Этот пост написан в соавторстве с Чун Минг Чин, руководителем технической программы, и Максом Казнади, старшим специалистом по данным, Microsoft, а также с Луи Хуаном, Николасом Као и Джеймсом Тайали, студентами Калифорнийского университета в Беркли..
Эта запись в блоге посвящена проекту виртуального наставника Калифорнийского университета в Беркли и технологиям распознавания речи, которые были протестированы в рамках этого проекта. Мы делимся передовым опытом в области методов машинного обучения и искусственного интеллекта при выборе моделей и инженерных обучающих данных для распознавания речи и изображений. Эти модели распознавания речи, интегрированные с иммерсивными играми, в настоящее время проходят испытания в средних школах Калифорнии.
Контекст
В Калифорнийском университете в Беркли есть новая программа, основанная выпускником и филантропом Коулманом Фангом. Братство Фунг. В рамках этой программы учащиеся разрабатывают технологические решения для решения образовательных задач, таких как предоставление детям из малообеспеченных семей возможности помочь себе в обучении. Решение включает в себя создание виртуального репетитора, который слушает, что говорят дети, и взаимодействует с ними, играя в обучающие игры. Игры были разработаны основанной Коулманом технологической компанией по имени Синий годжи. Эта работа ведется совместно с Партнерство для более здоровой Америкинекоммерческая организация, возглавляемая Мишель Обамой.
GoWings Safari, образовательная игра на тему сафари, в которой есть виртуальный репетитор, взаимодействующий с пользователем.
Один из студентов, работающих над проектом, — выпускник Калифорнийского университета в Беркли в первом поколении из Малави по имени Джеймс Тайали. Джеймс сказал: «Эта сафари-игра важна для детей, которые растут в среде, которая подвергает их детским травмам и другим негативным переживаниям. Таким детям трудно обращать внимание и преуспевать в учебе. Сочетание образовательного опыта с интерактивными, захватывающими играми может улучшить их обучение. фокус.”
Как сирота из Малави, который изо всех сил пытался сосредоточиться в школе, это область, с которой Джеймс может иметь отношение. Джеймсу приходилось совмещать семейные проблемы и подрабатывать, чтобы прокормить себя. Несмотря на скромное начало, Джеймс усердно работал и учился в Калифорнийском университете в Беркли при стипендиальной поддержке MasterCard Foundation. Теперь он отдает их следующему поколению детей. «Этот проект может помочь детям, которые рассказывают такие же истории, как и я, помогая им отпустить свой прошлый травмирующий опыт, сосредоточиться на своем нынешнем образовании и дать им надежду на свое будущее», — добавил Джеймс.

Джеймс Тайали (слева), выпускник основного курса общественного здравоохранения Калифорнийского университета в Беркли 2017 года, и Коулман
Фунг (справа) позирует с изображением сафари на экране монитора.
Программу стипендий вел Чун Минг, менеджер программы поиска и искусственного интеллекта Microsoft, который также является выпускником Калифорнийского университета в Беркли. Он также консультировал команду, разработавшую Virtual Tutor, в которую входят Джеймс Тайали, специализирующийся в области общественного здравоохранения и работавший дизайнером продукта; Луйи Хуан, студент электротехники и компьютерных наук (EECS), руководивший задачами по программированию; и Николас Као, студент прикладной математики и науки о данных, руководивший сбором и анализом данных. Большая часть этой работы выполнялась удаленно в трех местах — Редмонде, штат Вашингтон, Беркли, Калифорния, и Остине, штат Техас.

Студенты стипендии UC Berkeley Fung Luyi Huang (слева) и Николас Као (справа).

Чун Мин читает лекции по распознаванию речи и искусственному интеллекту для студентов Калифорнийского университета в Беркли.
Выводы из проекта «Виртуальный репетитор»
В этой статье представлены технические идеи команды в нескольких областях:
- Стратегия выбора модели и инженерные соображения для возможного развертывания в реальных условиях, чтобы другие, кто занимается чем-то подобным, могли с большей уверенностью инвестировать в модель заранее, которая с самого начала соответствует их сценарию.
- Обучение методам обработки данных, которые являются полезными ссылками не только для распознавания речи, но и для других сценариев, таких как распознавание изображений.
Выбор модели — выбор модели распознавания речи
Мы изучили технологии распознавания речи, разработанные Университетом Карнеги-Меллона (CMU), Google, Amazon и Microsoft, и в итоге остановились на следующих вариантах:
1. Служба распознавания речи Bing
Платная служба распознавания речи Microsoft Bing показала точность 100%, хотя для получения результатов с удаленных серверов Bing потребовалось 4 секунды. Хотя точность впечатляет, у нас не было возможности адаптировать эту модель черного ящика к другим акцентам речи и фоновому шуму. Одним из возможных обходных путей является обработка вывода из черного ящика (т. е. постобработка).
