
Недавний Бумага DeepMind по этическим и социальным рискам языковых моделей выявлены большие языковые модели утечка конфиденциальной информации об их обучающих данных как о потенциальном риске, который должны устранить организации, работающие над этими моделями. Другой недавняя статья показывает, что аналогичные риски конфиденциальности могут также возникать в стандартных моделях классификации изображений: отпечаток каждого отдельного тренировочного изображения может быть найден встроенным в параметры модели, и злоумышленники могут использовать такие отпечатки пальцев для восстановления обучающих данных из модели.
Технологии повышения конфиденциальности, такие как дифференциальная конфиденциальность (DP), могут быть развернуты во время обучения, чтобы снизить эти риски, но они часто приводят к значительному снижению производительности модели. В этой работе мы добились существенного прогресса в разблокировке высокоточного обучения моделей классификации изображений в условиях дифференциальной конфиденциальности.

Дифференциальная конфиденциальность была предложенный в качестве математической основы для отражения требования защиты отдельных записей в ходе статистического анализа данных (включая обучение моделей машинного обучения). Алгоритмы DP защищают людей от любых выводов об особенностях, которые делают их уникальными (включая полную или частичную реконструкцию), вводя тщательно откалиброванный шум во время вычисления желаемой статистики или модели. Использование алгоритмов DP обеспечивает надежные и строгие гарантии конфиденциальности как в теории, так и на практике и стало де-факто золотым стандартом, принятым рядом общественный и частный организации.
Наиболее популярным алгоритмом DP для глубокого обучения является дифференциально частный стохастический градиентный спуск (DP-SGD), модификация стандартного SGD, полученная путем отсечения градиентов отдельных примеров и добавления достаточного количества шума, чтобы замаскировать вклад любого человека в каждое обновление модели:
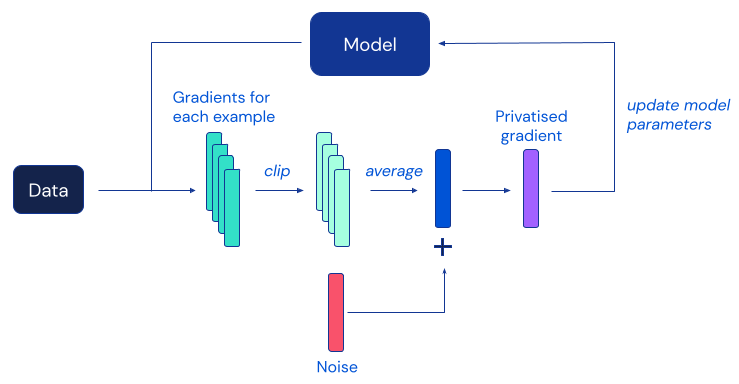
К сожалению, предыдущие работы показали, что на практике защита конфиденциальности, обеспечиваемая DP-SGD, часто достигается за счет значительно менее точных моделей, что представляет собой серьезное препятствие для широкого внедрения дифференциальной конфиденциальности в сообществе машинного обучения. Согласно эмпирическим данным из предыдущих работ, эта деградация полезности в DP-SGD становится более серьезной на более крупных моделях нейронных сетей, включая те, которые регулярно используются для достижения наилучшей производительности в сложных тестах классификации изображений.
Наша работа исследует это явление и предлагает ряд простых модификаций как процедуры обучения, так и архитектуры модели, что приводит к значительному повышению точности обучения DP на стандартных эталонных тестах классификации изображений. Самое поразительное наблюдение, сделанное в результате нашего исследования, заключается в том, что DP-SGD можно использовать для эффективного обучения гораздо более глубоких моделей, чем считалось ранее, если обеспечить правильное поведение градиентов модели. Мы считаем, что значительный скачок в производительности, достигнутый в результате нашего исследования, может открыть возможности практического применения моделей классификации изображений, обученных с формальными гарантиями конфиденциальности.
На рисунке ниже представлены два наших основных результата: улучшение CIFAR-10 на ~10 % по сравнению с предыдущей работой при частном обучении без дополнительных данных и первая точность 86,7 % на ImageNet при частной точной настройке модели перед обучался на другом наборе данных, почти сократив отставание от лучших не-частных показателей.

Эти результаты достигаются при 𝜺=8, стандартном параметре для калибровки силы защиты, обеспечиваемой дифференциальной конфиденциальностью в приложениях машинного обучения. Мы ссылаемся на статью для обсуждения этого параметра, а также дополнительных экспериментальных результатов при других значениях 𝜺, а также на других наборах данных. Вместе с документом мы также открываем исходный код нашей реализации, чтобы другие исследователи могли проверить наши выводы и опираться на них. Мы надеемся, что этот вклад поможет другим, заинтересованным в практическом обучении DP.
Загрузите нашу реализацию JAX на GitHub.