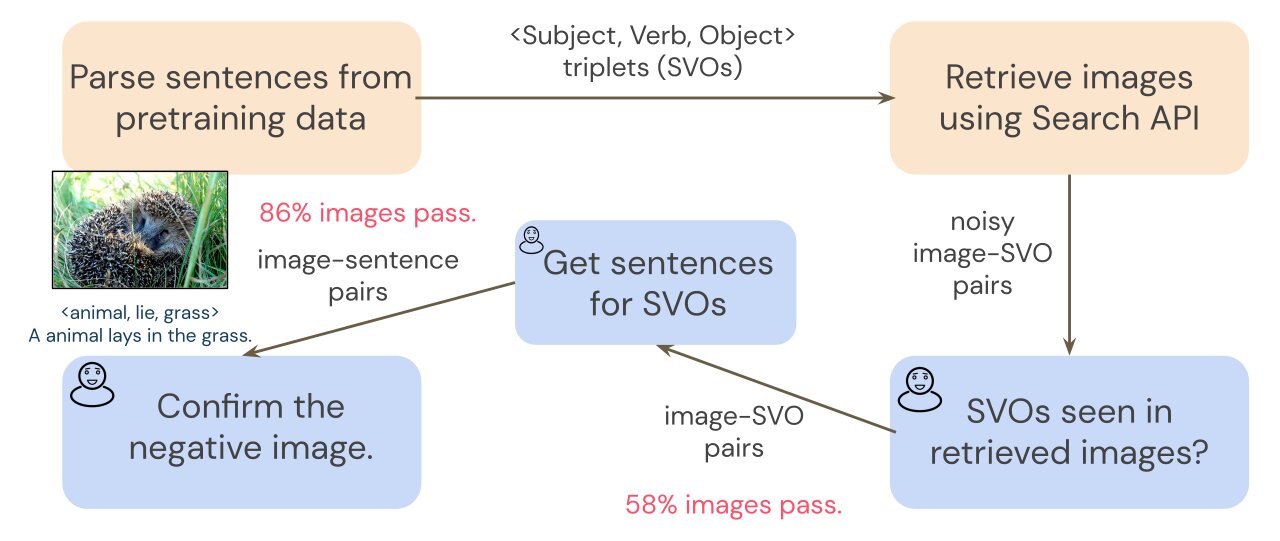
Для создания SVO-зондов мы запросить поиск изображения с триплетами SVO из общего набора обучающих данных, Conceptual Captions (Sharma et al. 2018). Поскольку поиск изображения может быть зашумлен, предварительный шаг аннотации фильтрует полученные изображения, чтобы гарантировать, что у нас есть чистый набор пар изображение-SVO. Поскольку преобразователи обучаются на парах «изображение-предложение», а не на парах «изображение-SVO», нам нужны пары «изображение-предложение», чтобы исследовать нашу модель. Чтобы собрать предложения, описывающие каждое изображение, аннотаторы пишут короткое предложение для каждого изображения, которое включает триплет SVO. Например, учитывая триплет SVO <животное, ложь, трава>, комментатор может написать предложение «Животное лежит в траве». Затем мы используем аннотации SVO, чтобы соединить каждое предложение с негативным изображением, и просим аннотаторов проверить негативы на последнем этапе аннотации. Подробности см. на рисунке ниже.
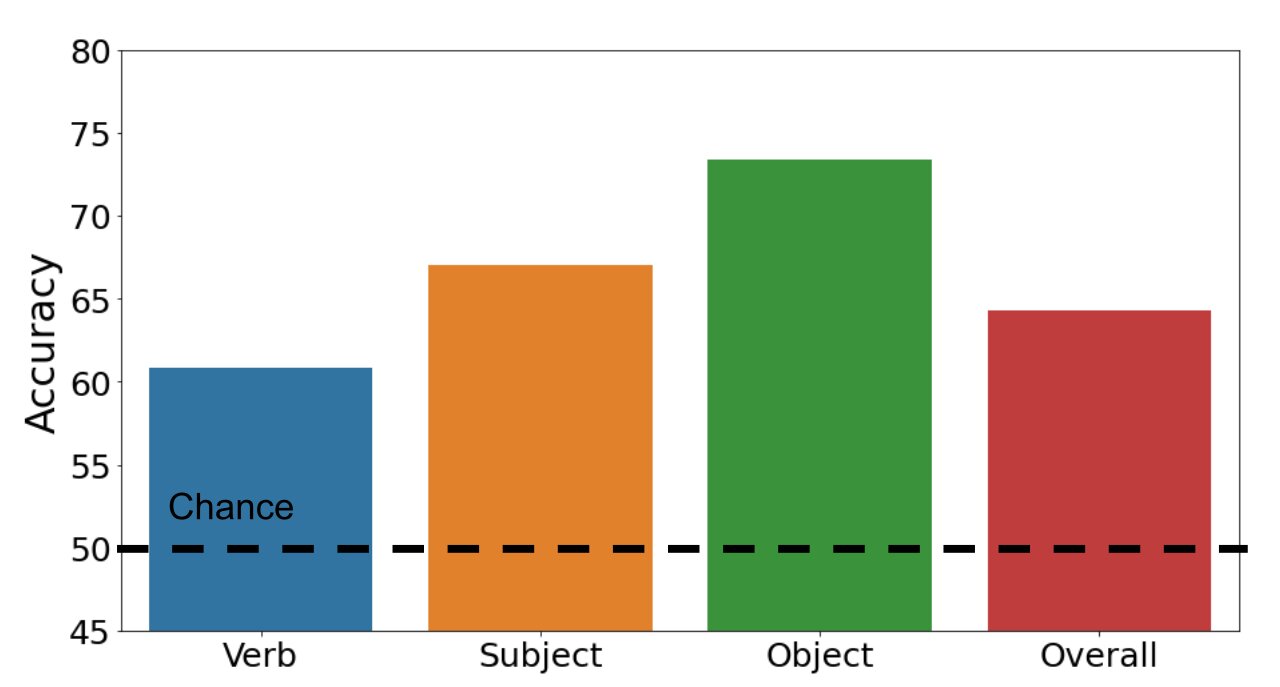
Мы исследуем, могут ли мультимодальные преобразователи точно классифицировать примеры как положительные или отрицательные. Гистограмма ниже иллюстрирует наши результаты. Наш набор данных является сложным: наша стандартная модель мультимодального трансформатора достигает общей точности 64,3% (вероятность 50%). В то время как точность составляет 67,0% и 73,4% для предметов и объектов соответственно, производительность падает до 60,8% для глаголов. Этот результат показывает, что распознавание глаголов действительно сложно для моделей зрения и языка.
Мы также изучаем, какие архитектуры моделей лучше всего работают в нашем наборе данных. Удивительно, но модели с более слабым моделированием изображения работают лучше, чем стандартная модель-трансформер. Одна из гипотез состоит в том, что наша стандартная модель (с более сильными возможностями моделирования изображений) превосходит набор поездов. Поскольку обе эти модели хуже работают с другими языковыми и визуальными задачами, наша целевая тестовая задача выявляет слабые места модели, которые не наблюдаются в других тестах.
В целом мы обнаружили, что, несмотря на впечатляющую производительность в тестах, мультимодальные преобразователи по-прежнему борются с детальным пониманием, особенно с точным пониманием глаголов. Мы надеемся, что SVO-Probes может помочь в изучении понимания глаголов в моделях языка и зрения и вдохновить на создание более целевых наборов данных зондов.
Посетите наши SVO-зонды ориентир и модели на GitHub: тест и модели.