2. Статистическая модель CMU с открытым исходным кодом
Мы также изучили другие бесплатные и более быстрые модели распознавания речи, доступ к которым осуществляется локально, а не через удаленный сервер. В конце концов, мы выбрали статистическую модель с открытым исходным кодом Sphinx, которая имела начальную точность 85% и уменьшила задержку с 4 секунд Bing Speech API до 3 секунд. В отличие от решения Bing «черный ящик», мы можем заглянуть внутрь модели, чтобы повысить точность. Например, мы можем уменьшить пространство поиска слов, необходимых для поиска в словаре, или адаптировать модель с большим количеством данных для обучения речи. Sphinx имеет 30-летнее наследие, первоначально разработанное исследователями CMU, которые по совпадению сейчас работают в Microsoft Research (MSR). Среди них Сюэдун Хуан, технический сотрудник Microsoft, Фил Аллева, менеджер по исследованиям партнеров, и Сяо-Вуэн Хон, корпоративный вице-президент. Президент MSR Asia.
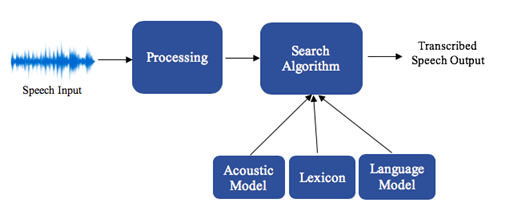
Предопределенные человеческие черты и лингвистическая структура в модели распознавания речи CMU с открытым исходным кодом.
3. Модель глубокого обучения Azure
Студенты также были связаны с базирующейся в Бостоне командой Microsoft Azure в центре исследований и разработок Новой Англии (NERD). Имея доступ к работе NERD над продуктом Azure AI, известным как Блокнот виртуальной машины Data Science, студенты стипендии достигли точности распознавания речи Virtual Tutor 91,9%. Более того, среднее время выполнения модели одинаково и составляет 0,5 секунды на входной речевой файл между моделями NERD и CMU. Дополнительный прототип модели глубокого обучения был разработан NERD на основе победившего решения задачи «Обнаружение и классификация акустических сцен и событий» (DCASE) 2017 года. Эта модель может еще больше повысить точность классификации и масштабироваться до больших наборов обучающих данных.
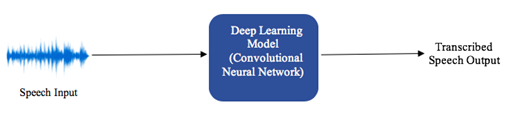
Функции машинного обучения с моделью глубокого обучения Azure.
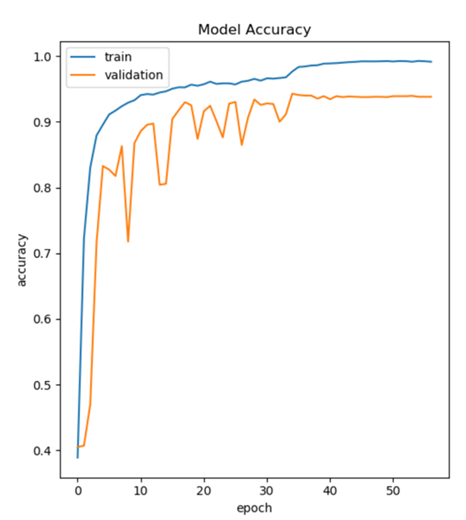
График точности модели NERD по оси Y в зависимости от количества проходов через полный
тренировочные данные (т.е. эпохи) на оси x. Окончательная точность, оцененная на наборе измерений, составляет 91,9%.
Инжиниринг данных обучения
Отсутствие аудиоданных для обучения было препятствием для максимального использования потенциала модели глубокого обучения. Дополнительные обучающие данные всегда могут улучшить модель распознавания речи CMU.
1. Решить проблемы несоответствия данных обучения и тестирования
Мы загрузили синтетические аудиофайлы динамиков из общедоступной сети и собрали аудиофайлы от добровольцев Калифорнийского университета в Беркли с частотой дискретизации 16 кГц. Первоначально мы заметили, что большее количество обучающих данных не повышает точность теста на микрофоне Oculus. Эта проблема возникла из-за несоответствия частоты дискретизации между обучающими данными (16 кГц) и входом микрофона Oculus (48 кГц). После того, как ввод был подвергнут понижающей дискретизации, улучшенный режим Sphinx имел лучшую точность.
