
Многие недавние успехи в языковых моделях (LM) были достигнуты в рамках «статической парадигмы», где основное внимание уделяется повышению производительности эталонных тестов, которые создаются без учета временного аспекта данных. Например, отвечая на вопросы о событиях, о которых модель может узнать во время обучения, или оценивая текст, выбранный из того же периода, что и обучающие данные. Однако наш язык и знания динамичны и постоянно развиваются. Поэтому, чтобы обеспечить более реалистичную оценку моделей вопросов и ответов для следующего скачка производительности, важно обеспечить их гибкость и надежность при столкновении с новыми и невидимыми данными.
В 2021 году мы выпустили Помните о разрыве: оценка временного обобщения в моделях нейронного языка и эталонные тесты динамического языкового моделирования для WMT и arXiv, чтобы облегчить оценку языковой модели с учетом временной динамики. В этой статье мы выделили проблемы, с которыми сталкиваются современные современные крупные LM с временным обобщением, и обнаружили, что токены с интенсивным знанием значительно снижают производительность.
Сегодня мы публикуем две статьи и новый эталонный тест, которые продвигают вперед исследования по этой теме. В StreamingQA: эталон адаптации к новым знаниям с течением времени в моделях ответов на вопросымы изучаем последующую задачу ответов на вопросы на нашем недавно предложенном тесте, StreamingQA: мы хотим понять, как параметрические и полупараметрические модели ответов на вопросы, дополненные поиском, адаптируются к новой информации, чтобы отвечать на вопросы о новых событиях. В Интернет-дополненные языковые модели с помощью нескольких подсказок для ответов на вопросы с открытым доменом, мы изучаем возможности сочетания большой языковой модели с несколькими запросами и поиска Google в качестве компонента поиска. При этом мы стремимся повысить достоверность модели, обеспечив при этом доступ к актуальной информации для ответов на широкий набор вопросов.
StreamingQA: эталон адаптации к новым знаниям с течением времени в моделях ответов на вопросы
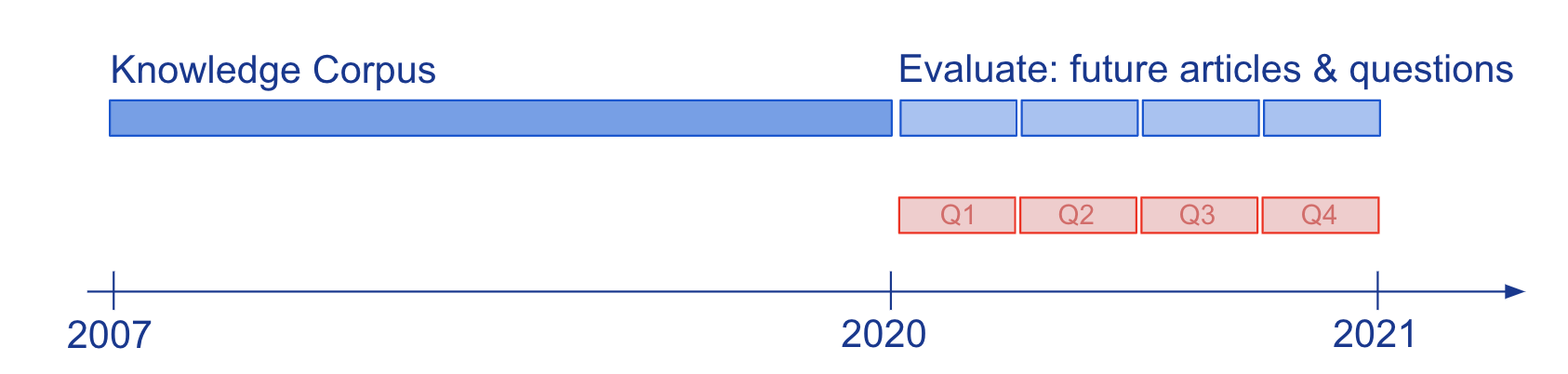
Знание и понимание языка моделей, оцениваемых с помощью вопросов-ответов (QA), обычно изучались на статических снимках знаний, таких как Википедия. Чтобы изучить, как полупараметрические модели обеспечения качества и лежащие в их основе параметрические LM адаптируются к развивающимся знаниям, мы создали новый крупномасштабный тест StreamingQA с написанными людьми и автоматически сгенерированными вопросами, заданными в определенную дату, на которые нужно ответить в течение 14 лет. новостные статьи с отметками времени (см. рис. 2). Мы показываем, что параметрические модели можно обновлять без полного переобучения, избегая при этом катастрофического забывания. Для полупараметрических моделей добавление новых статей в пространство поиска позволяет быстро адаптироваться, однако модели с устаревшим базовым LM уступают моделям с переобученным LM.

Интернет-дополненные языковые модели с помощью нескольких подсказок для ответов на вопросы в открытой области
Мы стремимся извлечь выгоду из уникальных возможностей, предлагаемых крупномасштабными языковыми моделями, для преодоления некоторых из их проблем, связанных с опорой на фактическую и актуальную информацию. Вдохновленные полупараметрическими LM, которые основывают свои решения на внешнем свидетельстве, мы используем несколько подсказок, чтобы научиться обусловливать LM на информации, возвращенной из Интернета с помощью Google Search, обширного и постоянно обновляемого источника знаний. Наш подход не требует тонкой настройки или изучения дополнительных параметров, что делает его применимым практически к любой языковой модели. И действительно, мы обнаруживаем, что LM, обусловленные в Интернете, превосходят по производительности закрытые модели аналогичного или даже большего размера модели в открытых вопросах-ответах.