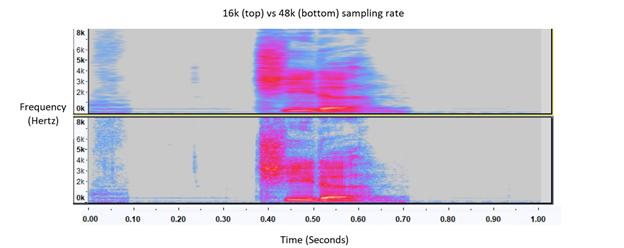
Визуальное представление спектра звуковых частот, меняющихся со временем (т.е. спектрограмма), сравнение дискретизации 16 кГц (вверху) и 48 кГц (внизу). Обратите внимание, что нижняя дискретизированная спектрограмма с частотой 48 кГц имеет более высокое разрешение.
2. Синтетический звук динамика
Предвзятость данных из-за пола и акцента говорящего должна быть уравновешена за счет повышения качества и количества обучающих данных. Чтобы решить эту проблему, мы импортировали синтезированные аудиосэмплы мужского и женского пола из таких переводчиков, как Bing. Мы могли бы обучить нашу модель, используя эти новые синтезированные звуковые образцы в сочетании с нашими текущими данными. Однако мы обнаружили, что в синтезированном звуке отсутствуют естественные зигзагообразные вариации человеческого голоса. Он был «слишком чистым», чтобы точно передать естественный человеческий голос вживую.
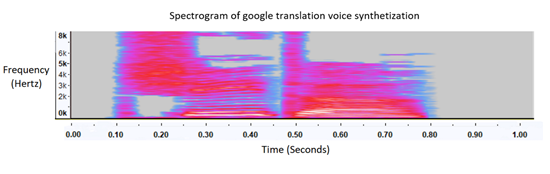
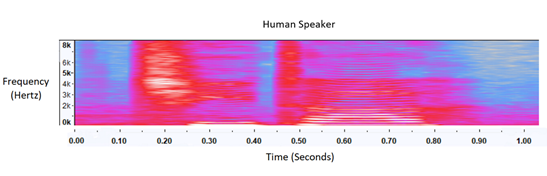
Сравнение спектрограмм синтезированного голоса (вверху) и голоса человека (внизу)
3. Сочетание фонового шума и сигнала динамика
Еще одна проблема заключается в том, что существуют различные громкие фоновые шумы, которые микрофон Oculus не может автоматически подавить. Это мешает модели отличать фоновый шум от сигнала динамика. Чтобы решить эту проблему, мы объединили аудиосэмпл с несколькими фоновыми шумами.
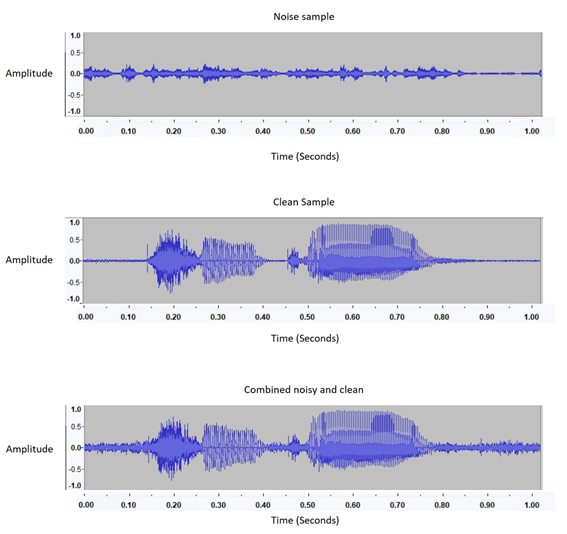
Ось Y «Амплитуда» представляет собой нормализованную шкалу дБ (где -1 означает отсутствие сигнала).
+1 — самый сильный сигнал), представляющий громкость звука.
Это предоставило большое количество аудиосэмплов и позволило нам настроить модель в соответствии с живой средой виртуального репетитора. С помощью дополнительных синтезированных образцов мы обучили более точную модель, как показано в матрице путаницы ниже. В этой матрице показаны тестовые примеры, в которых модель запутана из-за несоответствия между столбцом прогнозируемого класса и строкой истинности. Правильные предсказания показаны вдоль диагональной линии матрицы. Матрица путаницы — хороший способ визуализировать, какие классы требуют целенаправленных улучшений обучающих данных.
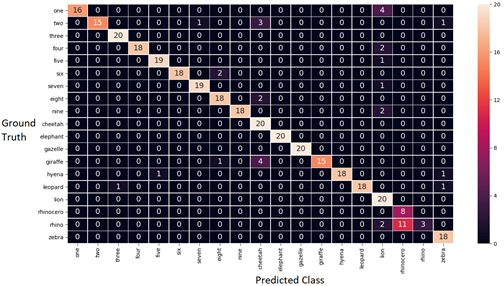
Матрица путаницы перед объединением фонового шума и сигнала динамика в качестве новых обучающих данных для модели Sphinx CMU. Точность модели составляет 93%.
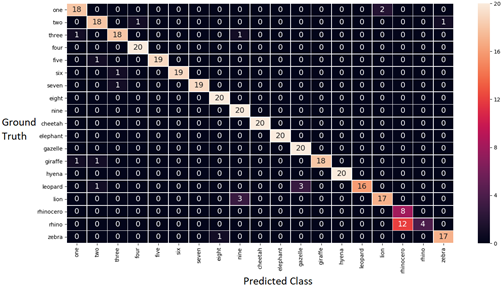
Матрица путаницы после объединения фонового шума и сигнала динамика в качестве новых обучающих данных для модели Sphinx CMU. Точность модели составляет 96%.
Синтезированный шум имел некоторые проблемы. Мы обнаружили несколько выбросов, когда наложили (по шкале времени) чистый сигнал и синтезированный шум без каких-либо корректировок сигнала. Эти выбросы произошли из-за того, что шум был более заметным, чем сигнал динамика.
4. Оптимизация отношения сигнал/шум
Чтобы компенсировать указанную выше проблему, мы скорректировали относительные соотношения уровней в децибелах (дБ) между двумя наложенными аудиофайлами. Используя среднеквадратичное значение (RMS) для оценки уровней дБ каждого аудиофайла, мы смогли подавить шумный звук, позволив голосу говорящего иметь приоритет при обучении и прогнозировании. С помощью серии тестов мы определили, что средний уровень шума в дБ составляет около 70% от среднего уровня нашего чистого звука в дБ. Это позволяет нам поддерживать точность 95% при тестировании на избыточном наборе для обучения и тестирования. Все, что выше 80%, снижает точность с возрастающей скоростью.
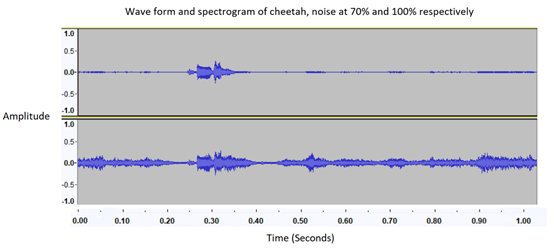
График формы волны, показывающий шум при 70% (вверху) и 100% (внизу). Ось Y «Амплитуда» представляет собой нормализованную
Шкала дБ (где -1 — отсутствие сигнала и +1 — самый сильный сигнал), представляющая громкость звука.
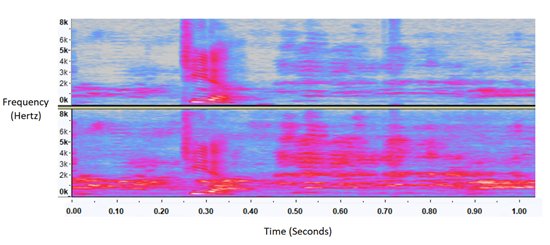
График спектрограммы, показывающий шум при 70% (вверху) и 100% (внизу).
Обратите внимание, что нижний шум при 100% имеет больше синих и розовых областей.
Краткое содержание
История проекта виртуального репетитора Калифорнийского университета в Беркли началась осенью 2016 года. Сначала мы протестировали различные технологии распознавания речи, а затем изучили ряд методов обработки обучающих данных. В настоящее время наши модели распознавания речи интегрированы в игру и тестируются в средних школах Калифорнии.
Тем из вас, кто хочет добавить возможности распознавания речи в свои проекты, следует рассмотреть следующие варианты, основанные на наших выводах:
- Для простоты интеграции и высокой точности попробуйте Речевой API Bing. Он позволяет использовать 5000 бесплатных транзакций в месяц.
- Для более быстрого сквозного времени отклика и возможности настройки модели для повышения точности для конкретных сред попробуйте Статистическая модель CMU Sphinx.
- Для сценариев, в которых у вас есть доступ к большому количеству обучающих данных (например, более 100 000 строк обучающих примеров), Модель глубокого обучения Azure может быть лучшим вариантом как для скорости, так и для точности.
Чун Мин, Макс, Луи, Ник и Джеймс